




¿Cuál es la mejor liga?
Este trabajo es de autoría conjunta con Madeline Gall.
Mientras que el scouting para algunos deportes es sencillo (fútbol universitario → NFL), el scouting para la NHL puede ser un proceso más arduo. Con jugadores de más de 45 ligas internacionales de hockey sobre hielo, cada una con sus propias normas y dificultades, ¿cómo se puede evaluar adecuadamente la calidad del rendimiento de un jugador? No es fácil hacer comparaciones entre ligas; no se debe atribuir el mismo valor a 18 puntos de un joven de dieciocho años que juega contra otros jóvenes de dieciocho años en una liga menor que a 18 puntos de un joven de dieciocho años que juega contra veteranos en la NHL.
Ha habido otros intentos de tener en cuenta esto, incluyendo las variables de traducción de los jugadores, como la de los factores de traducción de hockey de Rob Vollman, y la NHL Equivalency Ratings (NHLe) de Gabriel Desjardin. El NHLe de Desjardin ya abordó el tema de la comparación y la predicción del rendimiento de los jugadores en las transiciones de la Liga a la NHL (pasar de otra liga a la NHL). Era estupendo para una comparación rápida y general y ciertamente tiene sus ventajas (fácil y rápido de calcular), pero hay algunos inconvenientes en su método. Para empezar, no controla necesariamente la calidad del equipo, la posición y la edad. Los factores de conversión se calculan utilizando las estadísticas de los jugadores que han jugado al menos 20 partidos en la liga en cuestión antes de jugar al menos 20 en la NHL. Eso significa que hay muchos datos valiosos sobre estas transiciones intermedias que no se están utilizando.
En este proyecto, introducimos un nuevo método para comparar y proyectar el rendimiento de los jugadores a través de las ligas utilizando una métrica de puntuación z ajustada que tendría en cuenta estos inconvenientes. Esta métrica controla factores como la edad, la liga, la temporada y la posición que afectan a la métrica P/PG de un jugador, y podría aplicarse a cualquier liga de interés. Esta nueva métrica es necesaria ya que hay muchas características que varían de una liga a otra. Debido a los diferentes estilos de juego y a la dificultad de los oponentes, no existe una métrica consistente para hacer evaluaciones comparables del rendimiento de los jugadores en las ligas de hockey de todo el mundo. Otros factores, como la fuerza de los porteros, los porcentajes de penalización y las dimensiones de las pistas, también son inconsistentes entre las ligas internacionales. Podrían darse escenarios en los que jugadores de fuerza similar podrían parecer tener rendimientos aparentemente diferentes.
Un ejemplo de esto sería Thomas Harley y Ville Heinola del draft más reciente de 2019. Ambos son jugadores de diferentes ligas que juegan contra diferentes oponentes y obtienen números muy diferentes, y sin embargo fueron valorados como aproximadamente iguales. Harley, un defensa nacido en Estados Unidos que juega en la liga juvenil de hockey sobre hielo de Canadá, juega actualmente con los Mississauga Steelheads en la Liga de Hockey de Ontario. Fue reclutado en el puesto 18 por los Dallas Stars en la primera ronda del Entry Draft de la NHL de 2019. Heinola por su parte es un defensa profesional finlandés de hockey sobre hielo que actualmente juega en el Lukko de la Liiga cedido como prospecto de los Winnipeg Jets de la National Hockey League. Fue clasificado como uno de los mejores patinadores internacionales elegibles para el Entry Draft de la NHL 2019. Heinola fue drafteado en el puesto 20 de la general por los Jets. ¿Cómo fueron evaluados estos dos jugadores por sus respectivos equipos? Probablemente con algo similar a nuestra métrica además de la información de scouting.
Para nuestra métrica, nos inspiramos no sólo en los enfoques anteriores como la NHLe, sino también en el reciente auge de Elo. Elo es un método para calcular los niveles relativos de habilidad de los jugadores en juegos de suma cero. Aunque inicialmente se creó en el contexto de la medición de las calificaciones de los jugadores de ajedrez, Elo puede aplicarse también en otros escenarios, como los deportes profesionales. Para leer más y ver ejemplos de Elo en los deportes, se puede encontrar un tutorial de 538 aquí. Elo es simplemente un modelo específico de comparación por parejas. Para empezar, utilizamos un conjunto de datos que contenía alrededor de 300.000 observaciones de la información del jugador (nombre, posición, liga, cumpleaños, etc.) y las estadísticas del jugador (partidos jugados, goles, asistencias, etc.) que estaban disponibles, extraídas de eliteprospects.com. Uno de los primeros problemas con los que nos encontramos fue qué tipo de variable de respuesta podríamos crear para comparar las estadísticas de los jugadores, controlando la edad, la fuerza de la liga, la posición, etc. El rendimiento de los jugadores se ha calculado ampliamente en la NHL; hay varias medidas como WAR, GAR, Corsi, etc. Sin embargo, la recopilación de datos no es igual en todas las ligas. Algunas ligas no fueron tan proactivas en el seguimiento de estadísticas como golpes y bloqueos como otras, lo que significó que sólo pudimos utilizar variables que eran omnipresentes en todas las ligas como factores dentro de nuestra regresión.
Cuando creamos la nueva variable de respuesta, queríamos transformar los puntos por partido de una manera que tuviera en cuenta la edad, la temporada, la posición y la liga. El primer paso fue tomar el logaritmo de los puntos por partido más uno. Esta transformación tenía una distribución más normal, mientras que los puntos por partido en bruto estaban muy sesgados hacia la derecha. Aunque la transformación logarítmica ayudó a que los datos parecieran tener una distribución más normal, el logaritmo de puntos por partido seguía sin tener en cuenta las variables mencionadas anteriormente. Decidimos que, para tener en cuenta estas variables, íbamos a crear una puntuación z para los puntos logarítmicos por partido de cada jugador. El primer paso fue calcular la media y la desviación estándar para cada grupo de posición, temporada, liga y edad. A continuación, se calculó una puntuación z para cada observación del jugador utilizando la media y la desviación estándar correspondientes a las variables que estábamos controlando. Así, la puntuación z del logaritmo de puntos por partido más uno fue nuestra variable de respuesta final. Las puntuaciones z parecían tener una distribución aún más normal que el logaritmo de puntos por partido, y las puntuaciones z de grupos como los defensores y los delanteros también tenían una distribución normal.
Crear el modelo de comparación por pares, que es muy similar a un modelo Elo. Para empezar, construimos un marco de datos de comparación. Creamos pares de temporadas jugador-liga para cada jugador, de modo que hay un pequeño marco de datos de todas las comparaciones por pares para las ligas en las que han jugado. Esto significa que si un jugador ha jugado en K ligas, entonces ese jugador tendrá K-elegidos-2 pares de temporadas jugador-liga. A continuación, eliminamos cualquier par que tenga la misma liga, así como los pares que estén separados por más de una temporada, y calculamos una variable de resultado. Esta variable puede ser continua o binaria, dependiendo de la regresión utilizada. Es importante entender que la liga «más difícil» de jugar tendría en realidad una variable de resultado más baja. Esto se basa en la suposición de que las ligas más difíciles tienen mejores defensas y porteros, lo que hace más difícil marcar.
| Nombre del jugador | Liga | Temporada | Puntuación Z |
|---|---|---|---|
| Kris Letang | QMJHL | 2006-07 | 1.829 |
| Kris Letang | NHL | 2006-07 | 1.158 |
| Kris Letang | AHL | 2007-08 | 1.557 |
| Liga 1 | Temporada 1 | Puntuación Z 1 | Liga 2 | Temporada 2 | Puntuación Z-Puntuación 2 | Diferencia de puntuación Z |
|---|---|---|---|---|---|---|
| QMJHL | 2006-07 | 1.829 | NHL | 2006-07 | 1.158 | 0.671 |
| NHL | 2006-07 | 1.158 | AHL | 2007-08 | 1.557 | -0.399 |
| QMJHL | 2006-07 | 1,829 | AHL | 2007-08 | 1,557 | 0.272 |
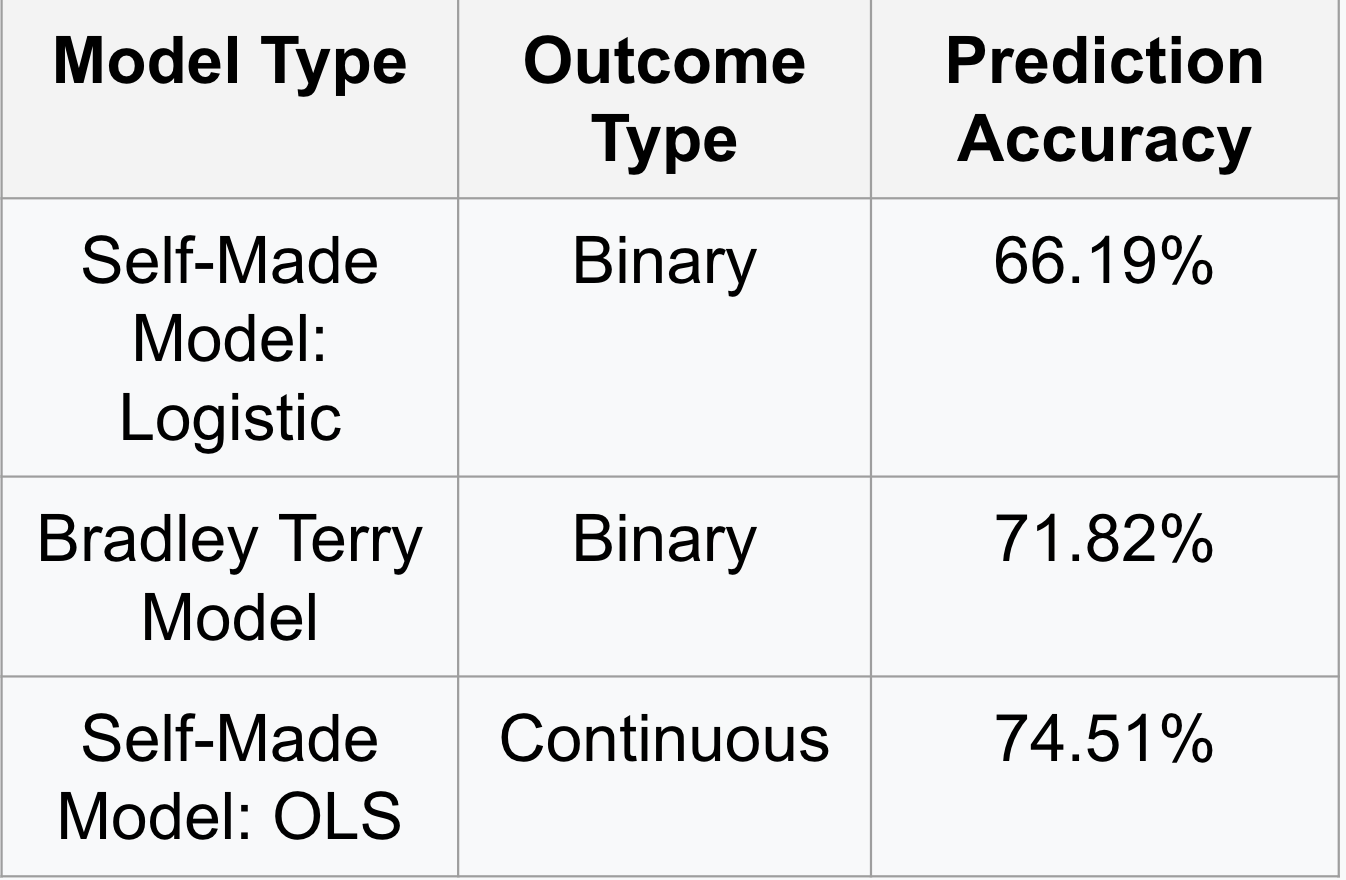
Después de construir el modelo de comparación pareada, se utilizaron diferentes tipos de regresiones para calcular los coeficientes. Nos centramos en el uso de un modelo logístico propio, el modelo de Bradley Terry (utilizando el paquete BTm en R), ambos crearon resultados binarios, así como una regresión de mínimos cuadrados ordinarios, que creó un resultado continuo. Para evaluar qué regresión funcionaba para crear los resultados más precisos, primero dividimos los datos emparejados 70/30 para las muestras de entrenamiento y de prueba. A continuación, predijimos la probabilidad de victoria para todas las ligas, basándonos en la puntuación Z ajustada por partido. Se estableció un umbral para «ganar»; si la probabilidad era mayor que el umbral, el resultado previsto era = 1. De lo contrario, era = 0. De lo contrario, era = 0. A partir de ahí, los resultados predichos se compararon con los resultados reales para calcular la precisión de la predicción de cada modelo. Los resultados se muestran en la siguiente tabla.
Una vez creados nuestros diferentes métodos de modelización, pudimos utilizar los coeficientes de fuerza de los modelos para crear una clasificación de ligas determinada por su fuerza. No fue una sorpresa que para cada año desde 2008 hasta 2018, y para los coeficientes de fuerza general que la Liga Nacional de Hockey se considera la liga más fuerte. La otra liga que fue considerada consistentemente como la segunda mejor fue el Campeonato Mundial, lo cual tiene sentido ya que se trata de los mejores jugadores de diferentes países compitiendo, y este torneo consiste en muchos jugadores que juegan en la NHL. Si nos fijamos en las ligas, la AHL, la KHL, la SHL y la DEL fueron sistemáticamente algunas de las ligas más fuertes de más de 45 equipos. La clasificación final de las 10 mejores ligas fue la NHL, el Campeonato Mundial, el Campeonato Mundial Juvenil, la KHL, la SHL, la AHL, la USDP, el Campeonato Mundial Juvenil Sub-18, el DEL y la NLA. Algunas de las ligas que pueden haber sido una sorpresa fueron las ligas de hockey junior, o la USDP. Estas ligas aparecieron más arriba en nuestra clasificación porque tuvimos en cuenta la edad en nuestro modelo. Esto permitió que la fuerza se basara en la calidad de los jugadores y no en su edad. Cada uno de los tres modelos que creamos tenía clasificaciones similares con sólo ligeras desviaciones.
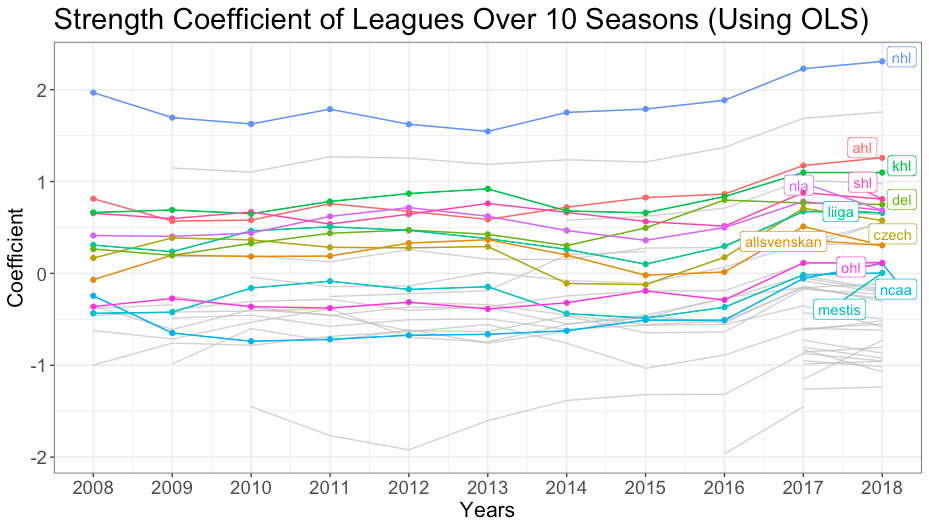
Coeficientes de fuerza a lo largo del tiempo: El gráfico anterior muestra los coeficientes de fuerza de cada liga para cada año desde 2008 hasta 2018. Las ligas más conocidas y las ligas consistentemente fuertes están resaltadas arriba.
Después de generar una clasificación de ligas basada en nuestros puntos por partido ajustados, el siguiente paso fue ver cómo se comparaban estas clasificaciones con el uso de solo puntos por partido. Al utilizar sólo los puntos por partido nos dimos cuenta de que ocurrían tres cosas con los coeficientes de fuerza de las ligas. Para las ligas que tenían un coeficiente de fuerza más alto, esas ligas tendían a seguir siendo las más fuertes en cuanto a puntos por partido ajustados. En el caso de las ligas que se encontraban en el nivel medio de todas las ligas, sus coeficientes de fuerza para los puntos brutos por partido eran muy similares a sus coeficientes de fuerza para los puntos ajustados por partido. Por último, las ligas con los coeficientes de fuerza más bajos para los puntos brutos por partido tenían peores coeficientes de fuerza para los puntos ajustados por partido. Las únicas ligas con coeficientes de fuerza más bajos que tuvieron coeficientes de fuerza mejorados por puntos por partido ajustados fueron las ligas que tenían jugadores jóvenes. Esta tendencia se da en el caso de los Campeonatos Mundiales Juveniles, tanto para los sub20 como para los sub18, y en el caso de la liga de secundaria de Estados Unidos, Minnesota. En el caso de la liga de secundaria de Minnesota, se consideró la peor liga con diferencia cuando se utilizaron los puntos brutos por partido como variable de respuesta, pero al utilizar los puntos ajustados por partido, esta liga obtiene mejores resultados que otras 10 ligas, muchas de las cuales son ligas profesionales. Esto nos permitió ver aún más las fallas con los puntos por juego como un predictor de la fuerza de la liga, y también destacó lo importante que es tener en cuenta la edad al determinar la fuerza de la liga.
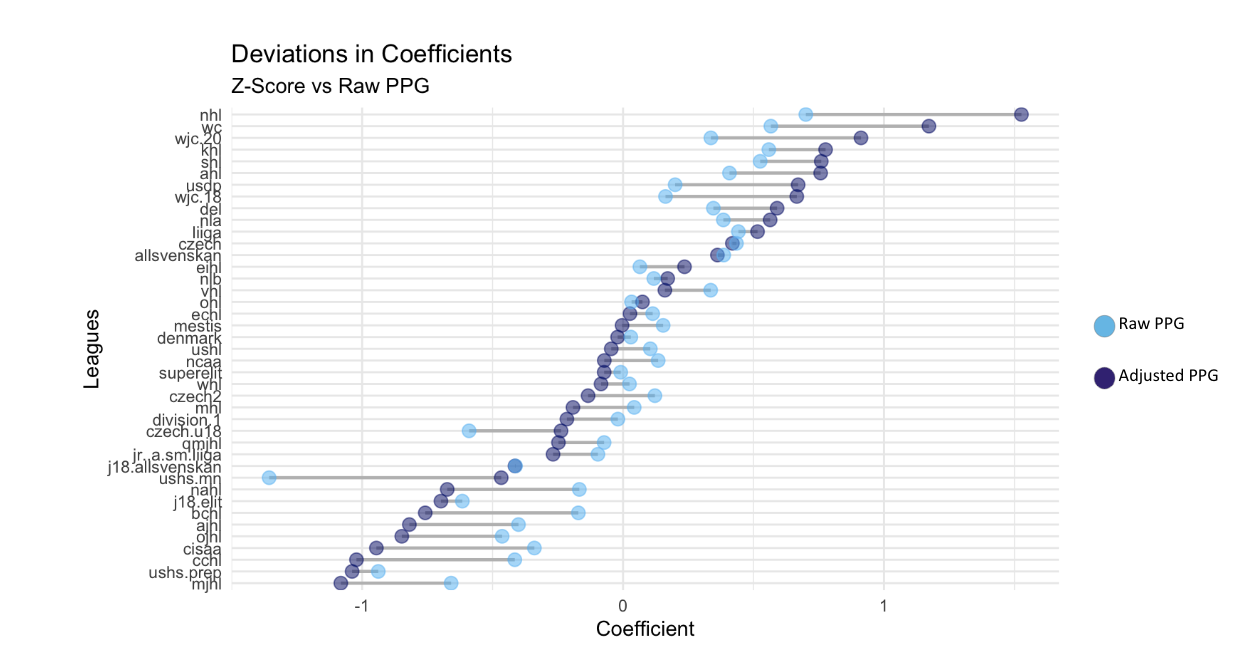
Coeficientes de fuerza para cada liga para P/GP crudo vs P/GP ajustado: Este gráfico muestra los coeficientes de fuerza para cada liga para las dos variables de respuesta diferentes. Los coeficientes de fuerza se calcularon utilizando el mismo método de modelado.
Como se mencionó anteriormente, fue necesario crear una nueva estimación del rendimiento de los jugadores porque los predictores existentes, como los puntos por partido, están sesgados debido a la edad, la fuerza de la liga, la fuerza del equipo y el año. La creación de percentiles para los tipos de jugadores permite comparar un prospecto con otros jugadores similares permitiendo una predicción más precisa. El percentil de log P/GP y nuestro método elegido es muy útil porque permite predecir el rendimiento de cualquier jugador en cualquiera de las más de 45 ligas. Con tantas ligas, no está garantizado que un jugador haya sido drafteado de esa liga a la NHL, pero sin el método del modelo, eso no es necesario para hacer una predicción precisa.
Por ejemplo, los puntos por partido ajustados de Jake Geuntzel en la temporada 2017-2018 para los Pittsburgh Penguins fueron de 0,94. Usando este punto ajustado por partido, podemos predecir sus puntos ajustados por partido en cualquier otra liga. A continuación tenemos algunas de las ligas más comunes mostradas y los puntos ajustados por partido predichos de Jake Guentzel en cada una de esas ligas. A modo de comparación, en 2016-2017 Jake Guentzel tuvo unos puntos ajustados por partido de 2,30 en la AHL. Nuestra predicción de puntos ajustados por partido de 2 está bastante cerca.
Nuestro método para predecir los puntos ajustados por partido de un jugador para determinar cómo puede rendir un jugador en una liga determinada es un simple cálculo a partir de nuestros coeficientes de fuerza en del proceso de modelado descrito anteriormente. Para comparar dos ligas cualesquiera, reste sus coeficientes de fuerza entre sí. A continuación, añade este valor a los puntos ajustados por partido o puntuación z de la liga en la que el jugador ha registrado datos. La suma de la puntuación z y la diferencia del coeficiente de fuerza dará los puntos por partido ajustados para cualquier otra liga.
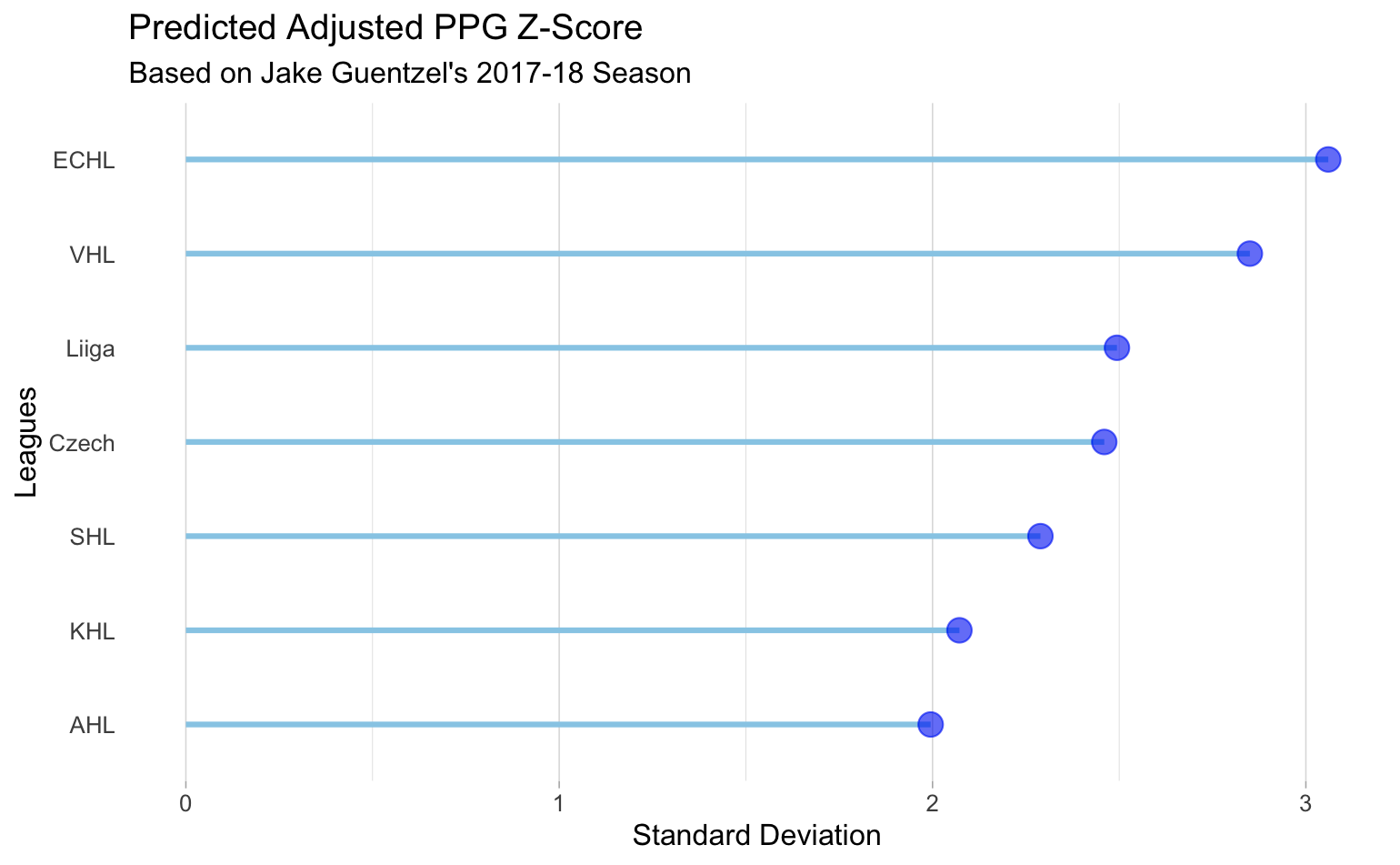
No sólo es útil predecir el rendimiento de un solo jugador para fines de ojeo, sino que los coeficientes de fuerza proporcionan información sobre la fuerza de la liga. Los coeficientes tienen en cuenta la edad, la temporada, la posición y la liga. Esto podría permitir a un ojeador invertir más recursos en una liga juvenil que puede quedar relegada. Esto se debe a que la edad es un gran determinante de los puntos por partido, pero cuando se tienen en cuenta todas las demás variables de confusión, hay algunas ligas juveniles que, en general, tienen una fuerza de liga mucho mejor que algunas ligas profesionales.
Estos conceptos también tienen aplicaciones en la vida real. Durante los meses previos al draft de 2016, se discutió sobre a quién elegirían los Columbus Blue Jackets con la tercera elección global. La mayoría de los ojeadores habían valorado a Jesse Puljujarvi, un delantero finlandés, como la elección de consenso, pero los aficionados se sorprendieron al escuchar que el CBJ eligió a Pierre-Luc Dubois, un pívot canadiense en su lugar. Sin embargo, un rápido vistazo a los números revelará que esta decisión no debería ser una sorpresa. Mientras jugaba en la liga profesional de hockey Liiga, Puljujarvi anotó unos impresionantes 28 puntos en 50 partidos de la temporada regular, y se clasificó como el quinto mejor entre los jugadores de Liiga menores de 20 años. Dubois, por su parte, jugó en una liga de hockey menor, pero sin embargo terminó tercero en la QMJHL con 99 puntos en 62 partidos. Utilizando los coeficientes, podemos calcular su P/GP ajustado en la NHL para comparar, y encontramos que Dubois aventaja a Puljujarvi desde un punto de vista estadístico. Obviamente, esto no sería lo único que los ojeadores tendrían en cuenta a la hora de hacer el draft, el formidable tamaño y el físico de Dubois definitivamente también jugaron un papel en su decisión, pero se podría asumir que los Blue Jackets tenían una mejor imagen de cómo cada jugador se apilaba contra el otro al elegir a Dubois sobre Puljujarvi.
Otra aplicación, además de las comparaciones entre jugadores, serían las comparaciones entre ligas. Volviendo al ejemplo de Harley vs Heinola, podemos evaluar sus respectivas ligas con otras ligas de estatus similar. En lugar de comparar la NHL con la OHL, donde el contraste es evidente, se pueden hacer valoraciones más matizadas comparando la OHL con otras ligas menores norteamericanas. En los gráficos siguientes, podemos ver que la OHL es en realidad la liga más fuerte de las ligas menores norteamericanas, mientras que la Liiga es una liga de rango medio en comparación con otras ligas profesionales.
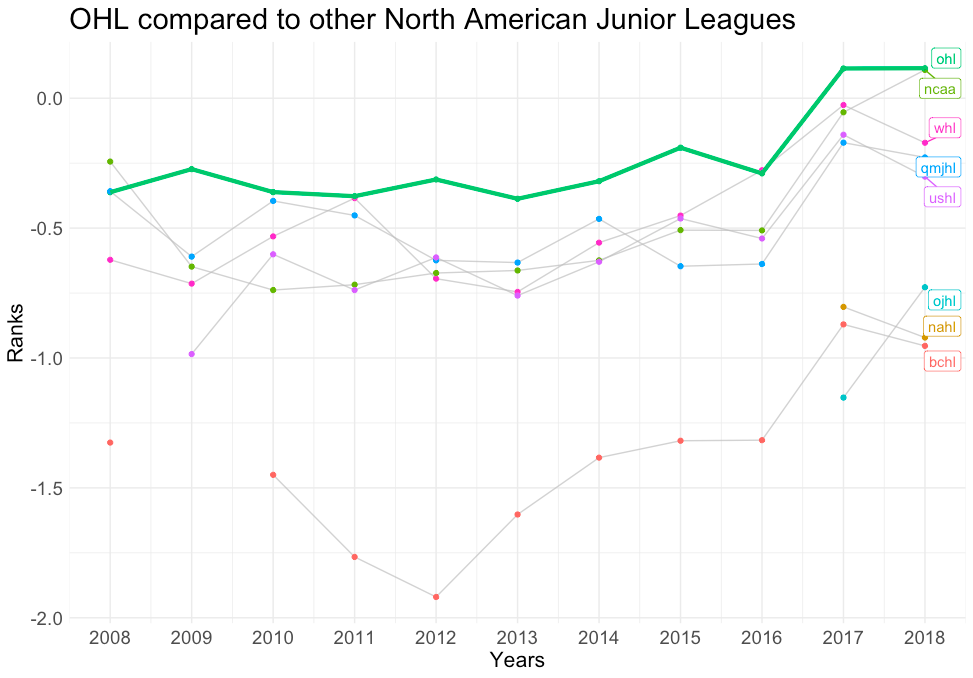
OHL frente a otras ligas menores de NA: Este gráfico muestra los coeficientes de fuerza de todas las ligas junior norteamericanas, con la OHL resaltada en verde.
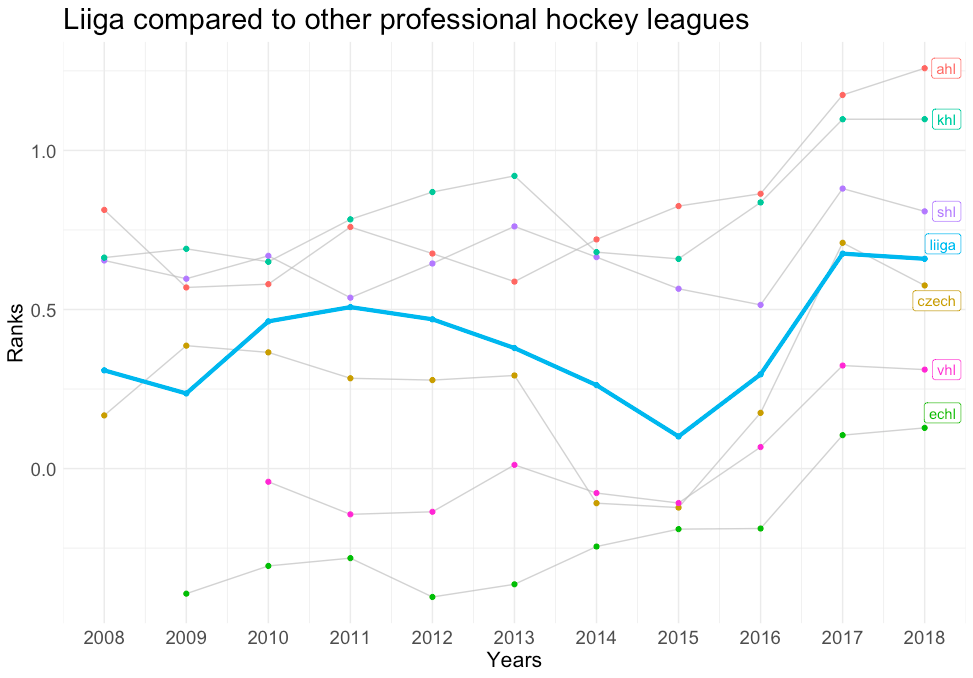
Liiga frente a otras ligas de hockey profesional: Este gráfico muestra los coeficientes de fuerza de todas las ligas profesionales de hockey del mundo, con la Liiga resaltada en azul claro.
Con la métrica ajustada de puntos por partido del jugador, no sólo se controlan las variables de confusión como la edad, la posición, la liga y la temporada de un jugador, que pueden cambiar la perspectiva del valor de cualquier jugador. Las técnicas de modelización utilizadas permiten comparar a los jugadores de las ligas de hockey de todo el mundo, no sólo de las grandes ligas. Esto da a los equipos la posibilidad de predecir el rendimiento de cualquier jugador en su liga en relación con otros jugadores similares, lo que antes se hacía utilizando un estimador sesgado. La métrica de puntos por partido ajustada permite un enfoque más holístico para la evaluación de los jugadores, y proporciona un camino para los jugadores que anteriormente pueden haber sido pasados por alto o al margen. Ya hay muchas aplicaciones simplemente utilizando los puntos por partido ajustados, pero también se pueden utilizar otros tipos de datos, como las clasificaciones de los ojeadores o los goles esperados, etc. Con datos más detallados en el futuro en todas las ligas, este método también puede ser mejorado.
La investigación de este artículo también fue presentada en la CBJHAC20 por Katerina Wu. Puedes encontrar las diapositivas aquí.
¡Síguenos en Twitter @kattaqueue y @madelinejgall!