




À quel point les sondeurs sont-ils bons ? Analyse de l’ensemble de données de Five-Thirty-Eight
Nous analysons l’ensemble de données de classement des sondeurs du vénérable site de prédiction politique Five-Thirty-Eight.

C’est une année électorale et la scène des sondages autour des élections (à la fois générales présidentielles et Chambre/Sénat) se réchauffe. Cela va devenir de plus en plus passionnant dans les jours à venir, avec des tweets, des contre-tweets, des combats sur les médias sociaux et une infinité de poncifs à la télévision.
Nous savons que tous les sondages ne sont pas de la même qualité. Alors, comment donner du sens à tout cela ? Comment identifier les sondeurs dignes de confiance en utilisant des données et des analyses ?

Dans le monde de l’analyse prédictive politique (et de quelques autres matières comme le sport, les phénomènes sociaux, l’économie, etc.), Five-Thirty-Eight est un nom redoutable.
Depuis début 2008, le site publie des articles – créant ou analysant généralement des informations statistiques – sur une grande variété de sujets de la politique actuelle et de l’actualité politique. Le site Web, dirigé par le rockstar data scientist et statisticien Nate Silver, a atteint une proéminence particulière et une renommée généralisée autour de l’élection présidentielle de 2012, lorsque son modèle a correctement prédit le gagnant des 50 États et du district de Columbia.
Et avant de vous moquer et de dire « Mais qu’en est-il de l’élection de 2016 ? », vous seriez bien inspiré de lire cet article sur la façon dont l’élection de Donald Trump était dans la marge d’erreur normale de la modélisation statistique.
Pour les lecteurs plus curieux de politique, ils ont tout un sac d’articles sur l’élection de 2016 ici.
Les praticiens de la science des données devraient prendre goût à Five-Thirty-Eight parce qu’ils ne craignent pas d’expliquer leurs modèles prédictifs en termes très techniques (du moins assez complexes pour le profane).

Ils parlent ici d’adopter la fameuse distribution t, alors que la plupart des autres agrégateurs de sondages pourraient se contenter de l’omniprésente distribution normale.
Cependant, allant au-delà de l’utilisation de techniques de modélisation statistique sophistiquées, l’équipe de Silver s’enorgueillit d’une méthodologie unique – la notation des sondeurs – pour aider leurs modèles à rester très précis et dignes de confiance.
Dans cet article, nous analysons leurs données sur ces méthodes de notation.
Five-Thirty-Eight ne craint pas d’expliquer ses modèles prédictifs en termes de termes très techniques (du moins assez complexes pour le profane).
Notation et classement des sondeurs
Il existe une multitude de sondeurs opérant dans ce pays. Lire et jauger la qualité de ceux-ci peut être très taxant et fractionnant. Selon le site Web, « la lecture des sondages peut être dangereuse pour votre santé. Les symptômes comprennent la sélection, l’excès de confiance, l’adhésion à des chiffres fantaisistes et les jugements hâtifs. Heureusement, nous avons un remède. » (source)
Il y a les sondages. Puis, il y a les sondages de sondages. Puis, il y a des sondages pondérés de sondages. Et surtout, il y a un sondage de sondages avec des pondérations modélisées statistiquement et des pondérations qui changent de façon dynamique.
Cela vous rappelle d’autres méthodes de classement célèbres dont vous avez entendu parler en tant que scientifique des données ? Le classement des produits d’Amazon ou le classement des films de Netflix ? Probablement, oui.
Essentiellement, Five-Thirty-Eight utilise ce système de notation/classement pour pondérer les résultats des sondages (les résultats des sondeurs les mieux classés ont une plus grande importance et ainsi de suite). Ils suivent également activement la précision et les méthodologies derrière le résultat de chaque sondeur et ajustent leur classement tout au long de l’année.
Il y a des sondages. Ensuite, il y a des sondages de sondages. Puis, il y a des sondages pondérés de sondages. Et surtout, il y a un sondage de sondages avec des pondérations modélisées statistiquement et des pondérations qui changent dynamiquement.
Il est intéressant de noter que leur méthodologie de classement n’évalue pas nécessairement un sondeur avec une plus grande taille d’échantillon comme étant meilleur. La capture d’écran suivante de leur site web le démontre clairement. Alors que les instituts de sondage comme Rasmussen Reports et HarrisX ont des échantillons de plus grande taille, c’est en fait Marist College qui obtient la note A+ avec une taille d’échantillon modeste.
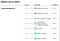
Heureusement, ils mettent également en open-source leurs données de classement des sondeurs (ainsi que presque tous leurs autres ensembles de données) ici sur Github. Et si vous n’êtes intéressé que par un joli tableau, le voici.
Naturellement, en tant que scientifique des données, vous pouvez vouloir regarder plus profondément dans les données brutes et comprendre des choses comme,
- comment leur classement numérique est corrélé avec la précision des sondeurs
- s’ils ont un parti pris partisan pour sélectionner des sondeurs particuliers (dans la plupart des cas, ils peuvent être classés comme étant de tendance démocrate ou républicaine)
- qui sont les sondeurs les mieux notés ? Réalisent-ils de nombreux sondages ou sont-ils sélectifs ?
Nous avons essayé d’analyser l’ensemble des données pour acquérir de tels aperçus. Creusons dans le code et les résultats, voulez-vous ?
L’analyse
Vous pouvez trouver le Jupyter Notebook ici sur mon repo Github.
La source
Pour commencer, vous pouvez tirer les données directement de leur Github, dans un Pandas DataFrame, comme suit,

Il y a 23 colonnes dans cet ensemble de données. Voici comment elles se présentent,

Quelques transformations et nettoyages
Nous remarquons qu’une colonne a un peu d’espace supplémentaire. Quelques autres peuvent avoir besoin d’une extraction et d’une conversion de type de données.



Après avoir appliqué cette extraction, le nouveau DataFrame possède des colonnes supplémentaires, ce qui le rend plus adapté au filtrage et à la modélisation statistique.

Examen et quantification de la colonne « 538 Grade »
Les colonnes « 538 Grades » contiennent le cœur du jeu de données – la note en lettre du sondeur. Comme pour un examen ordinaire, A+ est meilleur que A, et A est meilleur que B+. Si nous traçons les comptes des notes en lettres, nous observons 15 gradations, au total, de A+ à F.

Au lieu de travailler avec autant de gradations catégorielles, nous pourrions vouloir les combiner en un petit nombre de notes numériques – 4 pour A+/A/A-, 3 pour les B, etc.

Boxplots
Pour ce qui est de l’analyse visuelle, nous pouvons commencer par les boxplots.
Supposons que nous voulons vérifier quelle méthode de sondage est la plus performante en termes d’erreur de prédiction. L’ensemble de données a une colonne appelée « Erreur moyenne simple », qui est définie comme « L’erreur moyenne du cabinet, calculée comme la différence entre le résultat sondé et le résultat réel pour la marge séparant les deux premiers de la course. »

Donc, nous pouvons être intéressés à vérifier si les sondeurs ayant un certain parti pris partisan réussissent mieux que les autres à annoncer correctement les élections.

Vous avez remarqué quelque chose d’intéressant ci-dessus ? Si vous êtes un penseur progressiste et libéral, selon toute vraisemblance, vous pouvez être partisan du parti démocrate. Mais, en moyenne, les sondeurs à tendance républicaine, appelle les élections plus précisément et avec moins de variabilité. Mieux vaut faire attention à ces sondages !
Une autre colonne intéressante de l’ensemble de données s’appelle « NCPP/AAPOR/Roper ». Elle « indique si l’institut de sondage était membre du National Council on Public Polls, signataire de l’initiative de transparence de l’American Association for Public Opinion Research, ou contributeur aux archives de données du Roper Center for Public Opinion Research ». Effectivement, une adhésion indique une adhésion à une méthodologie de sondage plus robuste » (source).
Comment juger de la validité de l’affirmation susmentionnée ? L’ensemble de données comporte une colonne appelée « Advanced Plus-Minus », qui est « un score qui compare le résultat d’un sondeur à celui d’autres instituts de sondage étudiant les mêmes courses et qui pondère plus fortement les résultats récents. Les scores négatifs sont favorables et indiquent une qualité supérieure à la moyenne » (source).
Voici un boxplot entre ces deux paramètres. Non seulement les sondeurs, associés à NCCP/AAPOR/Roper, présentent un score d’erreur plus faible, mais ils affichent également une variabilité considérablement faible. Leurs prédictions semblent être stables et robustes.

Si vous êtes un penseur progressiste et libéral, selon toute vraisemblance, vous pouvez être partisan du parti démocrate. Mais, en moyenne, les sondeurs avec un parti pris républicain, appelle les élections plus précisément et avec moins de variabilité.
Plots de dispersion et de régression
Pour comprendre la corrélation entre les paramètres, nous pouvons regarder les diagrammes de dispersion avec ajustement de régression. Nous utilisons les bibliothèques Python Seaborn et Scipy et une fonction personnalisée pour générer ces diagrammes.
Par exemple, nous pouvons relier les « Courses appelées correctement » au « Plus-Minus prédictif ». Selon Five-Thirty-Eight, le « Predictive Plus-Minus » est « une projection de la précision du sondeur dans les élections futures. Il est calculé en ramenant le score Plus-Minus avancé d’un sondeur à une moyenne basée sur nos proxies pour la qualité méthodologique. » (source)

Or, nous pouvons vérifier comment la « Note numérique » que nous avons définie, est corrélée avec la moyenne des erreurs de sondage. Une tendance négative indique qu’une note numérique plus élevée est associée à une erreur de sondage plus faible.

Nous pouvons également vérifier si le « # de sondages pour l’analyse des biais » aide à réduire le « degré de biais partisan » qui est attribué à chaque sondeur. Nous pouvons observer une relation descendante, indiquant que la disponibilité d’un nombre élevé de sondages aide effectivement à réduire le degré de biais partisan. Cependant, la relation semble hautement non linéaire et une échelle logarithmique aurait été meilleure pour ajuster la courbe.

Doit-on faire davantage confiance aux sondeurs plus actifs ? On trace l’histogramme du nombre de sondages et on voit qu’il suit une loi de puissance négative. Nous pouvons filtrer les sondeurs dont le nombre de sondages est à la fois très faible et très élevé et créer un nuage de points personnalisé. Cependant, nous observons une corrélation presque inexistante entre le nombre de sondages et le score Plus-Moins prédictif. Par conséquent, un grand nombre de sondages ne conduit pas nécessairement à une qualité de sondage et un pouvoir prédictif élevés.