




SQL Magazine 7 -artikkeli – SQL Server: Turbinoi kyselyjäsi indeksoiduilla näkymillä
Ota kysymyksesi Merkitse valmiiksi Kommentoi
Tämän artikkelin tarkoituksena on esitellä SQL Serverin indeksoitujen näkymien käsite ja näyttää, miten tämäntyyppinen näkymä voidaan toteuttaa ja käyttää kyselyjen optimoimiseksi.
Näkymän käsite
Näkymiä kutsutaan myös ”virtuaalisiksi taulukoiksi”, koska ne tarjoavat vaihtoehdon taulukoiden käyttämiselle datan käyttämiseen. Näkymä ei ole muuta kuin SELECT-lause, joka on koteloitu objektiin. Näkymän luomisen syntaksi on esitetty Listauksessa 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Katso esimerkki näkymän luomisesta ja käytöstä Listauksessa 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Listaus 1. Näkymien luominen ja käyttö
Näkymien käytön eduista voidaan mainita :
- Koodin yksinkertaistaminen: voit kirjoittaa monimutkaiset SELECTit kerran, kapseloida ne näkymään ja laukaista ne näkymästä käsin, ikään kuin kyse olisi mistä tahansa taulukosta;
- Turvallisuuskysymykset: Oletetaan, että joissakin taulukoissa on luottamuksellista tietoa, minkä vuoksi haluat, että vain tietyt käyttäjät pääsevät käyttämään niitä. Kaikkien käyttäjien on kuitenkin päästävä käsiksi joihinkin näiden taulukoiden sarakkeisiin. Tehokas tapa ratkaista tämä ongelma on luoda näkymä ja piilottaa herkät sarakkeet. Tällä tavoin voidaan tukahduttaa alkuperäisen taulukon käyttöoikeudet ja vapauttaa näkymän käyttöoikeudet;
- Mahdollisuus kyselyjen optimointiin toteuttamalla indeksoidut näkymät.
Indexoidut näkymät käytännössä
Näkymät kapseloivat SELECT-lauseet, mikä tarkoittaa sitä, että aina kun ne käynnistetään, niihin liittyvät SELECT-lauseet suoritetaan. Näkymät eivät luo arkistoja palauttamilleen tiedoille (kuten taulukko tekee). Olisi hienoa, jos voisimme ”materialisoida” taulukkoon näkymässä olevan SELECT-komennon tuloksen ja luoda indeksit, jotka helpottavat pääsyä siihen. Indeksoidut näkymät tekevät juuri niin. SELECTin suorittamisella indeksoidussa näkymässä on sama vaikutus kuin selectin suorittamisella tavanomaisessa taulussa.
Indeksoitujen näkymien päätarkoitus on suorituskyvyn lisääminen, ja SQL Serverin etuna on, että suoritussuunnitelmat voivat ottaa indeksoidun näkymän huomioon tietojen käyttövälineenä, vaikka näkymän nimeä ei olisi nimenomaisesti mainittu kyselyssä. Tämä on mahdollista SQL Server 2000:n Enterprise Edition -versiossa, jossa komentooptimointiohjelma voi valita tietoja suoraan indeksoidusta näkymästä (sen sijaan, että se valitsisi taulukossa olevia raakadatoja), kuten seuraavaksi nähdään.
Indeksoidun näkymän luominen vaihe vaiheelta
- Ympäristön konfigurointi, ensimmäinen vaihe on asettaa joidenkin parametrien tila istunnossa, jossa haluat luoda ja käyttää näkymää, koska koska indeksoitu näkymä on ”materialisoitu” taulukkoon, mikään ei voi häiritä sen tulosta. Kuvittele esimerkiksi seuraava skenaario:
- Tämä asetus, joka vaikuttaa SELECTin tulokseen (esim. concat_null_yelds_null), asetetaan ennen indeksoidun näkymän luomista;
- Indeksoitu näkymä luodaan; huomaa, että näkymän tulos ”materialisoidaan” levylle edellisessä vaiheessa asetetun asetuksen mukaisesti;
- Sitten asetus poistetaan käytöstä ja käyttäjä suorittaa indeksoidun näkymän. Koska näkymä on materialisoitu, saamme tuloksen, joka on ristiriidassa nykyisen kokoonpanon kanssa.
Listauksessa 2 näkyy esimerkiksi ero komennon tuloksessa, kun concat_null_yields_null-ominaisuutta muutetaan.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcKuvittele, mitä tapahtuisi, jos indeksoitu näkymä luotaisiin concat_null_yields_null-ominaisuus käytössä, mutta nykyisessä istunnossa ominaisuus olisi poistettu käytöstä – sama SELECT johtaisi eri tuloksiin!
Tämä ongelma ratkaistiin yksinkertaisella tavalla – indeksoitujen näkymien luomiseksi ja käyttämiseksi on pakko määrittää ympäristö oletusarvojen luettelon mukaisesti. Näin on mahdotonta saada erilaisia tuloksia, koska näkymä ei yksinkertaisesti toimi, jos jokin asetuksista on asetettu epätyypilliseen arvoon.
Taulukossa 1 näkyvät nämä asetukset ja niiden oletusarvot.
| Asetus | Id (*) | Velvoitetila indeksoiduille näkymille | SQL Server 2000:n oletus | Esimerkkinä oletusarvo OLE DB- (=ADO) tai ODBC-yhteyksissä | Esimerkkinä oletusarvo DB-kirjastoa käyttävissä yhteyksissä | |||
|---|---|---|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF | |||
| ANSI_PADDING | 16 | ON | ON | ON | OFF | |||
| ANSI_WARNING | 8 | ON | ON | OFF | ON | OFF | ||
| ARITHABORT | 64 | ON | OFF | OFF | OFF | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF | ON | OFF | |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF | |||
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF | OFF |
(*) Tunnusta käytetään komennossa sp_configure. Jos haluat tarkistaa, mitä kukin asetus tekee, lue kohta ”Indeksoitujen näkymien vaaditut asetukset”. Määrityksen arvoa voidaan muuttaa kahdella tavalla:
- Suoraan istunnossa: suorita komento set ON | OFF
- Olemassa olevan palvelimen oletusarvon muuttaminen: suorita sp_Configure ’user options’, . Kunkin kokoonpanon tunnistenumero on esitetty taulukossa 1.
Huomautus: AritHabortin id on 64 ja Quoted_Identifierin id on 256. Linkittääksemme esimerkiksi Quoted_Identifier + AritHabort, suoritamme komennon sp_cofigure ja annamme parametrina tuloksen 64+256 (=320): sp_configure ’user options’, 320. Täydellinen luettelo kullekin kokoonpanolle määritetyistä tunnuksista on osoitteessa http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
Voit vahvistaa kunkin taulukossa 1 esitetyn parametrin tilan käyttämällä SessionProperty(’parametrin nimi’) -funktiota tai DBCC UserOptions -komentoa.
Säädä näin kaikki parametrit taulukon 1 sarakkeen ’Indeksoitujen näkymien vaadittu tila’ mukaisesti – jos näin ei tehdä, SQL Server ei salli indeksoidun näkymän luomista/suorittamista.
Indeksoidun näkymän luominen
Luomme näkymän, jonka avulla voidaan laskea yhteen myydyt päiväkohtaiset summat NorthWind-tietokannassa sijaitsevassa Tilauserittelyt-taulussa. Katso Listaus 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goLuotaessamme indeksoituja näkymiä on huomioitava joitain erityispiirteitä:
- Näkymän on oltava deterministinen. Näkymä on deterministinen, jos sen koodissa käytetään vain deterministisiä funktioita. Sama SELECT-komento, joka suoritetaan toistuvasti indeksoidulle näkymälle (ottaen huomioon staattinen pohja), ei voi antaa erilaisia tuloksia. Deterministiset funktiot varmistavat, että funktion tulos pysyy muuttumattomana riippumatta siitä, kuinka monta kertaa se suoritetaan. Esimerkiksi funktio DatePart on deterministinen, koska se palauttaa aina saman tuloksen tietylle päivämäärälle. Getdate()-funktio palauttaa eri arvon joka kerta, kun se suoritetaan. Täydellinen luettelo SQL Server 2000:n deterministisistä funktioista on osoitteessa http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Tarkista, ettei syntaksirajoituksia ole. Alla luetellut lausekkeet, funktiot ja kyselytyypit eivät voi integroida indeksoidun näkymän skeemaa:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUMMA sarakkeille, jotka sallivat nolla-arvot
- DISTINCT
- ROWSET-funktio
- Johdetut taulukot, self-joinit, alakyselyt, outer joins
- DISTINCT
- UNION
- Float, text, ntext ja image
- COMPUTE ja COMPUTE BY
- HAVING, CUBE ja ROLLUP
On luotava indeksoituja näkymiä SchemaBindingilla. Jotta näkymän sisältö pysyisi johdonmukaisena, et voi muuttaa näkymän perustana olevien taulukoiden rakennetta. Tällaisen ongelman välttämiseksi on pakollista käyttää SchemaBindingia, kun luodaan indeksoituja näkymiä, koska tämän vaihtoehdon avulla ei voi muuttaa taulukon rakennetta poistamatta ensin näkymää.
GROUP BY -lausekkeen käyttämiseksi on pakollista sisällyttää COUNT_BIG(*)-funktio. Funktio count_big(*) tekee saman kuin count(*), mutta palauttaa arvon, jonka tyyppi on bigint (8 tavua).
Ilmoita aina indeksoidussa näkymässä viitattujen objektien omistajalle. Käytä select * from dbo.Orders -taulukkoa select * from Orders -taulukon sijasta, koska on mahdollista, että taulukoilla on sama nimi mutta eri omistajat. Koska schemabinding-vaihtoehto on pakollinen, SQL Server tarvitsee tarkan objektimäärittelyn hillitäkseen skeeman muuttamista.
Klusteri-indeksin luominen näkymään (materialisointi)
Kohdassa 2 luotu näkymä ei vielä käyttäydy indeksoituna näkymänä, koska select-komennon tulosta ei ole materialisoitu tauluksi. Voit vahvistaa tämän väitteen suorittamalla Query Analyzerissa komennon sp_spaceused, joka palauttaa taulujen käyttämien rivien ja tilan määrän (Listaus 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Listaus 5:stä voit havaita, että näkymän prosessointi on puhtaasti loogista, niin paljonko Fyysiset lukukerrat (Physical Reads) -kohdan arvoksi tulee nolla. Huomaa loogiset lukemat ja fyysiset lukemat (1672+0+4+0=1676) – käytämme näitä arvoja tulevissa vertailuissa.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Tarkistaaksemme, voidaanko näkymä indeksoida (materialisoida), eli onko se luotu indeksoituja näkymiä varten vaadittujen standardien ja asetusten mukaisesti, seuraavan SELECTin tuloksen pitäisi olla yhtä suuri kuin 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')>Varmistaaksemme, että kaikki tarvittavat edellytykset täyttyvät, voimme nyt luoda indeksin. Syntaksi on samassa muodossa kuin luotaessa perinteisten taulujen indeksejä:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Huomaa, että klusteri-indeksiä tarvitaan, koska se tuottaa sivuja tietoja. Voit luoda indeksoituihin näkymiin muita kuin klusteri-indeksejä vasta sen jälkeen, kun olet luonut klusteri-indeksin.
Nyt näkymästä löytynyt SELECT on materialisoitu. mikä voidaan todistaa Query Analyzerin sp_spaceused-komennolla (Luettelo 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBIndeksoitujen näkymien käyttäminen
Yksi tapa käyttää indeksoitua näkymää (samoin kuin tavallista näkymää) on viitata sen nimeen SELECT-komennossa:
select * from vi_vendas_mesVertaile listassa 5 siirrettyjen sivujen määrää (1672+4=1676) ja listassa 7 siirrettyjen sivujen määrää (2+0=2). Ero on melko merkittävä – indeksoidun näkymän luominen vähensi vaaditun I/O:n kokonaismäärää 1674 sivua.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Katsotaanpa toista esimerkkiä. Kuvassa 1 esitetään kyselyn suoritussuunnitelma. Vahvista, että näkymä oli valittu, vaikka sitä ei ollut SELECT-rivillä.
Kyselyn suoritussuunnitelmaa laadittaessa optimoija havaitsi, että vi_sales_mes-tietokannassa oli jo valmiiksi tiivistettyjä tietoja kyselyä varten, ja päätti valita tiedot suoraan indeksoidusta näkymästä.
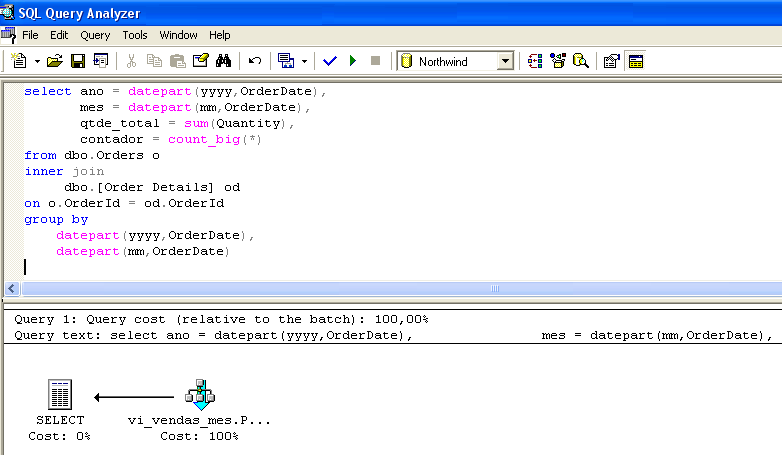
Huomaa, että kuvassa 1 suoritettu kysely on identtinen näkymässä vi_sales_mes olevan kyselyn kanssa. Optimoijan pääsy näkymään on kuitenkin riippumaton suoritetun kyselyn ja näkymäkyselyn välisestä samankaltaisuudesta. Kun kyselyprosessori valitsee indeksoidun näkymän, se ottaa huomioon ainoastaan kustannus-hyötysuhteen. Tällä tavoin suoritettavien kyselyjen ei tarvitse olla identtisiä näkymän kanssa (katso kuva 3).
On kuitenkin noudatettava joitakin sääntöjä, jotta kyselyoptimoija voi ottaa indeksoidun näkymän huomioon:
- Näkymässä esiintyvän liitoksen on oltava ”mukana” kyselyssä: jos kysely suorittaa liitoksen taulukoiden A ja B välillä ja näkymä suorittaa liitoksen taulukoiden A ja C välillä, näkymää ei käynnistetä suoritussuunnitelmassa. Jos kysely kuitenkin suorittaa liitoksen A,B ja C välillä, näkymä voi käynnistyä.
- Kyselyssä asetettujen ehtojen on oltava yhtäpitäviä näkymän ehtojen kanssa: kuvassa 2 esitetyssä SELECTissä indeksoitua näkymää vi_sales_mes ei oteta huomioon, koska näkymäkoodissa ei ollut where-lauseketta, joka aiheutti sen, että liitoksessa laskettiin rivejä, joiden määrä <= 5.
Toisaalta, jos kyselyssä on where-ehto where sum(Quantity) > 5, näkymä vi_sales_mes otetaan huomioon suoritussuunnitelmassa, koska kyselyehto on näkymässä olevan SELECTin osajoukko.
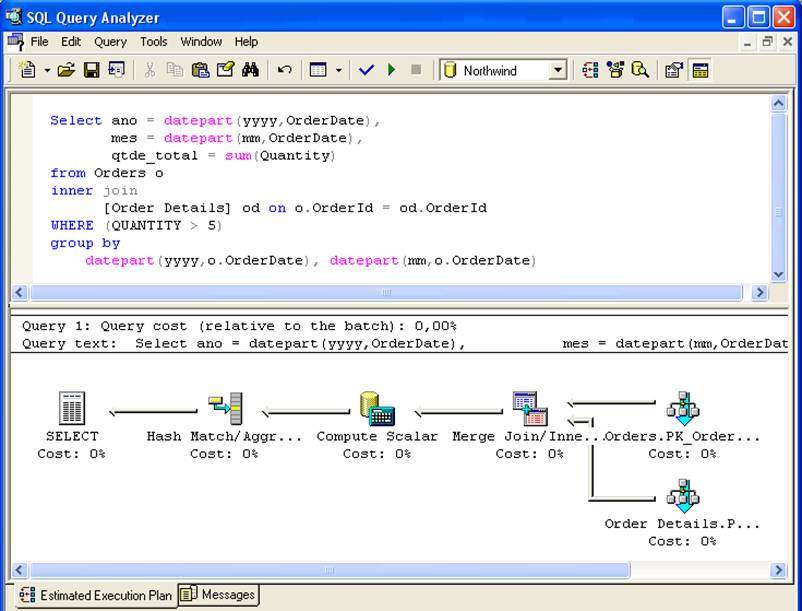
Kyselyssä aggregaatiotoimintoja sisältävien sarakkeiden on ”sisällyttävä” näkymän määritelmään: jos näkymä palauttaa sarakkeen qtde=sum(Määrä) ja kyselyssä on sarake vlr_unit=sum(Yksikköhinta), näkymää ei oteta huomioon.
Kuvassa 3 näkyy SELECT-komento, jonka avulla voidaan todistaa komentooptimoijan älykkyys – AVG(Quantity) -laskenta on korvattu jakamalla SUM(Quantity) / Count_Big(*), jota esittää Compute Scalar -kuvake. Myös predikaatti where sum(Quantity) > 1500 (jota edustaa suodatuskuvake) otetaan huomioon.
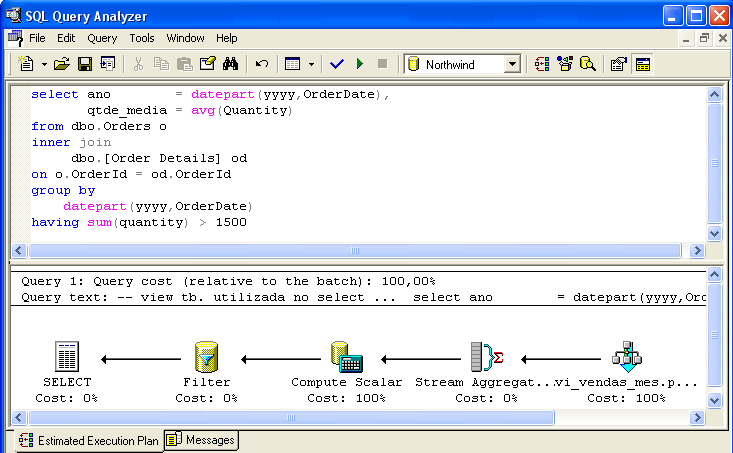
Yleisiä näkökohtia indeksoitujen näkymien käytöstä:
- Indeksoituja näkymiä voidaan luoda missä tahansa SQL Server 2000 -versiossa. Kyselyn optimoija valitsee ne kuitenkin automaattisesti vain Enterprise Edition -versiossa.
- Muissa versioissa kuin Enterprise-versiossa sinun on käytettävä NoExpand-vihjettä, jos haluat käyttää indeksoitua näkymää tavallisena tauluna. Jos NoExpand-toimintoa ei käytetä, indeksoitua näkymää pidetään ”normaalina” näkymänä.
Huomautus: Expand-vihje tekee päinvastoin kuin NoExpand: se kohtelee indeksoitua näkymää ”tavallisena” näkymänä ja pakottaa SQL Serverin suorittamaan SELECT-lauseen ajonaikaisen vaiheen aikana.
- Indeksoidun näkymän ylläpito on automaattista (kuten indekseissä); se ei vaadi mitään ylimääräistä synkronointia. Oman luonteensa vuoksi (se tallentaa yleensä valmiiksi tiivistettyjä tietoja) sen päivitys on yleensä hieman hitaampaa kuin perinteisten indeksien päivitys.
- Indeksoitujen näkymien käyttö OLTP-tietokannoissa vaatii varovaisuutta, sillä vaikka niiden suorituskyky kyselyissä on hyvä, ne aiheuttavat ylikuormitusta prosesseissa, jotka muokkaavat näkymään liittyviä taulukoita. Tilanteissa, joissa tarvitaan korkeaa kirjoitussuorituskykyä ja joissa päivityksiä tehdään usein, indeksoitujen näkymien luominen ei ole suositeltavaa.
- Kuten indeksien kohdalla, optimoija analysoi Enterprise-versioiden näkymäkoodin osana kyselyn parhaan suoritussuunnitelman valintaa. Jos kuitenkin on monia indeksoituja näkymiä, jotka voidaan suorittaa samassa kyselyssä, tämä valinta-aika voi kasvaa huomattavasti, koska kaikki näkymät analysoidaan. Käytä siis tervettä järkeä, kun toteutat näkymiä.
Velvoittavat asetukset indeksoituja näkymiä varten
ANSI_NULLS
Määrittää, miten vertailut nolla-arvojen kanssa suoritetaan (Listaus 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Määrittää, miten char-, varchar-, binary- ja varbinary-sarakkeet tallennetaan, kun niiden sisältö on pienempi kuin taulukkorakenteessa määritelty koko. SQL Server 2000:n oletusarvo on pitää ansi_padding päällä (=ON); tässä tilassa sovelletaan seuraavia sääntöjä:
- Kun päivitetään char-sarakkeita, merkkijonon loppuun lisätään välilyönti, jos se on pienempi kuin sarakerakenteessa määritelty koko. Sama sääntö pätee binäärisarakkeisiin (tässä tapauksessa tila täytetään nollasarjalla)
- Varchar- tai varbinary-sarakkeet eivät noudata edellä mainittua sääntöä: ne säilyttävät aina alkuperäisen kokonsa.
ARITHABORT
Kun se on käytössä, se keskeyttää kyselyn suorituksen kohdatessaan nollalla jakamisen tai jonkinlaisen ylivuodon.
QUOTED_IDENTIFIER
Kun se on käytössä, se sallii kaksoisten lainausmerkkien käytön taulukoiden, sarakkeiden yms. nimien määrittelyssä. – Näin näissä nimissä voi olla välilyöntejä ja/tai erikoismerkkejä.
CONCAT_NULL_YELDS_NULL
Hallitsee null-arvoja sisältävien merkkijonojen yhdistämisen tulosta. Kun se on käytössä, määrittää, että tämän liitoksen on palautettava nolla-arvo; muussa tapauksessa se palauttaa itse merkkijonon.
ANSI_WARNINGS
Kun se on käytössä, määrittää virheilmoitusten tuottamisen, kun:
- käytät tiivistämistoimintoja ja kyselyalueelta löydetään nolla-arvoja;
- löydetään nollan avulla tehtyjä jaottelujaotteluita tai aritmeettisia ylivuotoja.
NUMERIC_ROUNDABORT
Säätää, miten SQL Serverin tulisi toimia, kun aritmeettisissa operaatioissa menetetään numeerinen tarkkuus. Jos parametri on käytössä ja muuttuja, jonka tarkkuus on kaksi desimaalia, saa arvon, jossa on kolme desimaalia, toiminto keskeytetään. Jos parametri on poistettu käytöstä, arvo typistetään kahteen desimaaliin.
Johtopäätös
Kyselyn optimoinnissa indeksoidut näkymät ovat hyvä valinta suorituskyvyn hyödyntämiseen. Arvioi siis perusteellisesti kyselyt, jotka käsittelevät yhteenvetoja ja joita suoritetaan tietyllä taajuudella, ja siirry indeksoitujen näkymien luomiseen. Tulos on sen arvoinen!