




SQL DISTINCT ja TOP samassa kyselyssä
Tämän artikkelin innoittajana on kysymyssarja, jonka eräs lukijoistani, Nan, lähetti minulle hiljattain koskien DISTINCT-, TOP- ja ORDER BY -kysymyksiä.
Kaikki tämän oppitunnin esimerkit perustuvat Microsoft SQL Server Management Studioon ja AdventureWorks2012-tietokantaan. Voit aloittaa näiden ilmaisten työkalujen käytön käyttämällä opastani Getting Started Using SQL Server.
Miten SQL:n Top- ja Distinct SELECT -muuttujat toimivat yhdessä tulosten tuottamiseksi?
Tässä on kysymys, jonka Nan lähetti minulle alun perin:
Olen hieman hämmentynyt SELECT DISTINCT- ja SELECT-muuttujista. Esimerkiksi,
SELECT DISTINCT TOP 10 FirstName,
LastName
FROM Person.Person
ORDER BY LastName
Etsitäänkö tässä erillisiä etunimiä? Erillisiä yhdistettyjä etu- ja sukunimiä? Miten erotamme toisistaan sarakkeet, joita käytetään erilliseen arviointiin, ja sarakkeet, jotka haluamme vain näyttää tulosteessa?
Mikä
Select Distinct TOP 10 LastName,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY LastName
Ajattelin, että kaikki haluaisivat tietää vastauksen, joten luon blogikirjoituksen.
DISTINCT ja TOP – kumpi on ensin?
Katsotaanpa ensimmäistä lauseketta, jonka tarkoituksena on palauttaa yksilöllinen lista etu- ja sukunimistä.
SELECT DISTINCT TOP 10 FirstName,
LastName
FROM Person.Person
ORDER BY LastName;
TOP 10 palauttaa järjestetystä joukosta kymmenen ensimmäistä kohdetta, ja DISTINCT poistaa mahdolliset duplikaatit. Kysymys kuuluu, kumpi tapahtuu ensin?
- Lajitellaanko taulukko sukunimen mukaan ja otetaan kymmenen ensimmäistä kohdetta, minkä jälkeen poistetaan kaksoiskappaleet?
- Vai poistetaanko kaksoiskappaleet, minkä jälkeen lajitellaan kohteet ja näytetään kymmenen ensimmäistä kohdetta?
Ennen kuin vastaamme tähän kysymykseen, pitää muistaa, että DISTINCT vaikuttaa kaikkiin SELECT-lausekkeen sarakkeisiin ja ilmauksiin. Tässä tapauksessa lauseke palauttaa siis erilliset rivit FirstName- ja LastName-kentille.
Ei valitettavasti ole suoraa tapaa käyttää DISTINCT-lauseketta yhteen kenttäjoukkoon ja näyttää muita. Kun lisäät sarakkeita SELECT-lauseeseen, ne joutuvat DISTINCT-operaattorin vaikutuksen alaisiksi. Sanon suora, koska voisit saada erillisen listan ja sitten käyttää INNER JOINia muiden sarakkeiden vetämiseen. Siinä on kuitenkin omat vaaransa, sillä liitos voi tuoda uudelleen kaksoiskappaleet.
TOP-lausekkeen lisääminen DISTINCT-lausekkeeseen on mielenkiintoista. En ollut varma, mitä tapahtuisi, mutta tein kokeiluja AdventureWorks-tietokannalla ja huomasin, että käsittelyjärjestys menee jotakuinkin näin:
- Valitaan DISTINCT-arvot taulukosta ja järjestetään
- Valitaan vaiheessa 1 saaduista tuloksista TOP x riviä ja näytetään.
Jos haluat kokeilla tätä itse, aloita
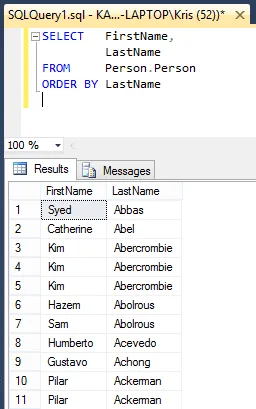
SELECT FirstName,
LastName
FROM Person.Person
ORDER BY LastName
Ja huomioi tulokset. Seuraa ”Kim Ambercombie”. Huomaa, että hänen nimellään on kolme merkintää.
Jatka nyt
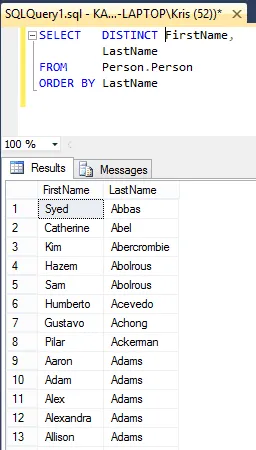
SELECT DISTINCT FirstName,
LastName
FROM Person.Person
ORDER BY LastName
Ja huomaat, että ”Kim Ambercombie” näkyy vain kerran.
Sitten run
SELECT DISTINCT TOP 10 FirstName,
LastName
FROM Person.Person
ORDER BY LastName
Ja näet, että se palauttaa 10 ensimmäistä yksilöllistä etu- ja sukunimeä Sukunimen mukaan lajiteltuna.
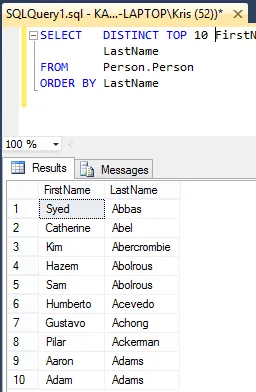
Jos mietit, kumpi tapahtuu ensin, DISTINCT- vai TOP 10 -operaatio, vertaa kahden viimeisen kyselyn tuloksia.
Huomaa, että ”DISTINCT TOP 10” -kyselyssä on mukana ensimmäiset 10 riviä ”DISTINCT”-kyselyn kyselystä.
Tästä tiedämme, että ensin luodaan DISTINCT-luettelo ja sen jälkeen palautetaan TOP 10 -luettelo.
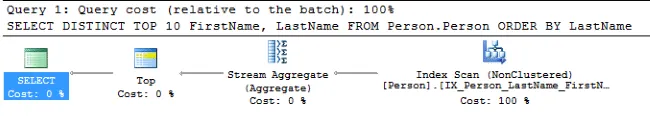
Voit vahvistaa tämän myös näyttämällä kyselysuunnitelman. Voit tehdä sen valitsemalla valikosta Query -> Include Actual Query Plan (Sisällytä todellinen kyselysuunnitelma) ennen kyselyn suorittamista.
Kuvake ”Stream Aggregate” (Virta-aggregaatti) tarkoittaa DISTINCT-operaatiota ja ”Top” (Huippu) TOP 10 -toimintoa.
Saattaa tuntua hiukan intuitiiviselta nähdä, että SELECT-lauseen sisällä luetellaan ensin DISTINCT. Muista vain, että SQL:ää ei välttämättä käsitellä siinä järjestyksessä, jossa ihminen lukisi sitä vasemmalta oikealle.
DISTINCT ja TOP SELECT-listan lausekkeiden kanssa
Nanin kysymyksen toinen osa liittyi siihen, miten lausekkeita käsitellään DISTINCT-operaattorin kanssa.
Lausekkeita kohdellaan samalla tavalla kuin sarakkeita DISTINCT- ja TOP-operaattoreiden suhteen. Aloitetaan select-lausekkeella, jolla saadaan etunimi sekä koko, jonka luomme liittämällä LastName ja FirstName yhteen.
Muista myös, kun käytät ORDER BY -operaattoria, että ORDER BY -kohtien on oltava select-luettelossa, kun käytät Distinct-operaattoria. Tämän huomioon ottaen minun on muutettava alkuperäisessä kysymyksessä esitettyä lauseketta:
SELECT DISTINCT FirstName,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY LastName
Ei toimi, koska LastName ei ole SELECT-luettelossa. Kyllä, se on osa select-luettelossa olevaa lauseketta, mutta se ei ole siellä yksinään. Järjestäminen FullNamen mukaan on pätevä.
Käytämme tätä järjestystä alla olevissa esimerkeissä.
Lauseke
SELECT FirstName,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY FirstName + ' ' + LastName
Palauttaa 19972 riviä. Kun lisäämme Distinct
SELECT DISTINCT FirstName,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY FirstName + ' ' + LastName
Tällöin palautetaan 19516 riviä. Lopuksi lisäämällä Top 10 palautetaan 10 ensimmäistä erillistä nimiyhdistelmää.
SELECT DISTINCT TOP 10 FirstName,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY FirstName + ' ' + LastName
Kokeile suorittaa nämä kyselyt AdventureWork-tietokannassa, niin näet itse, että käyttäytyminen on sama kuin silloin, kun työskentelemme yksinomaan sarakkeiden kanssa.