




Introduction à la conception de bases de données
Identification des attributs
Les éléments de données que vous voulez enregistrer pour chaque entité sont appelés « attributs ».
A propos des produits que vous vendez, vous voulez savoir, par exemple, quel est le prix, quel est le nom du fabricant et quel est le numéro de type. Pour les clients, vous connaissez leur numéro de client, leur nom et leur adresse. Pour les magasins, vous connaissez le code de localisation, le nom et l’adresse. Pour les ventes, vous savez quand elles ont eu lieu, dans quel magasin, quels produits ont été vendus et le montant total de la vente. Pour le vendeur, vous connaissez son numéro de personnel, son nom et son adresse. Ce qui sera inclus précisément n’a pas encore d’importance, il ne s’agit encore que de ce que vous voulez sauver.
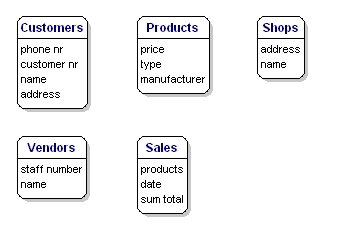
Figure 6 : Entités avec attributs.
Données dérivées
Les données dérivées sont des données qui sont dérivées des autres données que vous avez déjà sauvegardées. Dans ce cas, la » somme totale » est une donnée dérivée classique. Vous savez exactement ce qui a été vendu et ce que coûte chaque produit, vous pouvez donc toujours calculer à combien s’élève la somme totale des ventes. Donc vraiment il n’est pas nécessaire de sauvegarder la somme totale.
Alors pourquoi est-il sauvegardé ici ? Eh bien, parce que c’est une vente, et le prix du produit peut varier dans le temps. Un produit peut avoir un prix de 10 euros aujourd’hui et de 8 euros le mois prochain, et pour votre administration, vous devez savoir ce qu’il coûtait au moment de la vente, et la façon la plus simple de le faire est de le sauvegarder ici. Il y a beaucoup de façons plus élégantes, mais elles sont trop profondes pour cet article.
Présenter les entités et les relations : Diagramme entité-relation (ERD)
Le diagramme entité-relation (ERD) donne un aperçu graphique de la base de données. Il existe plusieurs styles et types de diagrammes ER. Une notation très utilisée est celle de la « patte d’oie », où les entités sont représentées par des rectangles et les relations entre les entités par des lignes entre les entités. Les signes à l’extrémité des lignes indiquent le type de relation. Le côté de la relation qui est obligatoire pour que l’autre existe est indiqué par un tiret sur la ligne. Les entités non obligatoires sont indiquées par un cercle. « Many » est indiqué par une « patte d’oie » ; la ligne de relation se divise en trois lignes.
Dans cet article, nous utilisons DeZign for Databases pour concevoir et présenter notre base de données.
Une relation obligatoire 1:1 est représentée comme suit:
Figure 7 : Relation obligatoire un à un.
Une relation obligatoire 1:N:
Figure 8 : relation obligatoire un à plusieurs.
Une relation M:N est:
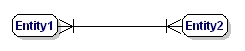
Figure 9 : Relation obligatoire de plusieurs à plusieurs.
Le modèle de notre exemple ressemblera à ceci:
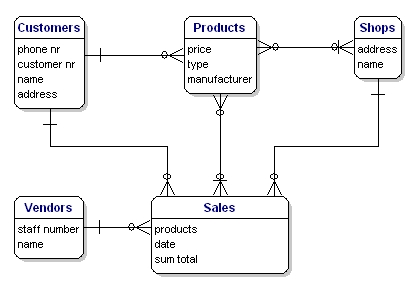
Figure 10 : Modèle avec des relations.
Assignation de clés
Clefs primaires
Une clé primaire (PK) est un ou plusieurs attributs de données qui identifient de manière unique une entité. Une clé qui se compose de deux attributs ou plus est appelée clé composite. Tous les attributs faisant partie d’une clé primaire doivent avoir une valeur dans chaque enregistrement (qui ne peut pas être laissée vide) et la combinaison des valeurs dans ces attributs doit être unique dans la table.
Dans l’exemple, il y a quelques candidats évidents pour la clé primaire. Les clients ont tous un numéro de client, les produits ont tous un numéro de produit unique et les ventes ont un numéro de vente. Chacune de ces données est unique et chaque enregistrement contiendra une valeur, donc ces attributs peuvent être une clé primaire. Souvent, une colonne entière est utilisée pour la clé primaire afin qu’un enregistrement puisse être facilement trouvé grâce à son numéro.
Les entités-liens font généralement référence aux attributs de clé primaire des entités qu’elles relient. La clé primaire d’une entité de lien est généralement une collection de ces attributs de référence. Par exemple, dans l’entité Sales_details, nous pourrions utiliser la combinaison des PK des entités sales et products comme PK de Sales_details. De cette façon, nous garantissons que le même produit (type) ne peut être utilisé qu’une seule fois dans la même vente. Plusieurs articles du même type de produit dans une vente doivent être indiqués par la quantité.
Dans l’ERD, les attributs de clé primaire sont indiqués par le texte ‘PK’ derrière le nom de l’attribut. Dans l’exemple seulement, l’entité ‘shop’ n’a pas de candidat évident pour la PK, nous allons donc introduire un nouvel attribut pour cette entité : shopnr.
Clefs étrangères
La clé étrangère (FK) dans une entité est la référence à la clé primaire d’une autre entité. Dans l’ERD, cet attribut sera indiqué par « FK » derrière son nom. La clé étrangère d’une entité peut également faire partie de la clé primaire, dans ce cas l’attribut sera indiqué par ‘PF’ derrière son nom. C’est généralement le cas avec les entités de liaison, car vous ne liez généralement deux instances qu’une seule fois ensemble (avec 1 vente, 1 seul type de produit est vendu 1 fois).
Si nous mettons toutes les entités de liaison, les PK et les FK dans l’ERD, nous obtenons le modèle comme indiqué ci-dessous. Veuillez noter que l’attribut ‘produits’ n’est plus nécessaire dans ‘Ventes’, car ‘produits vendus’ est maintenant inclus dans la table de liens. Dans la table de liens, un autre champ a été ajouté, ‘quantité’, qui indique combien de produits ont été vendus. Le champ ‘quantité’ a également été ajouté dans la table des stocks, pour indiquer combien de produits sont encore en magasin.
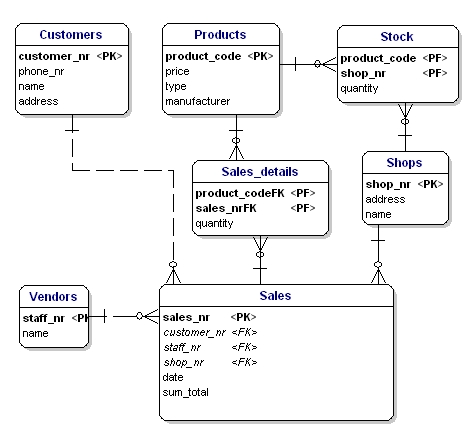
Figure 11 : clés primaires et clés étrangères.
Définir le type de données de l’attribut
Il est maintenant temps de déterminer quels types de données doivent être utilisés pour les attributs. Il existe un grand nombre de types de données différents. Quelques-uns sont standardisés, mais de nombreuses bases de données ont leurs propres types de données qui ont tous leurs propres avantages. Certaines bases de données offrent la possibilité de définir vos propres types de données, au cas où les types standard ne peuvent pas faire les choses dont vous avez besoin.
Les types de données standard que chaque base de données connaît, et qui sont les plus utilisés, sont : CHAR, VARCHAR, TEXT, FLOAT, DOUBLE et INT.
Texte:
- CHAR(longueur) – comprend le texte (caractères, chiffres, ponctuations…). Le CHAR a pour caractéristique de toujours sauvegarder un nombre fixe de positions. Si vous définissez un CHAR(10), vous pouvez sauvegarder jusqu’à dix positions maximum, mais si vous n’utilisez que deux positions, la base de données en sauvegardera quand même 10. Les huit positions restantes seront remplies par des espaces.
- VARCHAR(length) – comprend du texte (caractères, chiffres, ponctuation…). VARCHAR est le même que CHAR, la différence est que VARCHAR ne prend que l’espace nécessaire.
- TEXT – peut contenir de grandes quantités de texte. Selon le type de base de données, cela peut s’ajouter à des gigaoctets.
Nombres:
- INT – contient un nombre entier positif ou négatif. Beaucoup de bases de données ont des variations de l’INT, comme TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8. Ces variantes ne diffèrent de l’INT que par la taille du chiffre qu’elles contiennent. Un INT normal a une taille de 4 octets (INT4) et peut contenir des chiffres de -2147483647 à +2147483646, ou si vous le définissez comme UNSIGNED de 0 à 4294967296. L’INT8, ou BIGINT, peut avoir une taille encore plus grande, de 0 à 18446744073709551616, mais prend jusqu’à 8 octets d’espace disque, même s’il ne contient qu’un petit chiffre.
- FLOAT, DOUBLE – La même idée que INT, mais peut également stocker des nombres à virgule flottante. . Notez que cela ne fonctionne pas toujours parfaitement. Par exemple dans MySQL le calcul avec ces nombres à virgule flottante n’est pas parfait, (1/3)*3 résultera avec les flottants de MySQL en 0,9999999, pas 1.
Autres types:
- BLOB – pour les données binaires telles que les fichiers.
- INET – pour les adresses IP. Également utilisable pour les masques de réseau.
Pour notre exemple, les types de données sont les suivants :
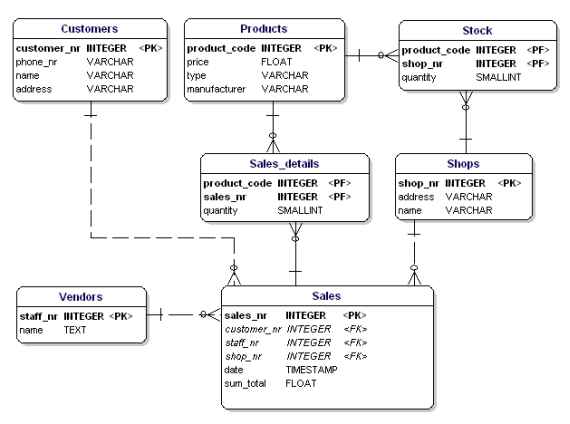
Figure 12 : Modèle de données affichant les types de données.
Normalisation
La normalisation rend votre modèle de données flexible et fiable. Elle génère quelques frais généraux car vous obtenez généralement plus de tables, mais elle vous permet de faire beaucoup de choses avec votre modèle de données sans avoir à l’ajuster. Vous pouvez en savoir plus sur la normalisation des bases de données dans cet article.
Normalisation, la première forme
La première forme de normalisation stipule qu’il ne peut y avoir de groupes de colonnes répétitifs dans une entité. Nous aurions pu créer une entité ‘ventes’ avec des attributs pour chacun des produits achetés. Cela ressemblerait à ceci:

Figure 13 : Pas dans la 1ère forme normale.
Ce qui ne va pas dans ce cas, c’est que maintenant seuls 3 produits peuvent être vendus. Si vous deviez vendre 4 produits, alors vous devriez commencer une deuxième vente ou ajuster votre modèle de données en ajoutant des attributs ‘product4’. Ces deux solutions ne sont pas souhaitées. Dans ces cas, vous devriez toujours créer une nouvelle entité que vous liez à l’ancienne via une relation un à plusieurs.
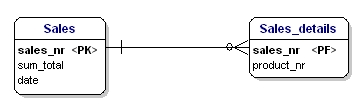
Figure 14 : Conformément à la 1ère forme normale.
Normalisation, la deuxième forme
La deuxième forme de normalisation stipule que tous les attributs d’une entité doivent dépendre entièrement de la clé primaire entière. Cela signifie que chaque attribut d’une entité ne peut être identifié qu’à travers la clé primaire entière. Supposons que nous ayons la date dans l’entité Sales_details:

Figure 15 : Pas dans la 2e forme normale.
Cette entité n’est pas selon la deuxième forme normale, car pour pouvoir rechercher la date d’une vente, je n’ai pas besoin de savoir ce qui est vendu (productnr), la seule chose dont j’ai besoin est le numéro de vente. Ce problème a été résolu en divisant les tables en ventes et en table Sales_details:
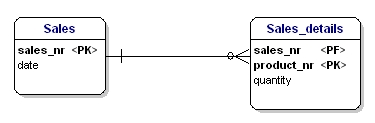
Figure 16 : Conformément à la 2e forme normale.
Maintenant chaque attribut des entités est dépendant de l’ensemble du PK de l’entité. La date est dépendante du numéro de vente, et la quantité est dépendante du numéro de vente et du produit vendu.
Normalisation, la troisième forme
La troisième forme de normalisation stipule que tous les attributs doivent dépendre directement de la clé primaire, et non des autres attributs. Cela semble être ce que la deuxième forme de normalisation déclare, mais dans la deuxième forme est en fait déclaré le contraire. Dans la deuxième forme de normalisation, vous pointez les attributs à travers la PK, dans la troisième forme de normalisation, chaque attribut doit être dépendant de la PK, et rien d’autre.

Figure 17 : Pas dans la 3ème forme normale.
Dans ce cas, le prix d’un produit en vrac dépend du numéro de commande, et le numéro de commande dépend du numéro de produit et du numéro de vente. Ceci n’est pas conforme à la troisième forme de normalisation. Encore une fois, le fractionnement des tables résout ce problème.
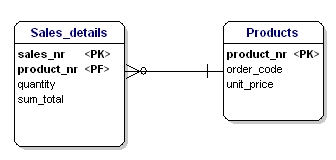
Figure 18 : En accord avec la 3ème forme normale.
Normalisation, plus de formes
Il existe d’autres formes de normalisation que les trois formes mentionnées ci-dessus, mais celles-ci ne présentent pas un grand intérêt pour l’utilisateur moyen. Ces autres formes sont hautement spécialisées pour certaines applications. Si vous vous en tenez aux règles de conception et à la normalisation mentionnées dans cet article, vous créerez une conception qui fonctionne très bien pour la plupart des applications.
Modèle de données normalisé
Si vous appliquez les règles de normalisation, vous constaterez que le ‘fabricant’ dans la table des produits devrait également être une table séparée :
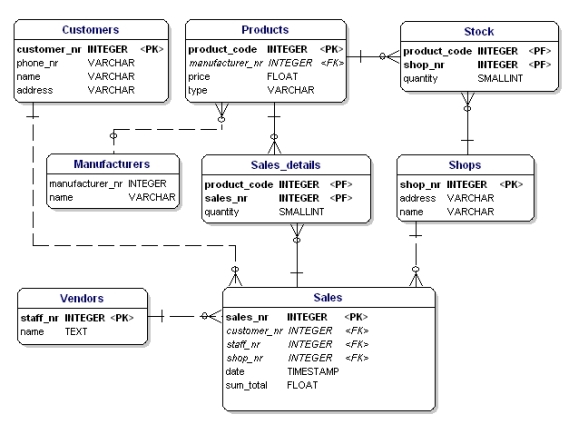
Figure 19 : Modèle de données selon la 1ère, 2ème et 3ème forme normale.