




Kuinka hyviä ovat mielipidemittaajat? Analysoimalla Five-Thirty-Eightin tietokokonaisuutta
Analysoimme kunnianarvoisen poliittisten ennusteiden verkkosivuston Five-Thirty-Eightin mielipidekyselijöiden ranking-tietokokonaisuutta.

Tämä on vaalivuosi, ja mielipidekyselyt vaalien (sekä yleisten presidentinvaalien että edustajainhuoneen ja senaatin) ympärillä kuumenevat. Tästä tulee tulevina päivinä yhä jännittävämpää twiittien, vastatwiittien, sosiaalisessa mediassa käytävien taistelujen ja television loputtoman puntaroinnin myötä.
Tiedämme, että kaikki mielipidemittaukset eivät ole yhtä laadukkaita. Miten siis saada tolkkua tähän kaikkeen? Miten tunnistaa luotettavat mielipidemittaajat datan ja analytiikan avulla?

Poliittisten (ja joidenkin muidenkin asioiden, kuten urheilun, yhteiskunnallisten ilmiöiden, talouden jne.) ennakoivien analyysien maailmassa Five-Thirty-Eight on vaikuttava nimi.
Sivusto on julkaissut vuoden 2008 alusta lähtien artikkeleita – tyypillisesti tilastotietoa luoden tai analysoiden – monenlaisista ajankohtaisen politiikan ja poliittisten uutisten aiheista. Sivusto, jota pyörittää rocktähti datatieteilijä ja tilastotieteilijä Nate Silver, saavutti erityistä näkyvyyttä ja laajaa mainetta vuoden 2012 presidentinvaalien tienoilla, kun sen malli ennusti oikein kaikkien 50 osavaltion ja District of Columbian voittajan.
Ja ennen kuin pilkkaat ja sanot: ”Mutta entä vuoden 2016 vaalit?”, sinun kannattaa ehkä lukea tämä juttu siitä, miten Donald Trumpin valinta oli tilastollisen mallinnuksen normaalin virhemarginaalin sisällä.
Poliittisesti uteliaammille lukijoille on tarjolla kokonainen pussillinen artikkeleita vuoden 2016 vaaleista täällä.
Datatieteen harjoittajien kannattaa pitää Five-Thirty-Eightista, koska se ei kaihda selittää ennustemallejaan erittäin teknisin termein (ainakin tarpeeksi monimutkaisina maallikolle).

Tässä he puhuvat kuuluisan t-jakauman käyttöönotosta, kun taas useimmat muut gallup-aggregaattorit saattavat tyytyä ubiikkiseen normaalijakaumaan.
Mikäli Silverin johtama tiimi menee hienostuneiden tilastollisten mallinnustekniikoiden käytön ohi, se on ylpeä ainutlaatuisesta metodologiasta – gallup-luokituksesta – joka auttaa heidän mallejaan pysymään erittäin tarkkoina ja luotettavina.
Tässä artikkelissa analysoimme heidän tietojaan näistä luokitusmenetelmistä.
Five-Thirty-Eight ei kaihda selittämästä ennustemallejaan erittäin teknisin termein (ainakaan tarpeeksi monimutkaisilla termeillä maallikolle).
Kyselytutkimusluokitus ja -ranking
Tässä maassa toimii lukuisia mielipidekyselyiden tekijöitä. Niiden lukeminen ja laadun mittaaminen voi olla erittäin rasittavaa ja riitaisaa. Sivuston mukaan: ”Mielipidemittausten lukeminen voi olla terveydelle vaarallista. Oireita ovat muun muassa kirsikoiden poimiminen, liiallinen itsevarmuus, jonninjoutavat numerot ja hätiköity tuomitseminen. Onneksi meillä on parannuskeino.” (lähde)
On olemassa gallupeja. Sitten on gallupeja gallupeista. Sitten on gallupien painotettuja gallupeja. Ennen kaikkea on gallupien gallupeja, joiden painotukset ovat tilastollisesti mallinnettuja ja dynaamisesti muuttuvia painotuksia.”
Tuntuuko tutulta muista kuuluisista ranking-menetelmistä, joista olet kuullut datatieteilijänä? Amazonin tuoteranking tai Netflixin elokuvien ranking? Todennäköisesti, kyllä.
Välttämättä Five-Thirty-Eight käyttää tätä luokitus-/ranking-järjestelmää painottaakseen gallup-tuloksia (korkealle rankattujen gallupien tulokset saavat suuremman painoarvon ja niin ja niin). He myös seuraavat aktiivisesti kunkin mielipidetutkimuksen tuloksen taustalla olevaa tarkkuutta ja metodologiaa ja muokkaavat rankingia vuoden mittaan.
On mielipidetutkimuksia. Sitten on gallupeja gallupeista. Sitten on gallupien painotettuja gallupeja. Ennen kaikkea on gallupien gallupeja, joiden painotukset ovat tilastollisesti mallinnettuja ja dynaamisesti muuttuvia painotuksia.
On mielenkiintoista huomata, että heidän ranking-menetelmänsä ei välttämättä luokittele paremmaksi mielipidetutkimuksen tekijää, jolla on suurempi otoskoko. Seuraava kuvakaappaus heidän verkkosivuiltaan osoittaa sen selvästi. Vaikka Rasmussen Reportsin ja HarrisX:n kaltaisilla mielipidekyselytoimittajilla on suuremmat otoskoot, itse asiassa juuri Marist College saa A+-luokituksen vaatimattomalla otoskoolla.
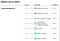
Onneksi he myös avaavat avoimen lähdekoodin mielipidekyselyiden ranking-tiedoistaan (yhdessä lähes kaikkien muiden tietokokonaisuuksiensa kanssa) täällä Githubissa. Ja jos olet kiinnostunut vain kivannäköisestä taulukosta, tässä se on.
Naturally, as a data scientist, you may want to look deeper into the raw data and understand things like,
- how their number ranking correlates with the accuracy of the pollsters
- if they have a partisan bias towards selecting particular pollsters (in most cases, they can be categorized as either Democratic-leaning or Republican-leaning)
- who are the top-rated pollsters? Tekevätkö he monia mielipidetutkimuksia vai ovatko he valikoivia?
Yritimme analysoida tietokokonaisuutta tällaisten näkemysten hankkimiseksi. Tutustutaanpa koodiin ja tuloksiin, eikö niin?
Analyysi
Jupyter Notebook löytyy täältä Github-repostani.
Lähde
Aluksi voit vetää datan suoraan heidän Githubistaan Pandas DataFrameen seuraavasti,

Tämässä datasetissä on 23 saraketta. Tältä ne näyttävät,

Joitakin muunnoksia ja siistimistä
Huomaamme, että eräässä sarakkeessa on ylimääräistä tilaa. Muutama muu saattaa tarvita jonkin verran louhintaa ja tietotyyppimuunnosta.



Tämän uutoksen soveltamisen jälkeen, uudessa DataFrame-tietokannassa on lisäsarakkeita, minkä ansiosta se soveltuu paremmin suodatukseen ja tilastolliseen mallintamiseen.

”538-arvosana”-sarakkeen tutkiminen ja kvantittaminen
Sarakkeessa ”538-arvosana” on tietokokonaisuuden ydin – kyselytutkimuksen kirjainarvosana. Aivan kuten tavallisessa tentissä, A+ on parempi kuin A, ja A on parempi kuin B+. Jos piirrämme kirjainarvosanojen lukumäärät, havaitsemme yhteensä 15 astetta A+:sta F:ään.

307>
Siinä monien kategoriaalisten arvosanojen työstämisen sijaan voimme ehkä yhdistellä ne pieneksi määräksi numeerisia arvosanoja – 4 arvosanaa arvosanoille A+/A/A-, 3 arvosanaa arvosanalle B jne.

Boxplotit
Visuaaliseen analytiikkaan siirryttäessä voimme aloittaa boxplottien avulla.
Asettakaamme, että haluaisimme tarkastaa, kumpi kyselymenetelmä suoriutuu ennustevirheiden suhteen paremmin. Tietoaineistossa on sarake nimeltä ”Simple Average Error”, joka on määritelty seuraavasti: ”The firm’s average error, calculated as the difference between the polled result and the actual result for the margin separating the top two finishers in the race”.”

Tällöin meitä voi kiinnostaa tarkistaa, onnistuvatko tiettyyn puoluepoliittiseen suuntautuneisuuteen pyrkivät mielipidekyselytutkimusyritykset sanomaan vaalit oikein paremmin kuin muut.

Havaitsitko jotain mielenkiintoista yllä? Jos olet edistyksellinen, liberaalisti ajatteleva henkilö, saatat suurella todennäköisyydellä olla demokraattipuolueen puoluepuolue. Mutta keskimäärin mielipidemittaajat, joilla on republikaaninen taipumus, kutsuvat vaaleja tarkemmin ja pienemmällä vaihtelulla. Parempi varoa noita mielipidetutkimuksia!
Toinen mielenkiintoinen sarake tietokannassa on nimeltään ”NCPP/AAPOR/Roper”. Siinä ”ilmoitetaan, oliko mielipidetutkimusyritys National Council on Public Polls -järjestön jäsen, American Association for Public Opinion Research -järjestön avoimuusaloitteen allekirjoittaja tai Roper Center for Public Opinion Research -järjestön data-arkiston rahoittaja”. Jäsenyys tarkoittaa käytännössä sitä, että kyselytutkimusmenetelmiä noudatetaan vankemmin.” (lähde).
Miten arvioida edellä mainitun väitteen paikkansapitävyyttä? Tietoaineistossa on sarake nimeltä ”Advanced Plus-Minus”, joka on ”pistemäärä, jossa verrataan mielipidetutkimuksen tekijöiden tuloksia muihin mielipidetutkimusyrityksiin, jotka tekevät kyselytutkimuksia samoista vaaleista, ja jossa painotetaan viimeaikaisia tuloksia enemmän. Negatiiviset pisteet ovat suotuisia ja viittaavat keskimääräistä parempaan laatuun” (lähde).
Tässä on boxplot näiden kahden muuttujan välillä. NCCP:hen/AAPOR:iin/Roper:iin liittyvillä mielipidetutkimuksilla on alhaisempi virhepistemäärä, mutta niillä on myös huomattavasti alhaisempi vaihtelu. Heidän ennusteensa näyttävät olevan tasaisia ja vankkoja.

Jos olet edistysmielinen, liberaalisti ajatteleva henkilö, saatat mitä suurimmalla todennäköisyydellä olla demokraattisen puolueen puoluepuolueessa. Mutta keskimäärin mielipidemittaajat, joilla on republikaaneihin suuntautuva ennakkoasenne, kutsuvat vaaleja tarkemmin ja pienemmällä vaihtelulla.
Scatter- ja regressiokuvioita
Ymmärtääksemme muuttujien välistä korrelaatiota voimme tarkastella hajontakuvioita regressiosovituksella. Käytämme Seaborn- ja Scipy Python-kirjastoja ja räätälöityä funktiota näiden kuvaajien tuottamiseen.
Voidaan esimerkiksi suhteuttaa ”Races Called Correctly” (Oikein kutsutut kilpailut) ”Predictive Plus-Minus” (Ennustettu plus-miinus) -lukuun. Five-Thirty-Eightin mukaan ”Predictive Plus-Minus” on ”ennuste siitä, kuinka tarkka mielipidemittaaja on tulevissa vaaleissa. Se lasketaan palauttamalla mielipidetutkimuksen Advanced Plus-Minus -pisteet keskiarvoon, joka perustuu metodologista laatua kuvaaviin mittareihimme.” (lähde)

Tai voimme tarkistaa, miten määrittelemämme ”Numeerinen arvosana” korreloi mielipidetutkimusten virheiden keskiarvon kanssa. Negatiivinen suuntaus osoittaa, että korkeampi numeerinen arvosana liittyy pienempään kyselyvirheeseen.

Voimmekin tarkastaa, auttaako ”Mielipideanalyysin mielipidekyselyiden määrä” vähentämään kullekin mielipidekyselytutkimuksen suorittajalle määriteltyä ”puolueellisen ennakkoluulon astetta”. Voimme havaita alaspäin suuntautuvan suhteen, mikä osoittaa, että suuri määrä mielipidetutkimuksia auttaa vähentämään puolueellisen puolueellisuuden astetta. Suhde näyttää kuitenkin erittäin epälineaariselta, ja logaritminen skaalaus olisi ollut parempi käyrän sovittamiseksi.

Luotetaanko aktiivisempiin mielipidekyselytoimittajiin enemmän? Piirretään gallupien määrän histogrammi ja nähdään, että se noudattaa negatiivista potenssilakia. Voimme suodattaa pois ne mielipidemittaajat, joilla on sekä hyvin vähän että hyvin paljon mielipidemittauksia, ja luoda mukautetun hajontakuvion. Havaitsemme kuitenkin lähes olemattoman korrelaation gallupien lukumäärän ja Predictive Plus-Minus -pistemäärän välillä. Suuri gallupien määrä ei siis välttämättä johda korkeaan gallupien laatuun ja ennustusvoimaan.