




Enterprise Data Warehouse : Concepts, architecture et composants
Temps de lecture : 12 minutes
Tout au long de la journée, nous prenons de nombreuses décisions en nous appuyant sur des expériences antérieures. Notre cerveau stocke des trillions de bits de données sur des événements passés et exploite ces souvenirs chaque fois que nous sommes confrontés à la nécessité de prendre une décision. Comme les gens, les entreprises génèrent et collectent des tonnes de données sur le passé. Et ces données peuvent être utilisées pour prendre de meilleures décisions.
Alors que notre cerveau sert à la fois à traiter et à stocker, les entreprises ont besoin de multiples outils pour travailler avec les données. Et l’un des plus importants est un entrepôt de données.
Dans cet article, nous allons aborder ce qu’est un entrepôt de données d’entreprise, ses types et fonctions, et comment il est utilisé dans le traitement des données. Nous définirons en quoi les entrepôts d’entreprise sont différents des entrepôts habituels, quels types d’entrepôts de données existent, et comment ils fonctionnent. L’objectif est de fournir des informations sur la valeur commerciale de chaque approche architecturale et conceptuelle de la construction d’un entrepôt.
Qu’est-ce qu’un entrepôt de données d’entreprise?
Si vous savez ce qu’est un téraoctet, vous serez probablement impressionné par le fait que Netflix avait environ 44 téraoctets de données dans son entrepôt en 2016. Cette taille suffit à expliquer pourquoi nous l’appelons un entrepôt, et non une simple base de données. Commençons donc par les bases.
Un entrepôt de données d’entreprise (EDW) est une forme de référentiel d’entreprise qui stocke et gère toutes les données commerciales historiques d’une entreprise. Ces informations proviennent généralement de différents systèmes comme les ERP, les CRM, les enregistrements physiques et autres fichiers plats. Pour préparer les données en vue d’une analyse ultérieure, elles doivent être placées dans un lieu de stockage unique. De cette façon, différentes unités commerciales peuvent l’interroger et analyser les informations sous plusieurs angles.
Avec un entrepôt de données, une entreprise peut gérer d’énormes ensembles de données, sans avoir à administrer plusieurs bases de données. Une telle pratique constitue un moyen pérenne de stocker des données pour la business intelligence (BI), qui est un ensemble de méthodes/technologies permettant de transformer des données brutes en informations exploitables. L’EDW en étant une partie importante, le système s’apparente à un cerveau humain stockant des informations, mais sous stéroïdes.
Enterprise data warehouse vs data warehouse habituel : quelle est la différence ?
Tout entrepôt de données est une base de données toujours connectée aux sources de données brutes via des outils d’intégration de données d’un côté et des interfaces analytiques de l’autre. Si c’est le cas, pourquoi isoler la forme entreprise pour en discuter ?
Tout entrepôt fournit un stockage qui dispose de mécanismes pour transformer les données, les déplacer et les présenter à l’utilisateur final. La différence entre un entrepôt de données habituel et un entrepôt d’entreprise réside dans sa diversité architecturale et ses fonctionnalités beaucoup plus larges. En raison de leur structure complexe et de leur taille, les EDW sont souvent décomposés en bases de données plus petites, de sorte que les utilisateurs finaux sont plus à l’aise pour interroger ces petites bases de données. Compte tenu de cela, nous nous concentrons sur un entrepôt d’entreprise pour couvrir tout le spectre des fonctionnalités.
Cependant, la taille d’un entrepôt ne définit pas sa complexité technique, les exigences en matière de capacités analytiques et de reporting, le nombre de modèles de données et les données elles-mêmes. Ainsi, pour comprendre ce qui fait d’un entrepôt un entrepôt, plongeons dans ses concepts et fonctions de base.
Concepts et fonctions de l’entrepôt de données d’entreprise
Avec toutes les cloches et les sifflets, au cœur de chaque entrepôt se trouvent des concepts et des fonctions de base. Ces piliers définissent un entrepôt en tant que phénomène technologique :
Sert de stockage ultime. Un entrepôt de données d’entreprise est un référentiel unifié pour toutes les données commerciales de l’entreprise qui se produisent jamais dans l’organisation.
Reflet des données sources. L’EDW s’approvisionne en données à partir de ses espaces de stockage d’origine comme Google Analytics, les CRM, les dispositifs IoT, etc. Si les données sont dispersées dans plusieurs systèmes, elles sont ingérables. Ainsi, l’objectif de l’EDW est de fournir la ressemblance des données source originales dans un référentiel unique. Comme il y a toujours de nouvelles données pertinentes générées à l’intérieur et à l’extérieur de l’entreprise, le flux de données nécessite une infrastructure dédiée pour les gérer avant qu’elles n’entrent dans un entrepôt.
Stocker des données structurées. Les données stockées dans un EDW sont toujours normalisées et structurées. Cela permet aux utilisateurs finaux de les interroger via des interfaces de BI et de former des rapports. Et c’est ce qui différencie un entrepôt de données d’un lac de données. Les lacs de données sont utilisés pour stocker des données non structurées à des fins analytiques. Mais contrairement aux entrepôts, les lacs de données sont davantage utilisés par les ingénieurs/scientifiques de données pour travailler avec de grands ensembles de données brutes.
Données orientées sujet. L’objectif principal d’un entrepôt est constitué de données commerciales qui peuvent se rapporter à différents domaines. Pour comprendre à quoi les données se rapportent, elles sont toujours structurées autour d’un sujet spécifique appelé modèle de données. Un exemple de sujet peut être une région de vente ou les ventes totales d’un article donné. De plus, des métadonnées sont ajoutées pour expliquer en détail d’où provient chaque information.
Dépendant du temps. Les données collectées sont généralement des données historiques, car elles décrivent des événements passés. Pour comprendre quand et pendant combien de temps une certaine tendance a eu lieu, la plupart des données stockées sont généralement divisées en périodes de temps.
Non volatile. Une fois placées dans un entrepôt, les données n’en sont jamais effacées. Les données peuvent être manipulées, modifiées ou mises à jour en raison de changements de source, mais elles ne sont jamais destinées à être effacées, du moins par les utilisateurs finaux. Comme nous parlons de données historiques, les suppressions sont contre-productives à des fins analytiques. Pourtant, des révisions générales peuvent avoir lieu une fois en quelques années pour se débarrasser des données non pertinentes.
Considérant les principes de base, nous allons examiner les types de mise en œuvre des EDW.
Types d’entrepôts de données
Considérant les fonctions de l’EDW, il y a toujours une place pour la discussion sur la façon de le concevoir techniquement. Dans le cas du stockage et du traitement des données, ils sont spécifiques et distincts à différents types d’entreprises. Selon la quantité de données, la complexité analytique, les questions de sécurité et le budget, bien sûr, il y a toujours une option sur la façon de configurer votre système.
Entrepôt de données classique
Un stockage unifié qui a son matériel et son logiciel dédiés est considéré comme une variante classique pour un EDW. Avec le stockage physique, vous n’avez pas besoin de mettre en place des outils d’intégration de données entre plusieurs bases de données. Au lieu de cela, l’EDW peut être connecté à des sources de données via des API afin d’obtenir constamment des informations et de les transformer au cours du processus. Ainsi, tout le travail est effectué soit dans la zone de transit (l’endroit où les données sont transformées avant d’être chargées dans l’EDW), soit dans l’entrepôt lui-même.
Un entrepôt de données classique est considéré comme superlatif à un entrepôt virtuel (que nous abordons ci-dessous), car il n’y a pas de couche d’abstraction supplémentaire. Il simplifie le travail des ingénieurs de données et permet de gérer plus facilement le flux de données du côté du prétraitement, ainsi que le reporting proprement dit. Les inconvénients de l’entrepôt classique dépendent de la mise en œuvre réelle, mais pour la plupart des entreprises, ce sont :
- Une infrastructure technologique coûteuse, à la fois matérielle et logicielle ;
- L’embauche d’une équipe d’ingénieurs de données et de spécialistes DevOps pour mettre en place et maintenir l’ensemble de la plateforme de données.
Quand utiliser : approprié pour les organisations de toutes tailles qui veulent traiter leurs données et les exploiter. Les entrepôts classiques permettent de se transformer en différents styles architecturaux de la plate-forme de données, ainsi que d’augmenter et de diminuer l’échelle à dessein.
Entrepôt de données virtuel
Un entrepôt de données virtuel est un type d’EDW utilisé comme alternative à un entrepôt classique. Essentiellement, il s’agit de plusieurs bases de données connectées virtuellement, de sorte qu’elles peuvent être interrogées comme un seul système.
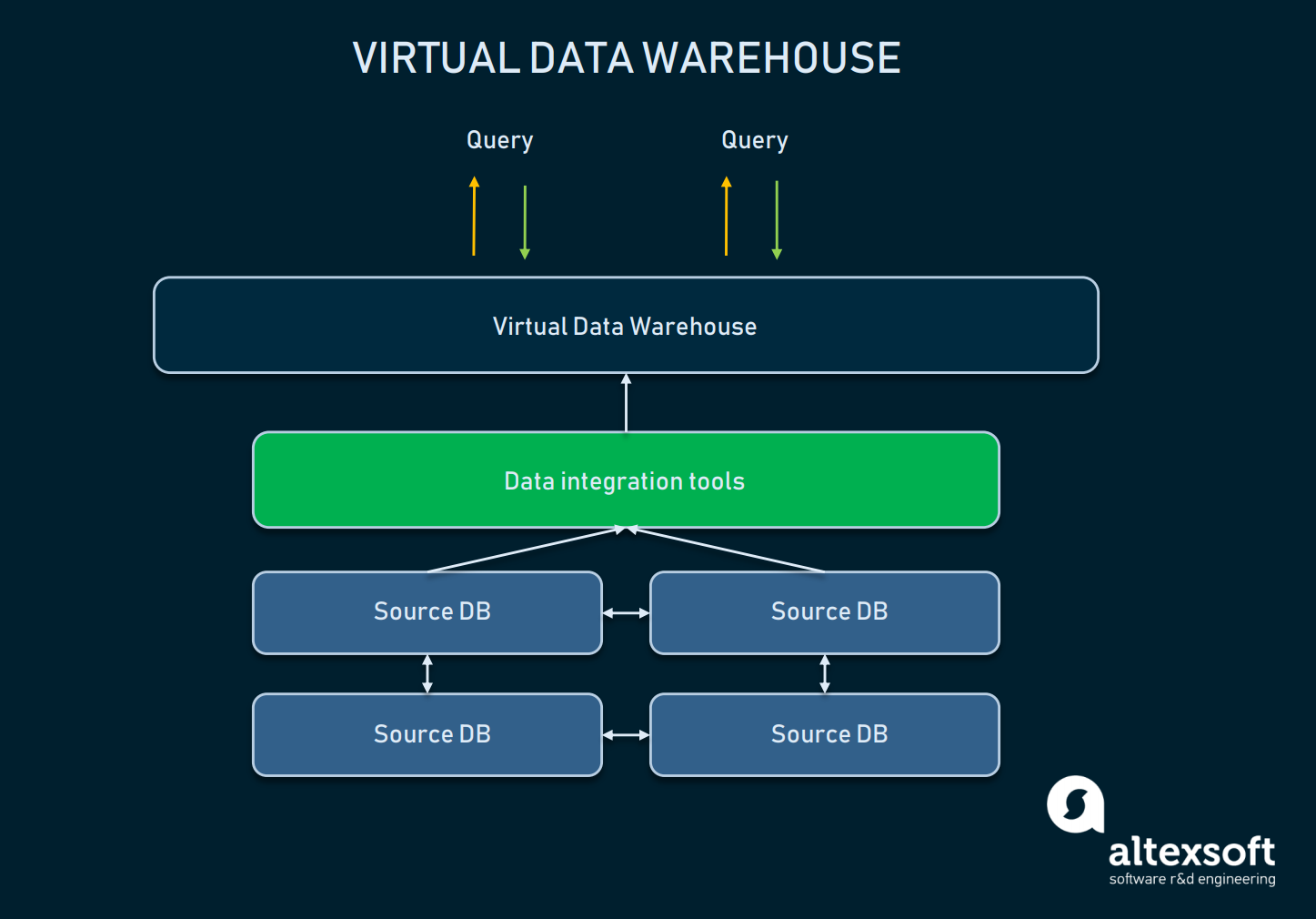
Un schéma de relations entre l’abstraction du DW virtuel et les bases de données sources
Une telle approche permet aux organisations de rester simples : Les données peuvent rester dans leurs sources, mais peuvent toujours être tirées à l’aide d’outils analytiques. Les entrepôts virtuels peuvent être utilisés si vous ne voulez pas vous embêter avec toute l’infrastructure sous-jacente, ou si les données dont vous disposez sont facilement gérables telles quelles. Cependant, une telle approche présente de nombreux inconvénients :
- Des bases de données multiples nécessiteront une maintenance et des coûts logiciels et matériels constants.
- Les données stockées dans un DW virtuel nécessitent toujours un logiciel de transformation pour les rendre digestes pour les utilisateurs finaux et les outils de reporting.
- Les requêtes de données complexes peuvent prendre trop de temps, car les éléments de données requis peuvent être placés dans deux bases de données distinctes.
Quand utiliser : convient aux entreprises qui ont des données brutes sous une forme standardisée qui ne nécessitent pas d’analyses complexes. Il convient également aux organisations qui n’utilisent pas systématiquement la BI ou qui veulent s’y mettre.
Cloud Data Warehouse
Depuis une décennie, les technologies cloud/cloudless sont devenues davantage une norme pour la mise en place de technologies au niveau des organisations. Vous trouverez sur le marché d’innombrables fournisseurs qui proposent un entreposage en tant que service. Pour n’en citer que quelques-uns :
- Amazon Redshift/ Page de tarification
- IBM Db2/ Page de tarification
- Google BigQuery/ Page de tarification
- Snowflake/ Page de tarification
- Microsoft SQL Data Warehouse/ Page de tarification
Tous les fournisseurs mentionnés offrent un entreposage entièrement géré, entrepôts évolutifs entièrement gérés dans le cadre de leurs outils de BI, ou se concentrent sur l’EDW en tant que service autonome, comme le fait Snowflake. Dans ce cas, l’architecture d’entrepôt en nuage présente les mêmes avantages que tout autre service en nuage. Son infrastructure est maintenue pour vous, ce qui signifie que vous n’avez pas besoin de mettre en place vos propres serveurs, bases de données et outils pour la gérer. Le prix d’un tel service dépendra de la quantité de mémoire requise, et de la quantité de capacités de calcul pour les requêtes.
Le seul aspect qui pourrait vous préoccuper en termes de plateforme d’entrepôt en nuage est la sécurité des données. Les données de votre entreprise sont une chose sensible. Vous voulez donc vérifier si le fournisseur que vous avez choisi est digne de confiance pour éviter les brèches. Cela ne signifie pas nécessairement qu’un entrepôt sur site est plus sûr, mais dans ce cas, la sécurité de vos données est entre vos mains.
Quand utiliser : Les plateformes cloud sont un excellent choix pour les organisations de toute taille. Si vous avez besoin que tout soit mis en place pour vous, y compris l’intégration de données gérée, la maintenance DW et le support BI.
Architecture d’entrepôt de données d’entreprise
Bien qu’il existe de nombreuses approches architecturales qui étendent les capacités de l’entrepôt d’une manière ou d’une autre, nous nous concentrerons sur les plus essentielles. Sans plonger dans trop de détails techniques, l’ensemble du pipeline de données peut être divisé en trois couches :
- Couche de données brutes (sources de données)
- Entrepôt et son écosystème
- Interface utilisateur (outils analytiques)
L’outillage qui concerne l’Extraction, la Transformation et le Chargement des données dans un entrepôt est une catégorie d’outils distincte appelée ETL. De même, sous l’égide de l’ETL, les outils d’intégration de données effectuent des manipulations avec les données avant de les placer dans un entrepôt. Ces outils opèrent entre une couche de données brutes et un entrepôt.
Lorsque les données sont chargées dans un entrepôt, elles peuvent également être transformées. Ainsi, l’entrepôt nécessitera certaines fonctionnalités de nettoyage/standardisation/dimensionnement. Ces facteurs et d’autres détermineront la complexité de l’architecture. Nous examinerons l’architecture EDW du point de vue des besoins organisationnels croissants.
Architecture à un niveau
Du fait que l’intégration des données est bien configurée, nous pouvons choisir notre entrepôt de données. Dans la plupart des cas, un entrepôt de données est une base de données relationnelle avec des modules pour permettre des données multidimensionnelles, ou un entrepôt qui peut séparer certaines informations spécifiques au domaine pour un accès plus facile. Dans sa forme la plus primitive, l’entrepôt peut avoir juste une architecture à un seul niveau.
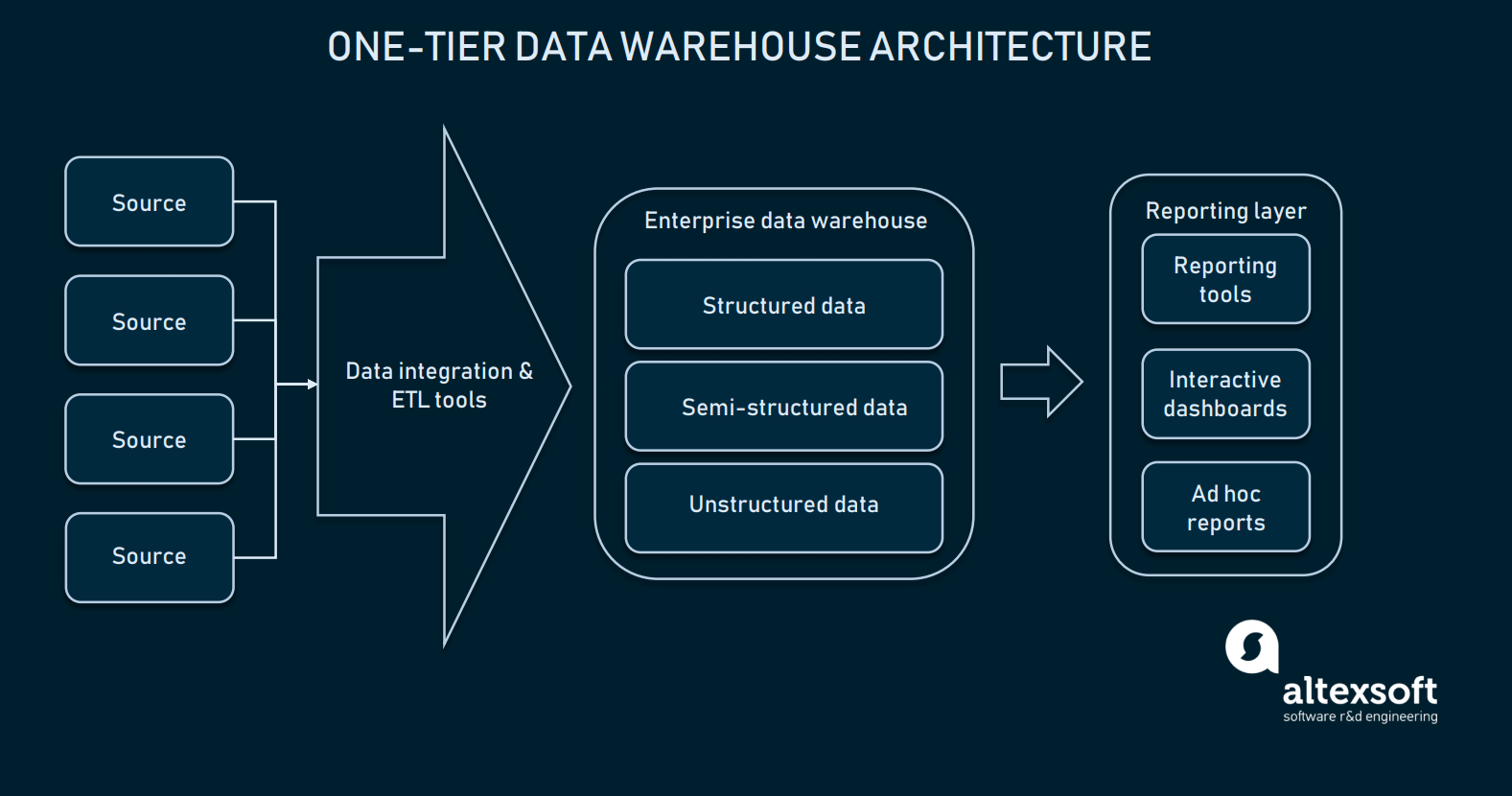
La couche de reporting est connectée directement avec l’ensemble de la base de données de l’EDW
Une architecture à un seul niveau pour l’EDW signifie que vous avez une base de données directement connectée avec les interfaces analytiques où l’utilisateur final peut faire des requêtes. La mise en place de la connexion directe entre un EDW et les outils analytiques entraîne plusieurs défis :
- Traditionnellement, vous pouvez considérer votre stockage comme un entrepôt à partir de 100 Go de données. Le fait de travailler directement avec celui-ci peut entraîner des résultats de requêtes désordonnés, ainsi qu’une faible vitesse de traitement.
- L’interrogation des données directement à partir du DW peut nécessiter une saisie précise, afin que le système soit en mesure de filtrer les données non nécessaires. Ce qui rend le traitement des outils de présentation un peu difficile.
- Une flexibilité limitée/des capacités analytiques existent.
En outre, l’architecture à un seul niveau fixe certaines limites à la complexité des rapports. Une telle approche est rarement utilisée pour les plateformes de données à grande échelle, en raison de sa lenteur et de son imprévisibilité. Pour effectuer des requêtes de données avancées, un entrepôt peut être étendu avec des instances de bas niveau qui facilitent l’accès aux données.
Architecture à deux niveaux (couche data mart)
Dans l’architecture à deux niveaux, un niveau data mart est ajouté entre l’interface utilisateur et l’EDW. Un data mart est un référentiel de bas niveau qui contient des informations spécifiques à un domaine. En termes simples, il s’agit d’une autre base de données de plus petite taille qui étend l’EDW avec des informations dédiées à vos départements de vente/opérationnels, au marketing, etc.
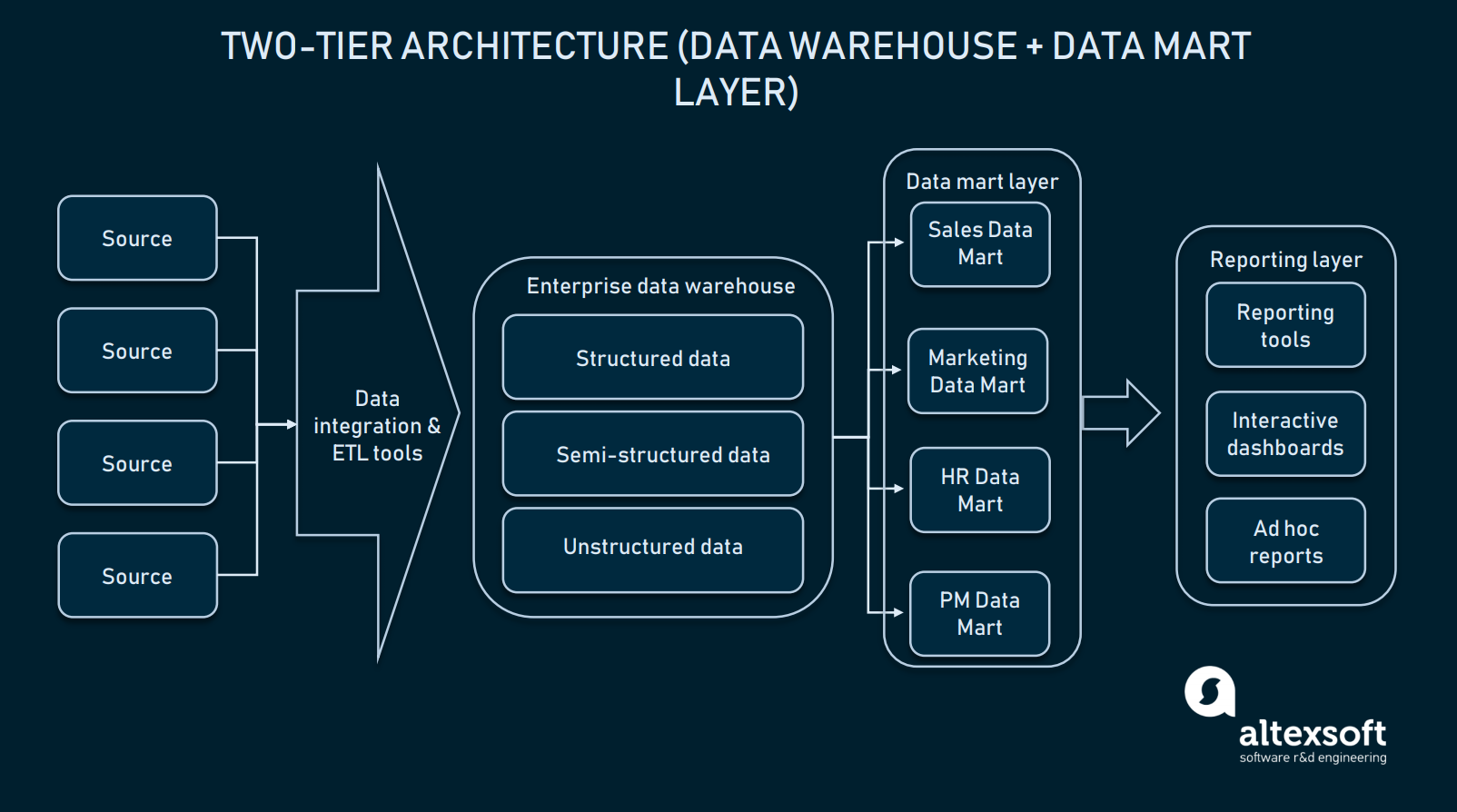
Dans l’architecture à deux niveaux, un EDW est étendu par des marts de données pour fournir des données spécifiques au domaine
Créer une couche de marts de données nécessitera des ressources supplémentaires pour établir le matériel et intégrer ces bases de données avec le reste de la plate-forme de données. Mais, une telle approche résout le problème de l’interrogation : Chaque département accèdera plus facilement aux données requises car un mart donné ne contiendra que des informations spécifiques au domaine. En outre, les marts de données limiteront l’accès aux données pour les utilisateurs finaux, ce qui rendra l’EDW plus sûr.
Architecture à trois niveaux (Traitement analytique en ligne)
Au-dessus de la couche des marts de données, les entreprises utilisent également des cubes de traitement analytique en ligne (OLAP). Un cube OLAP est un type spécifique de base de données qui représente les données de plusieurs dimensions. Alors que les bases de données relationnelles représentent les données en seulement deux dimensions (pensez à Excel ou Google Sheets), l’OLAP vous permet de compiler des données dans plusieurs dimensions et de vous déplacer entre les dimensions.
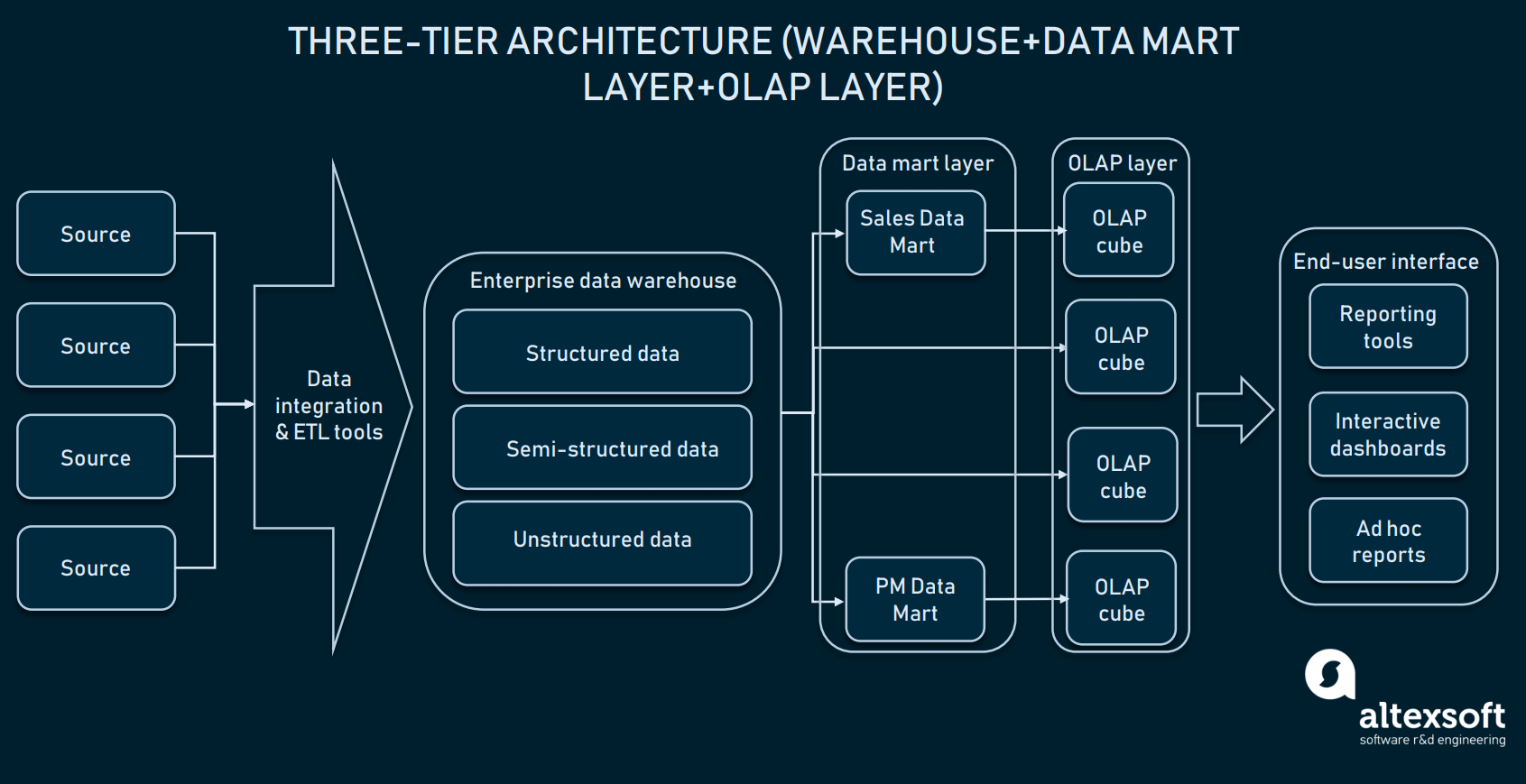
La couche des cubes OLAP peut s’approvisionner en informations à partir de marts distribués ou directement à partir de l’EDW
C’est assez difficile à expliquer avec des mots, alors regardons cet exemple pratique de ce à quoi peut ressembler un cube.
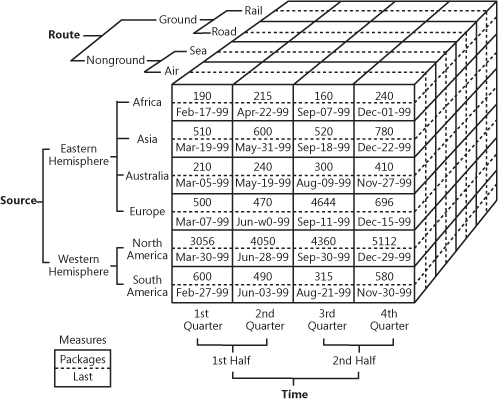
CubeOLAP démontrant des données de ventes multidimensionnelles
Source : oreilly.com
Donc, comme vous pouvez le voir, un cube ajoute des dimensions aux données. Vous pouvez l’imaginer comme plusieurs tableaux Excel combinés entre eux. L’avant du cube est le tableau bidimensionnel habituel, où la région (Afrique, Asie, etc.) est spécifiée verticalement, tandis que les numéros de vente et les dates sont écrits horizontalement. La magie commence lorsque l’on regarde la facette supérieure du cube, où les ventes sont segmentées par routes et où la partie inférieure spécifie la période de temps. C’est ce qu’on appelle des données multidimensionnelles.
La valeur commerciale de l’OLAP est qu’elle permet aux utilisateurs de découper les données en tranches pour compiler des rapports détaillés. Tant que les cubes sont optimisés pour fonctionner avec les entrepôts, ils peuvent être utilisés à la fois directement avec un EDW pour donner accès à toutes les données de l’entreprise ou avec chaque data mart spécifiquement. En termes d’implémentation, presque tous les fournisseurs d’entrepôts offrent OLAP comme un service. A titre d’exemple, consultez la documentation de Microsoft sur leur offre OLAP.
Sur ce point, nous avons abordé une conception de haut niveau d’un EDW appliqué aux besoins organisationnels. Nous allons maintenant approfondir les composants techniques qu’un entrepôt peut inclure.
Entrepôt de données vs lac de données vs Data Mart
En parlant d’architecture de stockage de données, nous devons mentionner des options telles que l’utilisation d’un data mart ou d’un lac de données au lieu d’un entrepôt. Fréquemment confondus, nous allons développer les définitions.
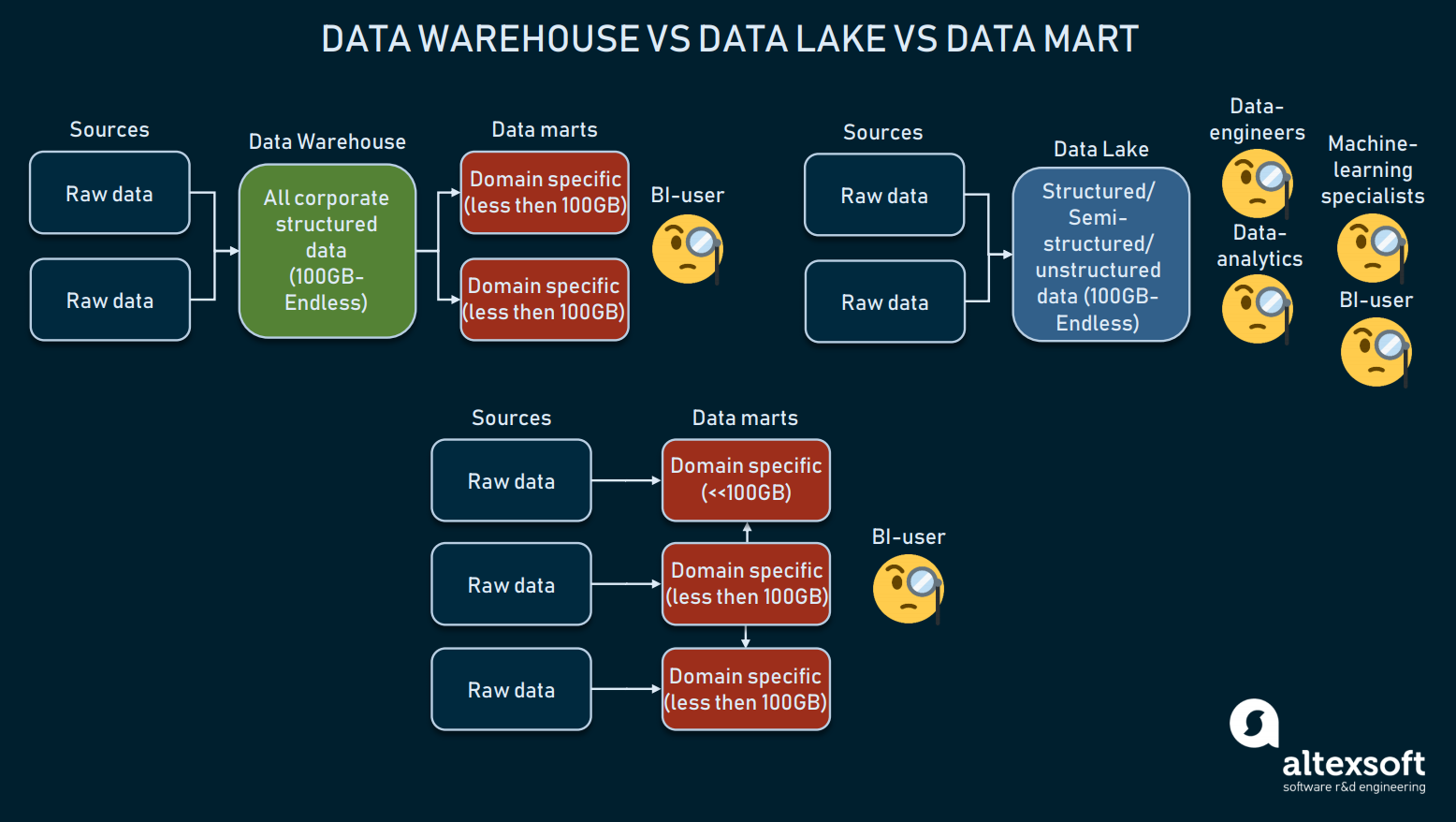
La comparaison de trois formes de stockage de données
Les entrepôts de données sont destinés à stocker des données structurées, afin que les outils de requêtes et les utilisateurs finaux puissent obtenir des résultats complets. Les entrepôts, principalement utilisés pour la BI, varient généralement en taille entre 100 Go et l’infini.
Les lacs de données, cependant, sont utilisés pour stocker principalement des données brutes ou mixtes. Ils sont souvent exploités à des fins d’apprentissage automatique, de big data ou de data mining. Au cours des deux dernières années, les lacs de données ont été utilisés pour la BI : les données brutes sont chargées dans un lac et transformées, ce qui constitue une alternative au processus ETL. Bien que cette approche ait ses avantages et ses inconvénients, les lacs de données peuvent être trop désordonnés pour atteindre des données structurées.
Puis nous avons les marts de données, qui peuvent également être utilisés comme une alternative au DW. Ces modèles (comme celui de Kimball) supposent l’utilisation de plusieurs data marts pour distribuer les informations par domaines et se connecter entre eux. Mais, en raison de leur petite taille (généralement moins de 100 Go), les data marts peuvent difficilement être utilisés par les entreprises. Plus souvent, les data marts sont utilisés pour segmenter un grand DW en d’autres plus exploitables.
Composants de l’entrepôt de données d’entreprise
Il y a beaucoup d’instruments utilisés pour mettre en place une plateforme d’entreposage. Nous aurons déjà mentionné la plupart d’entre eux, y compris un entrepôt lui-même. Alors, voyons à vol d’oiseau l’objectif de chaque composant et leurs fonctions.
Sources. C’est simple, les bases de données où les données brutes sont stockées.
Couche d’extraction, de transformation, de chargement (ETL) ou d’extraction, de chargement, de transformation (ELT). Ce sont les outils qui effectuent la connexion réelle avec les données sources, leur extraction et leur chargement à l’endroit où elles seront transformées. La transformation unifie le format des données. Les approches ETL et ELT diffèrent en ce sens que dans l’ETL, la transformation est effectuée avant l’EDW, dans une zone de transit. ELT est une approche plus moderne qui gère toute la transformation dans un entrepôt.
Zone de transit. Dans le cas de l’ETL, la staging area est l’endroit où les données sont chargées avant l’EDW. Ici, elles seront nettoyées et transformées selon un modèle de données donné. La zone de staging peut également inclure des outils pour la gestion de la qualité des données.
Base de données EDW. Les données sont finalement chargées dans l’espace de stockage. Dans les PUNR, il se peut qu’une transformation soit encore nécessaire ici. Mais, à ce stade, toutes les modifications générales seront appliquées, de sorte que les données seront chargées dans leur(s) modèle(s) final(aux). Comme nous l’avons mentionné, les entrepôts de données sont le plus souvent des bases de données relationnelles. Le DW comprendra également un système de gestion de base de données et un stockage supplémentaire pour les métadonnées.
Module de métadonnées. Pour faire simple, les métadonnées sont des données sur les données. Ce sont les explications qui donnent des indices aux utilisateurs/administrateurs sur le sujet/domaine auquel cette information se rapporte. Ces données peuvent être des méta techniques (par exemple, la source initiale), ou des méta commerciales (par exemple, la région de vente). Toutes les méta sont stockées dans un module séparé de l’EDW et sont gérées par un gestionnaire de métadonnées.
Couche de rapport. Ce sont les outils qui permettent aux utilisateurs finaux d’accéder aux données. Également appelée interface BI, cette couche servira de tableau de bord pour visualiser les données, former des rapports et tirer des éléments d’information distincts.
Pensée finale
Comprendre la chaîne d’outils qui transmet les données peut vous aider à déterminer ce qui correspond réellement aux exigences de votre plateforme de données. La planification de la mise en place d’un entrepôt peut prendre des années de planification et de tests, en raison de son ampleur dans une forme la plus basique.
En tant que propriétaire d’entreprise, vous pouvez être confus par le nombre d’options et de technologies utilisées, il est donc vital de consulter des experts dans le domaine de l’entreposage, de l’ETL et de la BI. Si les experts peuvent vous aider sur l’aspect technique, pour définir l’objectif commercial, parlez avec ceux qui utiliseront les données réelles dans leur travail.