




Análisis estadístico: Significación e Intervalos de Confianza
En cualquier análisis estadístico, es probable que trabaje con una muestra, en lugar de con datos de toda la población. Por lo tanto, su resultado puede no representar a toda la población, y podría ser muy inexacto si su muestreo no fue muy bueno.
Por lo tanto, necesita una forma de medir la certeza de que su resultado es exacto, y no ha ocurrido simplemente por casualidad. Para ello, los estadísticos utilizan dos conceptos relacionados: la confianza y la significación.
Esta página explica estos conceptos.
Significación estadística
El término significación tiene un significado muy particular en estadística. Le indica la probabilidad de que su resultado no se haya producido por casualidad.

En el diagrama, el círculo azul representa a toda la población. Cuando tomas una muestra, ésta puede ser de toda la población. Sin embargo, es más probable que sea más pequeña. Si toda la muestra procede del círculo amarillo, habrás cubierto una gran parte de la población. Sin embargo, también podría tener mala suerte (o haber diseñado mal el procedimiento de muestreo) y tomar la muestra sólo dentro del pequeño círculo rojo. Esto tendría serias implicaciones en cuanto a si su muestra es representativa de toda la población.
Una de las mejores maneras de asegurarse de que cubre más de la población es utilizar una muestra más grande. El tamaño de la muestra afecta en gran medida a la precisión de los resultados (y hay más información al respecto en nuestra página sobre Muestreo y diseño de la muestra).
Sin embargo, hay otro elemento que también afecta a la precisión: la variación dentro de la propia población. Puede evaluar esto mirando las medidas de la dispersión de sus datos (y para más información sobre esto, consulte nuestra página sobre Análisis estadístico simple). Cuando hay más variación, hay más posibilidades de que elija una muestra que no sea típica.
El concepto de significación simplemente reúne el tamaño de la muestra y la variación de la población, y hace una evaluación numérica de las posibilidades de que haya cometido un error de muestreo: es decir, que su muestra no represente a su población.
La significación se expresa como una probabilidad de que sus resultados se hayan producido por casualidad, comúnmente conocida como valor p. Por lo general, se busca que sea inferior a un valor determinado, normalmente 0,05 (5%) o 0,01 (1%), aunque algunos resultados también informan de 0,10 (10%).
Hipótesis nula y alternativa
Cuando se lleva a cabo un experimento o un estudio de mercado, por lo general se quiere saber si lo que se está haciendo tiene un efecto. Por lo tanto, puede expresarlo como una hipótesis:
-x tendrá un efecto sobre y.
Esto se conoce en estadística como «hipótesis alternativa», a menudo llamada H1.
La «hipótesis nula», o H0, es que x no tiene ningún efecto sobre y.
En términos estadísticos, el propósito de las pruebas de significación es ver si sus resultados sugieren que necesita rechazar la hipótesis nula, en cuyo caso, es más probable que la hipótesis alternativa sea cierta.
Si sus resultados no son significativos, no puede rechazar la hipótesis nula, y tiene que concluir que no hay ningún efecto.
El valor p es la probabilidad de que haya obtenido los resultados que ha obtenido si su hipótesis nula es verdadera.
Calcular la significación
Una forma de calcular la significación es utilizar una puntuación z. Esto describe la distancia de un punto de datos a la media, en términos del número de desviaciones estándar (para más información sobre la media y la desviación estándar, consulte nuestra página sobre Análisis estadístico simple).
Para una comparación simple, la puntuación z se calcula utilizando la fórmula:
$$z=frac{x – \mu}{\sigma}$$
donde \(x\) es el punto de datos, \(\mu\) es la media de la población o distribución, y \(\sigma\) es la desviación estándar.
Por ejemplo, supongamos que deseamos comprobar si una aplicación de juegos es más popular que otras. Digamos que la media de las aplicaciones de juegos se descarga 1000 veces, con una desviación estándar de 110. Nuestro juego se ha descargado 1200 veces. Su puntuación z es:
$$z=\frac{1200-1000}{110}=1,81$$
Una puntuación z más alta indica que es menos probable que el resultado se haya producido por casualidad.
Puede utilizar una tabla estadística z estándar para convertir su puntuación z en un valor p. Si el valor p es inferior al nivel de significación deseado, entonces los resultados son significativos.
Usando la tabla z, la puntuación z de nuestra aplicación de juego (1,81) se convierte en un valor p de 0,9649. Esto es mejor que nuestro nivel deseado del 5% (0,05) (porque 1-0,9649 = 0,0351, o 3,5%), por lo que podemos decir que este resultado es significativo.
Nótese que hay una ligera diferencia para una muestra de una población, donde la puntuación z se calcula utilizando la fórmula:
$$z=\frac{(x-\mu)}{(\sigma/\sqrt n)}$$
donde x es el punto de datos (normalmente la media de su muestra), µ es la media de la población o distribución, σ es la desviación estándar, y √n es la raíz cuadrada del tamaño de la muestra.
Un ejemplo lo hará más claro.
Suponga que está comprobando si los estudiantes de biología tienden a obtener mejores notas que sus compañeros que estudian otras materias. Podría encontrar que la nota media de los exámenes de una muestra de 40 biólogos es de 80, con una desviación estándar de 5, en comparación con los 78 de todos los estudiantes de esa universidad o escuela.
$$z=\frac{(80-78)}{(5/cuadrado 40)}=2,53$$
Usando la tabla z, 2,53 corresponde a un valor p de 0,9943. Se puede restar esto de 1 para obtener 0,0054. Esto es inferior al 1%, por lo que podemos decir que este resultado es significativo al nivel del 1%, y que los biólogos obtienen mejores resultados en los exámenes que la media de los estudiantes de esta universidad.
Nótese que esto no significa necesariamente que los biólogos sean más inteligentes o mejores para aprobar los exámenes que los que estudian otras materias. De hecho, podría significar que los exámenes de biología son más fáciles que los de otras asignaturas. Encontrar un resultado significativo NO es una prueba de causalidad, pero sí le indica que puede haber un problema que desee examinar.
Hay más información sobre las pruebas de significación de las medias muestrales, y las pruebas de las diferencias entre grupos, en nuestra página sobre Desarrollo y prueba de hipótesis.
Intervalos de confianza
Un intervalo de confianza (o nivel de confianza) es un rango de valores que tiene una probabilidad determinada de que el valor verdadero se encuentre dentro de él.
Efectivamente, mide el grado de confianza en que la media de su muestra (la media de la muestra) es la misma que la media de la población total de la que se tomó la muestra (la media de la población).
Por ejemplo, si su media es 12,4, y su intervalo de confianza del 95% es 10,3-15,6, esto significa que usted está seguro al 95% de que el verdadero valor de su media de la población se encuentra entre 10,3 y 15,6. En otras palabras, puede que no sea 12,4, pero estás razonablemente seguro de que no es muy diferente.
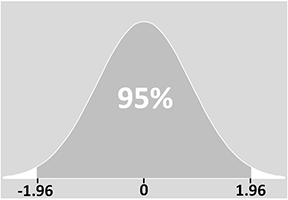
El diagrama siguiente muestra esto en la práctica para una variable que sigue una distribución normal (para más información sobre esto, consulta nuestra página sobre Distribuciones estadísticas).

El significado preciso de un intervalo de confianza es que si hicieras tu experimento muchas, muchas veces, el 95% de los intervalos que construyeras a partir de estos experimentos contendrían el valor verdadero. En otras palabras, en el 5% de sus experimentos, su intervalo NO contendría el valor verdadero.
Puede ver en el diagrama que hay un 5% de posibilidades de que el intervalo de confianza no incluya la media de la población (las dos «colas» del 2,5% a cada lado). En otras palabras, en una de cada 20 muestras o experimentos, el valor que obtenemos para el intervalo de confianza no incluirá la verdadera media: la media de la población caerá realmente fuera del intervalo de confianza.
Cálculo del intervalo de confianza
El cálculo de un intervalo de confianza utiliza los valores de su muestra, y algunas medidas estándar (media y desviación estándar) (y para más información sobre cómo calcularlas, consulte nuestra página sobre Análisis estadístico simple).
Es más fácil de entender con un ejemplo.
Supongamos que tomamos una muestra de la altura de un grupo de 40 personas y encontramos que la media es de 159,1 cm, y la desviación estándar es de 25,4.
Desviación estándar para los intervalos de confianza
En principio, se utilizaría la desviación estándar de la población para calcular el intervalo de confianza. Sin embargo, es muy poco probable que usted sepa cuál es ésta.
Afortunadamente, puede utilizar la desviación estándar de la muestra, siempre que tenga una muestra lo suficientemente grande. El punto de corte suele ser un tamaño de muestra de 30 o más, pero cuanto más grande, mejor.
Necesitamos averiguar si nuestra media es una estimación razonable de las alturas de todas las personas, o si hemos elegido una muestra particularmente alta (o baja).
Utilizamos una fórmula para calcular un intervalo de confianza. Ésta es:
$$mean \pm z \frac{(SD)}{sqrt n}$$
Donde SD = desviación estándar, y n es el número de observaciones o el tamaño de la muestra.
El valor z se toma de las tablas estadísticas para nuestra distribución de referencia elegida. Estas tablas proporcionan el valor z para un intervalo de confianza concreto (por ejemplo, el 95% o el 99%).
En este caso, estamos midiendo las alturas de las personas, y sabemos que las alturas de la población siguen una distribución normal (a grandes rasgos) (para obtener más información sobre esto, consulte nuestra página sobre Distribuciones estadísticas).Por lo tanto, podemos utilizar los valores para una distribución normal.
El valor de z para un intervalo de confianza del 95% es 1,96 para la distribución normal (tomado de las tablas estadísticas estándar).
Usando la fórmula anterior, el intervalo de confianza del 95% es, por tanto:
$$159,1 \pm 1,96 \frac{(25,4)}{sqrt 40}$$
Cuando realizamos este cálculo, encontramos que el intervalo de confianza es de 151,23-166,97 cm. Por lo tanto, es razonable decir que tenemos un 95% de confianza en que la media de la población se encuentra dentro de este intervalo.
Entendiendo la puntuación z o el valor z
La puntuación z es una medida de las desviaciones estándar de la media. En nuestro ejemplo, por lo tanto, sabemos que el 95% de los valores caerán dentro de ± 1,96 desviaciones estándar de la media:
Evaluando su intervalo de confianza
Como regla general, un intervalo de confianza pequeño es mejor. El intervalo de confianza se reducirá a medida que aumente el tamaño de la muestra, por lo que siempre es preferible una muestra más grande. Como explica nuestra página sobre el muestreo y el diseño de la muestra, su experimento ideal incluiría a toda la población, pero esto no suele ser posible.
Conclusión
Los intervalos de confianza y la significación son formas estándar de mostrar la calidad de sus resultados estadísticos. Se espera que los comunique de forma rutinaria al realizar cualquier análisis estadístico y, por lo general, debe comunicar cifras precisas. Esto garantizará que su investigación sea válida y fiable.