




Article de SQL Magazine 7 – SQL Server : Turbinez vos requêtes avec les vues indexées
Prenez votre question Marquez comme complétée Annotez
Le but de cet article est de présenter le concept des vues indexées de SQL Server et de montrer comment implémenter et utiliser ce type de vue pour optimiser les requêtes.
Concept de vue
Les vues sont également connues sous le nom de « tables virtuelles », car elles présentent une alternative à l’utilisation des tables pour accéder aux données. Une vue n’est rien d’autre qu’une instruction SELECT encapsulée dans un objet. La syntaxe pour créer une vue est comme indiqué dans le Listing 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Voir un exemple de création et d’utilisation de vue dans le Listing 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66Parmi les avantages de l’utilisation des vues, nous pouvons mentionner :
- Simplification du code : vous pouvez écrire des SELECT complexes une fois, les encapsuler dans la vue et les déclencher à partir de celle-ci, comme s’il s’agissait de n’importe quelle table ;
- Problèmes de sécurité : supposons que vous ayez des informations confidentielles dans certaines tables et que, par conséquent, vous vouliez que seuls certains utilisateurs y aient accès. Cependant, certaines colonnes de ces tableaux doivent être accessibles à tous les utilisateurs. Un moyen efficace de résoudre ce problème consiste à créer une vue et à masquer les colonnes sensibles. De cette manière, on peut supprimer les droits d’accès à la table d’origine et libérer l’accès à la vue;
- Possibilité d’optimisation des requêtes en mettant en œuvre des vues indexées.
Vues indexées en pratique
Les vues encapsulent les instructions SELECT, ce qui signifie que chaque fois qu’elles sont déclenchées, les instructions SELECT qui leur sont associées sont exécutées. Les vues ne créent pas de référentiel pour les données qu’elles renvoient (comme le fait la table). Eh bien, ce serait formidable si nous pouvions « matérialiser » dans une table le résultat de la commande SELECT trouvé dans la vue, en créant des index pour en faciliter l’accès. C’est ce que font les vues indexées. L’exécution d’un SELECT dans une vue indexée a le même effet que l’exécution d’un select dans une table conventionnelle.
Le but principal des vues indexées est d’augmenter les performances, et l’avantage de SQL Server est de permettre aux plans d’exécution de considérer la vue indexée comme un moyen d’accéder aux données, même si le nom de la vue n’était pas explicite dans la requête. Cela est possible dans l’édition Enterprise de SQL Server 2000, où l’optimiseur de commandes peut sélectionner les données directement dans la vue indexée (au lieu de sélectionner les données brutes existant dans la table), comme nous le verrons ensuite.
Créer une vue indexée pas à pas
- Configurer l’environnement, la première étape consiste à définir l’état de certains paramètres dans la session où l’on veut créer et utiliser la vue, car comme la vue indexée est « matérialisée » dans une table, rien ne peut interférer avec son résultat. Imaginez, par exemple, le scénario suivant :
- Un certain paramètre, qui affecte le résultat d’un SELECT (par exemple concat_null_yelds_null), est défini avant la création de la vue indexée ;
- La vue indexée est créée ; notez que le résultat de la vue sera ‘matérialisé’ sur le disque selon le paramètre défini à l’étape précédente ;
- Puis le paramètre est désactivé et la vue indexée est exécutée par l’utilisateur. Comme la vue a été matérialisée, nous obtiendrons un résultat incompatible avec la configuration actuelle.
Par exemple, le Listing 2 montre la différence dans le résultat d’une commande lorsque la propriété concat_null_yields_null est modifiée.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcImaginez ce qui se passerait si la vue indexée était créée avec la propriété concat_null_yields_null activée, mais que la session actuelle était avec cette propriété désactivée – le même SELECT conduirait à des résultats différents !
Ce problème a été résolu de manière simple – pour créer et utiliser des vues indexées, il est obligatoire de configurer l’environnement selon une liste de valeurs par défaut. De cette façon, il est impossible d’obtenir des résultats différents, car la vue ne fonctionnera tout simplement pas si l’un des paramètres est défini sur une valeur en dehors de la valeur par défaut.
Le tableau 1 affiche ces paramètres et leurs valeurs par défaut respectives.
| Réglage | Id (*) | Etat requis pour les vues indexées | Défaut de SQL Server 2000 | Défaut sur les connexions OLE DB (=ADO) ou ODBC | Défaut sur les connexions qui utilisent DB Library |
|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF |
| ANSI_PADDING | 16 | ON | ON | ON | OFF |
| ANSI_WARNING | 8 | ON | OFF | ON | OFF |
| ARITHABORT | 64 | ON | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF |
| IDENTIFIANT CITÉ | 256 | ON | OFF | ON | OFF |
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF |
(*) L’id est utilisé dans la commande sp_configure. Pour vérifier ce que fait chaque paramètre, lisez la section « Paramètres requis pour les vues indexées ». Il existe deux façons de modifier la valeur d’une configuration :
- Directement dans la session : exécuter la commande set ON | OFF
- Changer la valeur par défaut du serveur existant : exécuter sp_Configure ‘options utilisateur’, . Le numéro d’identification de chaque configuration est indiqué dans le tableau 1.
Note : AritHabort a l’id 64 et Quoted_Identifier a l’id 256. Pour lier, par exemple, Quoted_Identifier + AritHabort, nous exécuterions sp_cofigure, en passant comme paramètre le résultat de 64+256 (=320) : sp_configure ‘options utilisateur’, 320. Pour obtenir une liste complète des ids attribués à chaque configuration, allez à http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
Pour confirmer l’état de chacun des paramètres du tableau 1, utilisez la fonction SessionProperty(‘nom du paramètre’) ou la commande DBCC UserOptions.
De cette façon, définissez tous les paramètres selon la colonne ‘état requis pour les vues indexées’ dans le tableau 1 – si cela n’est pas fait, le serveur SQL ne vous permettra pas de créer/exécuter la vue indexée.
Création de la vue indexée
Nous allons créer une vue pour totaliser le montant quotidien vendu dans la table Détails de la commande, située dans la base de données NorthWind. Voir le Listing 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goNous devons observer quelques particularités lors de la création de vues indexées:
- La vue doit être déterministe. Une vue sera déterministe si nous n’utilisons que des fonctions déterministes dans son code. La même commande SELECT exécutée à plusieurs reprises sur une vue indexée (en considérant une base statique) ne peut pas donner des résultats différents. Les fonctions déterministes garantissent que le résultat d’une fonction restera inchangé, quel que soit le nombre de fois où elle est exécutée. La fonction DatePart, par exemple, est déterministe, puisqu’elle renvoie toujours le même résultat pour une date spécifique. La fonction getdate() renvoie une valeur différente à chaque fois qu’elle est exécutée. Pour obtenir la liste complète des fonctions déterministes de SQL Server 2000, allez à http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Vérifiez qu’il n’y a pas de restrictions syntaxiques. Les clauses, fonctions et types de requêtes énumérés ci-dessous ne peuvent pas intégrer le schéma d’une vue indexée :
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUM sur les colonnes qui autorisent les valeurs nulles
- DISTINCT
- FonctionROWSET
- Tables dérivées, auto-jointures, sous-requêtes, jointures externes
- DISTINCT
- UNION
- Float, text, ntext et image
- COMPUTE et COMPUTE BY
- HAVING, CUBE et ROLLUP
Il est nécessaire de créer les vues indexées avec SchemaBinding. Pour que le contenu de la vue reste cohérent, vous ne pouvez pas modifier la structure des tables à l’origine de la vue. Pour éviter ce genre de problème, il est obligatoire d’utiliser SchemaBinding lors de la création de vues indexées, car cette option ne permet pas de modifier la structure de la table sans avoir préalablement supprimé la vue.
Pour utiliser la clause GROUP BY, il est obligatoire d’inclure la fonction COUNT_BIG(*). La fonction count_big(*) fait la même chose que count(*), mais renvoie une valeur de type bigint (8 octets).
Toujours informer le propriétaire des objets référencés dans la vue indexée. Utilisez select * from dbo.Orders au lieu de select * from Orders, car il est possible d’avoir des tables portant le même nom mais ayant des propriétaires différents. L’option schemabinding étant obligatoire, SQL Server a besoin de la spécification exacte de l’objet pour freiner la modification du schéma.
Création d’un index cluster dans la vue (matérialisation)
La vue créée au point 2 ne se comporte pas encore comme une vue indexée, car le résultat de la commande select n’a pas été matérialisé dans une table. Vous pouvez confirmer cette affirmation en exécutant la commande sp_spaceused dans Query Analyzer, qui renvoie le nombre de lignes et l’espace utilisé par les tables (Listing 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Observez dans le Listing 5 que le traitement de la vue est purement logique, à tel point que la valeur de Physical Reads est nulle. Notez les valeurs enregistrées en lectures logiques et en lectures physiques (1672+0+4+0=1676) – nous utiliserons ces valeurs dans nos futures comparaisons.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Pour vérifier si la vue peut être indexée (matérialisée), c’est-à-dire si elle a été créée selon les normes et les paramètres requis pour les vues indexées, le résultat du SELECT suivant doit être égal à 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Confirmant les prérequis, nous pouvons maintenant créer l’index. La syntaxe a le même format que celui utilisé lors de la création d’index dans les tables conventionnelles :
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Notez que l’index cluster est nécessaire car il génère des pages de données. Vous pouvez créer des index non cluster dans les vues indexées seulement après avoir créé l’index cluster.
Maintenant le SELECT trouvé dans la vue a été matérialisé. ce qui peut être prouvé avec la commande sp_spaceused dans Query Analyzer (Listing 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBUtilisation des vues indexées
Une façon d’accéder à une vue indexée (ainsi qu’à une vue conventionnelle) est de référencer son nom dans la commande SELECT :
select * from vi_vendas_mesComparer le volume de pages déplacées dans la liste 5 (1672+4=1676) avec celui de la liste 7 (2+0=2). La différence est assez significative – la création de la vue indexée a réduit l’E/S totale requise de 1674 pages.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Regardons un autre exemple. La figure 1 montre le plan d’exécution d’une requête. Confirmez que la vue a été sélectionnée même si elle n’était pas présente dans la ligne SELECT.
Pendant la construction du plan d’exécution de la requête, l’optimiseur a constaté qu’il y avait déjà des données pré-sommées pour la requête dans vi_sales_mes et a choisi de sélectionner les données directement dans la vue indexée.
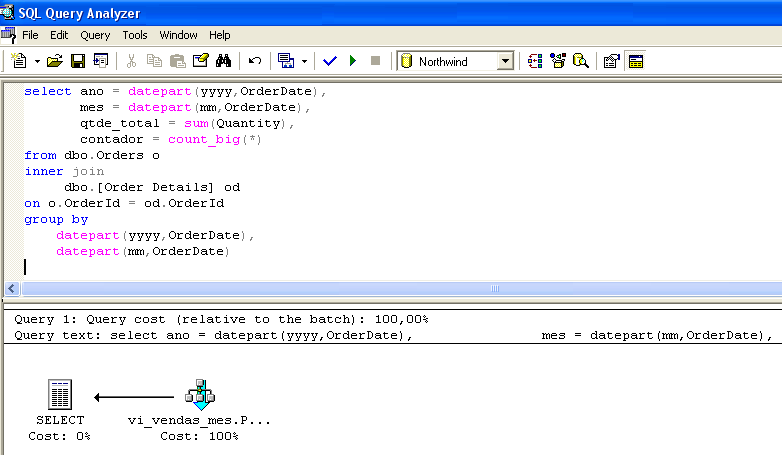
Notez que la requête exécutée dans la Figure 1 est identique à celle trouvée dans la vue vi_sales_mes. Cependant, l’accès à la vue par l’optimiseur est indépendant de la similarité entre la requête exécutée et la requête de la vue. La sélection de la vue indexée par le processeur de requêtes ne tient compte que du rapport coût-bénéfice. De cette façon, les requêtes exécutées n’ont pas besoin d’être identiques à la vue (observer la figure 3).
Cependant, il est nécessaire de suivre certaines règles pour que la vue indexée soit prise en compte par l’optimiseur de requêtes :
- La jointure présente dans la vue doit « être contenue » dans la requête : si la requête effectue une jointure entre les tables A et B, et que la vue effectue une jointure entre A et C, la vue ne sera pas déclenchée dans le plan d’exécution. Cependant, si la requête effectue une jointure entre A,B et C, la vue peut être déclenchée.
- Les conditions définies dans la requête doivent correspondre aux conditions de la vue : dans le SELECT de la figure 2, la vue indexée vi_sales_mes ne sera pas prise en compte car la clause where n’était pas présente dans le code de la vue, ce qui a entraîné le calcul des lignes avec Quantité <= 5 dans la jointure.
En revanche, si la requête comporte la condition where où sum(Quantité) > 5, la vue vi_sales_mes sera considérée dans le plan d’exécution, car la condition de la requête est un sous-ensemble du SELECT présent dans la vue.
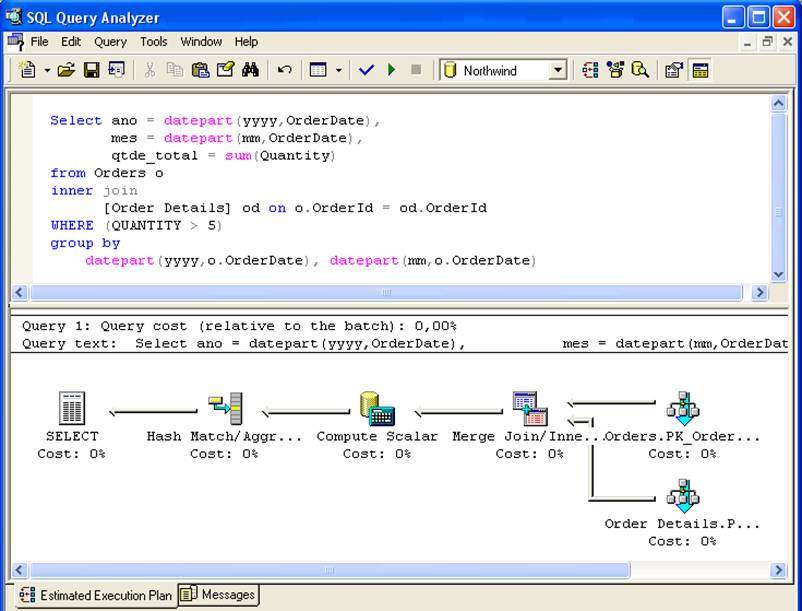
Les colonnes ayant des fonctions d’agrégation dans la requête doivent « être contenues » dans la définition de la vue : si la vue renvoie la colonne qtde=somme(Quantité) et que la requête a une colonne vlr_unit=somme(PrixUnité), la vue ne sera pas prise en compte.
La figure 3 montre une commande SELECT qui permet de prouver l’intelligence de l’optimiseur de commandes – le calcul AVG(Quantité) a été remplacé par la division entre SUM(Quantité) / Count_Big(*), représentée par l’icône Compute Scalar. Le prédicat where sum(Quantity) > 1500 (représenté par l’icône Filtre) est également considéré.
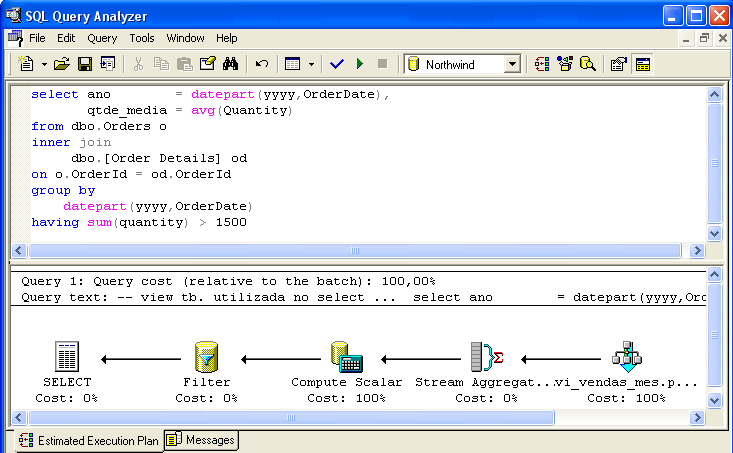
Considérations générales sur l’utilisation des vues indexées:
- Les vues indexées peuvent être créées dans n’importe quelle version de SQL Server 2000. Cependant, ce n’est que dans la version Enterprise Edition qu’ils seront automatiquement sélectionnés par l’optimiseur de requêtes.
- Dans les versions autres que Enterprise, vous devez utiliser l’indice NoExpand pour accéder à la vue indexée comme une table conventionnelle. Si NoExpand n’est pas employé, la vue indexée sera considérée comme une vue « normale ».
Note : L’indice Expand fait l’inverse de NoExpand : il traite la vue indexée comme une vue « normale », ce qui oblige SQL Server à exécuter l’instruction SELECT pendant la phase d’exécution.
- La maintenance d’une vue indexée est automatique (comme pour les index) ; elle ne nécessite aucune synchronisation supplémentaire. Par sa propre caractéristique (elle stocke généralement des données pré-sommaires), sa mise à jour tend à être un peu plus lente que celle des index conventionnels.
- L’utilisation des vues indexées dans les bases OLTP requiert de la prudence, car bien qu’elles présentent de grandes performances dans les requêtes, elles provoquent des surcharges dans les processus qui modifient les tables liées dans la vue. Dans les situations où des performances d’écriture élevées sont requises, avec des mises à jour fréquentes, la création de vues indexées n’est pas recommandée.
- Comme il le fait avec les index, l’optimiseur analysera le code des vues dans les versions Enterprise dans le cadre du processus de choix du meilleur plan d’exécution pour une requête. Cependant, s’il existe de nombreuses vues indexées susceptibles d’être exécutées pour la même requête, il peut y avoir une augmentation substantielle de ce temps de choix car toutes les vues seront analysées. Par conséquent, faites preuve de bon sens lors de la mise en œuvre des vues.
Paramètres requis pour les vues indexées
ANSI_NULLS
Définit la façon dont les comparaisons avec des valeurs nulles sont effectuées (Listing 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Détermine comment les colonnes char, varchar, binaire et varbinaire doivent être stockées lorsque leur contenu est inférieur à la taille définie dans la structure de la table. La valeur par défaut de SQL Server 2000 est de conserver l’ansi_padding (=ON) ; dans cette condition, les règles suivantes s’appliquent :
- Lors de la mise à jour des colonnes de caractères, des espaces blancs seront ajoutés à la fin de la chaîne si elle est inférieure à la taille définie dans la structure de la colonne. La même règle s’applique aux colonnes binaires (dans ce cas, l’espace est rempli par une séquence de zéros)
- Les colonnesarchar ou varbinaires ne suivent pas la règle ci-dessus : elles conservent toujours leur taille initiale.
ARITHABORT
Lorsqu’elle est activée, termine l’exécution de la requête lors de la rencontre d’une division par zéro ou d’un certain type de dépassement.
QUOTED_IDENTIFIER
Lorsqu’elle est activée, permet l’utilisation de guillemets doubles pour spécifier les noms de tables, de colonnes, etc. – De cette façon, ces noms peuvent avoir des espaces et ou des caractères spéciaux.
CONCAT_NULL_YELDS_NULL
Contrôle le résultat de la concaténation de chaînes de caractères avec des valeurs nulles. Lorsqu’elle est activée, détermine que cette jointure doit retourner une valeur nulle ; sinon, elle retournera la chaîne de caractères elle-même.
ANSI_WARNINGS
Lorsqu’elle est activée, détermine la génération de messages d’erreur lorsque :
- vous utilisez des fonctions de compression et que des valeurs nulles sont trouvées dans la plage de requête ;
- des divisions par zéro ou un dépassement arithmétique sont trouvés.
NUMERIC_ROUNDABORT
Contrôle la façon dont SQL Server doit procéder lorsqu’il rencontre une perte de précision numérique dans les opérations arithmétiques. Si le paramètre est activé et qu’une variable avec une précision de deux décimales reçoit une valeur avec trois décimales, l’opération sera interrompue. Si le paramètre est désactivé, la valeur sera tronquée à deux décimales.
Conclusion
En matière d’optimisation des requêtes, les vues indexées sont un bon choix pour tirer parti des performances. Par conséquent, évaluez soigneusement les requêtes qui traitent des résumés et qui sont exécutées avec une certaine fréquence et optez pour la création de vues indexées. Le résultat en vaut la peine !