




Analyse statistique : Significativité et intervalles de confiance
Dans toute analyse statistique, il est probable que vous travailliez avec un échantillon, plutôt qu’avec les données de toute la population. Votre résultat peut donc ne pas représenter l’ensemble de la population – et pourrait même être très inexact si votre échantillonnage n’était pas très bon.
Vous avez donc besoin d’un moyen de mesurer à quel point vous êtes certain que votre résultat est exact, et n’est pas simplement le fruit du hasard. Les statisticiens utilisent pour cela deux concepts liés : la confiance et la signification.
Cette page explique ces concepts.
Signification statistique
Le terme signification a une signification très particulière en statistique. Il vous indique la probabilité que votre résultat ne soit pas le fruit du hasard.

Dans le schéma, le cercle bleu représente la population entière. Lorsque vous prélevez un échantillon, votre échantillon peut provenir de l’ensemble de la population. Cependant, il est plus probable qu’il soit plus petit. S’il provient entièrement du cercle jaune, vous auriez couvert une grande partie de la population. Cependant, vous pouvez aussi être malchanceux (ou avoir mal conçu votre procédure d’échantillonnage) et ne prélever votre échantillon que dans le petit cercle rouge. Cela aurait de sérieuses conséquences sur la représentativité de votre échantillon par rapport à l’ensemble de la population.
L’une des meilleures façons de s’assurer que vous couvrez une plus grande partie de la population est d’utiliser un échantillon plus grand. La taille de votre échantillon affecte fortement la précision de vos résultats (et vous trouverez plus d’informations à ce sujet dans notre page sur l’échantillonnage et le plan d’échantillonnage).
Cependant, un autre élément affecte également la précision : la variation au sein de la population elle-même. Vous pouvez l’évaluer en examinant les mesures de la dispersion de vos données (et pour en savoir plus, consultez notre page sur l’analyse statistique simple). Lorsqu’il y a plus de variation, il y a plus de chances que vous choisissiez un échantillon qui n’est pas typique.
Le concept de signification réunit simplement la taille de l’échantillon et la variation de la population, et fait une évaluation numérique des chances que vous ayez fait une erreur d’échantillonnage : c’est-à-dire que votre échantillon ne représente pas votre population.
La signification est exprimée comme une probabilité que vos résultats soient survenus par hasard, communément appelée valeur p. Vous cherchez généralement à ce qu’elle soit inférieure à une certaine valeur, généralement 0,05 (5 %) ou 0,01 (1 %), bien que certains résultats signalent également 0,10 (10 %).
Hypothèse nulle et alternative
Lorsque vous réalisez une expérience ou une étude de marché, vous voulez généralement savoir si ce que vous faites a un effet. Vous pouvez donc l’exprimer sous forme d’hypothèse :
-x aura un effet sur y.
C’est ce qu’on appelle en statistique « l’hypothèse alternative », souvent appelée H1.
L’hypothèse nulle, ou H0, est que x n’a pas d’effet sur y.
D’un point de vue statistique, le but des tests de signification est de voir si vos résultats suggèrent que vous devez rejeter l’hypothèse nulle – auquel cas, l’hypothèse alternative est plus susceptible d’être vraie.
Si vos résultats ne sont pas significatifs, vous ne pouvez pas rejeter l’hypothèse nulle, et vous devez conclure qu’il n’y a pas d’effet.
La valeur p est la probabilité que vous auriez obtenu les résultats que vous avez obtenus si votre hypothèse nulle est vraie.
Calcul de la significativité
Une façon de calculer la significativité est d’utiliser un score z. Celui-ci décrit la distance entre un point de données et la moyenne, en termes de nombre d’écarts types (pour en savoir plus sur la moyenne et l’écart type, consultez notre page sur l’analyse statistique simple).
Pour une comparaison simple, le score z est calculé à l’aide de la formule :
$$z=\frac{x – \mu}{\sigma}$
où \(x\) est le point de données, \(\mu\) est la moyenne de la population ou de la distribution, et \(\sigma\) est l’écart type.
Par exemple, supposons que nous souhaitions tester si une application de jeu est plus populaire que les autres jeux. Disons que l’app de jeu moyenne est téléchargée 1000 fois, avec un écart type de 110. Notre jeu a été téléchargé 1200 fois. Son score z est :
$$z=\frac{1200-1000}{110}=1,81$$
Un score z plus élevé signale que le résultat est moins susceptible d’être le fruit du hasard.
Vous pouvez utiliser un tableau statistique z standard pour convertir votre score z en une valeur p. Si votre valeur p est inférieure au niveau de signification souhaité, alors vos résultats sont significatifs.
En utilisant la table z, le z-score de notre application de jeu (1,81) se convertit en une valeur p de 0,9649. C’est mieux que notre niveau souhaité de 5% (0,05) (parce que 1-0,9649 = 0,0351, ou 3,5%), donc nous pouvons dire que ce résultat est significatif.
Notez qu’il existe une légère différence pour un échantillon issu d’une population, où le score z est calculé à l’aide de la formule :
$$z=\frac{(x-\mu)}{(\sigma/\sqrt n)}$$
où x est le point de données (généralement la moyenne de votre échantillon), µ est la moyenne de la population ou de la distribution, σ est l’écart-type et √n est la racine carrée de la taille de l’échantillon.
Un exemple rendra cela plus clair.
Supposons que vous vérifiez si les étudiants en biologie ont tendance à obtenir de meilleures notes que leurs camarades étudiant d’autres matières. Vous pourriez constater que la note moyenne du test pour un échantillon de 40 biologistes est de 80, avec un écart type de 5, contre 78 pour tous les étudiants de cette université ou école.
$$z=\frac{(80-78)}{(5/\sqrt 40)}=2,53$$
En utilisant la table z, 2,53 correspond à une valeur p de 0,9943. On peut la soustraire de 1 pour obtenir 0,0054. Cette valeur est inférieure à 1 %, nous pouvons donc dire que ce résultat est significatif au niveau de 1 % et que les biologistes obtiennent de meilleurs résultats aux tests que l’étudiant moyen de cette université.
Notez que cela ne signifie pas nécessairement que les biologistes sont plus intelligents ou meilleurs pour réussir les tests que ceux qui étudient d’autres matières. Cela pourrait, en fait, signifier que les tests en biologie sont plus faciles que ceux des autres matières. Trouver un résultat significatif n’est PAS une preuve de causalité, mais cela vous indique qu’il pourrait y avoir un problème que vous voulez examiner.
Il y a plus d’informations sur les tests de signification des moyennes d’échantillons, et sur les tests de différences entre les groupes, dans notre page sur le développement et le test d’hypothèses.
Intervalles de confiance
Un intervalle de confiance (ou niveau de confiance) est une plage de valeurs qui a une probabilité donnée que la vraie valeur se trouve à l’intérieur.
Effectivement, il mesure le degré de confiance que vous avez dans le fait que la moyenne de votre échantillon (la moyenne de l’échantillon) est la même que la moyenne de la population totale à partir de laquelle votre échantillon a été prélevé (la moyenne de la population).
Par exemple, si votre moyenne est de 12,4, et que votre intervalle de confiance à 95% est de 10,3-15,6, cela signifie que vous êtes sûr à 95% que la vraie valeur de la moyenne de votre population se situe entre 10,3 et 15,6. En d’autres termes, elle peut ne pas être 12,4, mais vous êtes raisonnablement sûr qu’elle n’est pas très différente.
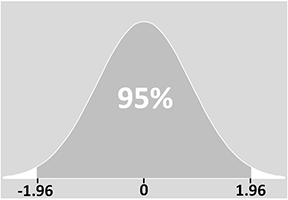
Le diagramme ci-dessous montre cela en pratique pour une variable qui suit une distribution normale (pour en savoir plus, consultez notre page sur les distributions statistiques).

La signification précise d’un intervalle de confiance est que si vous deviez faire votre expérience de très nombreuses fois, 95% des intervalles que vous avez construits à partir de ces expériences contiendraient la vraie valeur. En d’autres termes, dans 5 % de vos expériences, votre intervalle ne contiendrait PAS la vraie valeur.
Vous pouvez voir sur le diagramme qu’il y a 5 % de chances que l’intervalle de confiance ne comprenne pas la moyenne de la population (les deux » queues » de 2,5 % de chaque côté). En d’autres termes, dans un échantillon ou une expérience sur 20, la valeur que nous obtenons pour l’intervalle de confiance n’inclura pas la vraie moyenne : la moyenne de la population se situera en fait en dehors de l’intervalle de confiance.
Calcul de l’intervalle de confiance
Le calcul d’un intervalle de confiance utilise les valeurs de votre échantillon, et certaines mesures standard (moyenne et écart-type) (et pour en savoir plus sur la façon de les calculer, consultez notre page sur l’analyse statistique simple).
C’est plus facile à comprendre avec un exemple.
Supposons que nous échantillonnions la taille d’un groupe de 40 personnes et que nous trouvions que la moyenne était de 159,1 cm, et l’écart-type de 25,4.
Ecart-type pour les intervalles de confiance
Idéalement, vous utiliseriez l’écart-type de la population pour calculer l’intervalle de confiance. Cependant, il est très peu probable que vous sachiez ce que c’est.
Heureusement, vous pouvez utiliser l’écart-type de l’échantillon, à condition d’avoir un échantillon suffisamment grand. On s’accorde généralement à dire que le point de coupure est un échantillon de 30 personnes ou plus, mais plus il est grand, mieux c’est.
Nous devons déterminer si notre moyenne est une estimation raisonnable des hauteurs de toutes les personnes, ou si nous avons choisi un échantillon particulièrement grand (ou petit).
Nous utilisons une formule pour calculer un intervalle de confiance. C’est :
$$moyenne \pm z \frac{(SD)}{\sqrt n}$$
Où SD = écart-type, et n est le nombre d’observations ou la taille de l’échantillon.
La valeur z est tirée des tableaux statistiques pour la distribution de référence que nous avons choisie. Ces tableaux fournissent la valeur z pour un intervalle de confiance particulier (disons 95 % ou 99 %).
Dans ce cas, nous mesurons les hauteurs des personnes, et nous savons que les hauteurs de la population suivent une distribution (globalement) normale (pour en savoir plus, voir notre page sur les distributions statistiques).Nous pouvons donc utiliser les valeurs pour une distribution normale.
La valeur z d’un intervalle de confiance à 95 % est de 1,96 pour la distribution normale (tirée des tableaux statistiques standard).
En utilisant la formule ci-dessus, l’intervalle de confiance à 95 % est donc :
$$$159,1 \pm 1,96 \frac{(25,4)}{\sqrt 40}$
En effectuant ce calcul, nous constatons que l’intervalle de confiance est de 151,23-166,97 cm. Il est donc raisonnable de dire que nous avons donc 95 % de confiance que la moyenne de la population se situe dans cet intervalle.
Comprendre le score z ou la valeur z
Le score z est une mesure des écarts types par rapport à la moyenne. Dans notre exemple, nous savons donc que 95 % des valeurs se situeront à ± 1,96 écart-type de la moyenne :
Évaluer votre intervalle de confiance
En règle générale, un petit intervalle de confiance est préférable. L’intervalle de confiance se rétrécit à mesure que la taille de votre échantillon augmente, c’est pourquoi un échantillon plus grand est toujours préférable. Comme l’explique notre page sur l’échantillonnage et le plan d’échantillonnage, votre expérience idéale porterait sur l’ensemble de la population, mais cela n’est généralement pas possible.
Conclusion
Les intervalles de confiance et la signification sont des moyens standard de montrer la qualité de vos résultats statistiques. On attendra de vous que vous les rapportiez systématiquement lors de toute analyse statistique, et vous devrez généralement rapporter des chiffres précis. Cela garantira la validité et la fiabilité de votre recherche.