




世論調査会社の実力は? Five-Thirty-Eightのデータセットを分析する
老舗政治予測サイトFive-Thirty-Eightの世論調査員ランキングデータセットを分析します。

今年は選挙の年であり、選挙(大統領総選挙、下院・上院選挙)を巡る世論調査シーンが熱を帯びてきています。 ツイート、カウンターツイート、ソーシャルメディアでの争い、テレビでの果てしない評論活動など、これからますます盛り上がりを見せるでしょう。
すべての世論調査が同じ品質でないことは分かっているはずです。 では、どのように意味をなすのでしょうか。 データと分析を用いて、信頼できる世論調査機関を見極めるにはどうしたらよいでしょうか。

政治(およびスポーツ、社会現象、経済などいくつかの事柄)の予測分析の世界では、Five-Thirty-Eight は手強い名前です。
2008年初頭から、このサイトは現在の政治や政治ニュースにおける幅広いトピックについて記事(通常は統計情報の作成または分析)を公開しています。 ロックスターのデータ科学者であり統計学者であるネイト・シルバーが運営するこのサイトは、そのモデルが 50 州とコロンビア特別区のすべての勝者を正しく予測した 2012 年の大統領選挙の頃に、特に注目され広く知られるようになりました。
そして、「でも、2016年の選挙はどうなんだ」と嘲笑する前に、ドナルド・トランプの当選が統計モデリングの通常の誤差範囲内だったというこの記事を読むとよいでしょう。
より政治に関心のある読者のために、ここでは2016年の選挙に関する記事を一袋用意してくれています。
Data Science Practitioners should take a liking to Five-Thirty-Eight because it is not shy away from explaining their predictive models in terms of highly technical terms (at least complex enough for the layperson).

ここで、彼らは有名な t 分布を採用することについて話していますが、他のほとんどの投票集計会社はどこにでもある正規分布で満足しているかもしれません。
しかしながら、高度な統計モデリング技術を使用するだけではなく、シルバーのチームは、彼らのモデルが高い精度と信頼を維持できるよう、投票者評価という独自の方法論を誇っています。
Five-Thirty-Eight は、高度な専門用語(少なくとも素人には十分複雑)を使って予測モデルを説明することに躊躇しません。
世論調査員の格付けとランキング
この国には多数の世論調査会社が活動しています。 それらの質を読み、評価することは、非常に負担が大きく、骨折り損になりかねません。 このサイトにあるように、「世論調査を読むことは健康に害を及ぼす可能性がある」のです。 その症状には、選択すること、過信すること、ジャンクな数字に騙されること、判断を急ぐことが含まれます。 ありがたいことに、私たちには治療法があります” (出典)
世論調査がある。 そして、世論調査の世論調査がある。 それから、世論調査の重み付けされた世論調査がある。 とりわけ、統計的にモデル化され、動的に変化する重みを持つ投票の投票があります。
データサイエンティストとして聞いたことのある他の有名なランキング手法に見覚えがありませんか? Amazon の製品ランキングや Netflix の映画ランキング? おそらくそうです。
基本的に、Five-Thirty-Eight は、この評価/ランキング システムを使用して、世論調査結果に重みを付けています (高ランクな世論調査結果はより重要視され、そうなっています)。 また、各世論調査会社の結果の背後にある正確さと方法論を積極的に追跡し、年間を通じてランキングを調整します。 そして、世論調査の世論調査があります。 そして、世論調査の重み付けされた世論調査がある。 とりわけ、統計的にモデル化され、動的に変化する重みを持つ世論調査の世論調査があります。
彼らのランキング方法は、必ずしもサンプルサイズが大きい世論調査会社をより良いものとして評価しないことに注目するのが興味深い点です。 彼らのウェブサイトからの次のスクリーンショットは、それを明確に示しています。 Rasmussen ReportsやHarrisXなどの世論調査会社はサンプルサイズが大きいのですが、実際には、サンプルサイズが控えめなMarist CollegeがA+の評価を受けています。
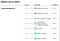
Fortunately, they also open-source their pollster ranking data (along with almost all of its other datasets) here on Github. そして、もしあなたが見栄えのするテーブルにしか興味がないのであれば、ここにあります。
- 世論調査会社の正確さと数値ランキングの相関はどうか
- 特定の世論調査会社を選ぶことに党派的な偏りがあるのか(ほとんどの場合、民主党寄りか共和党寄りに分類されます)
- トップレートの世論調査会社は誰なのか、などなど、データ科学者として、生のデータを深く調べて理解したいと思うこともあることでしょう。 彼らは多くの世論調査を実施しているのか、それとも選択的なのか。
このような洞察を得るために、データセットの分析を試みました。 コードとその結果を見てみましょう。
分析
この Jupyter Notebook は私の Github リポジトリにあります。
ソース
まず始めに、次のように、彼らのGithubから直接データをPandas DataFrameに取り込むことができます,

このデータセットには23カラムがあります。 以下はその様子です。

Some transformation and clean-up
ある列には少しスペースがあることに気がつきました。 他のいくつかは、いくつかの抽出とデータ型の変換が必要かもしれません。



この抽出を適用した後です。 新しいDataFrameには列が追加され、フィルタリングや統計モデリングに適したものになりました。

Examining and quantizing the “538 Grade” column
The columns “538 Grades” contains the crux of the dataset – the letter grade for the pollster. 通常の試験と同じように、A+はAより良く、AはB+より良い。 文字グレードのカウントをプロットすると、A+からFまで、合計15の階調が観察されます。

非常に多くのカテゴリ的等級を扱う代わりに、少数の数値グレードにまとめることもできます – A+/A/A- は 4、Bは 3 などです。

Boxplots
ビジュアル分析に入ると、まず boxplots から始めます。
どのポーリング手法が予測誤差の点でより良いパフォーマンスをするかチェックしたいと仮定してみましょう。 データセットには「単純平均誤差」という列があり、これは「レースで上位2位を分ける差について、世論調査の結果と実際の結果の差として計算された、会社の平均誤差」と定義されます。”

では、ある党派的バイアスを持ったポールスターが他よりも正しく選挙を当てることに成功しているかどうかを確認することに興味があるかもしれない。

上記で何か面白いことに気がつきましたか? もしあなたが進歩的でリベラルな考えの持ち主なら、どう考えても、民主党に党派的かもしれません。 しかし、平均して、共和党寄りの世論調査会社は、より正確に、より少ない変動で選挙を呼び出します。 9582>
データセットのもう一つの興味深いカラムは、「NCPP/AAPOR/Roper」と呼ばれるものです。 これは「世論調査会社がNational Council on Public Pollsのメンバーであるか、American Association for Public Opinion Researchの透明性イニシアティブに署名しているか、Roper Center for Public Opinion Researchのデータアーカイブに貢献しているかを示しています。 9582>
前述の主張の妥当性をどのように判断すればよいのだろうか。 このデータセットには「アドバンスド・プラス・マイナス」という列があり、これは「同じレースを調査した他の世論調査会社の結果と比較し、最近の結果をより重く評価したスコア」である。 負のスコアは有利であり、平均以上の品質を示す」(出典)。
ここに、この2つのパラメーターのボックスプロットがあります。 NCCP/AAPOR/Roperに関連する世論調査会社は、より低いエラースコアを示すだけでなく、かなり低い変動も示しています。

もしあなたが進歩的でリベラルな考えの人なら、どう考えても民主党の党員になる可能性はありますね。 しかし、平均すると、共和党寄りのバイアスを持つ世論調査会社は、より正確に、より少ない変動で選挙を呼び出します。
散布図と回帰プロット
パラメータ間の相関を理解するには、回帰フィットによる散布図を見ることができます。 私たちは Seaborn と Scipy Python ライブラリを使用し、これらのプロットを生成するためにカスタマイズした関数を使用します。
たとえば、「正しくコールされたレース」を「予測プラスマイナス」に関連付けることができます。 Five-Thirty-Eight によれば、「予測プラス・マイナス」は「世論調査会社が将来の選挙でどれだけ正確であるかを予測したもの」です。 これは、世論調査会社のAdvanced Plus-Minusスコアを、我々の方法論の質の指標に基づく平均値に戻すことで算出されます。” (出典)

また、我々が定義した「数値グレード」が、世論調査誤差平均とどのように相関しているかを確認することもできます。 また、「バイアス分析のための世論調査数」が、各世論調査員に割り当てられる「パーティザン・バイアス度」を下げるのに役立っているかどうかも確認することができます。 これは、世論調査の数が多いほど、党派的な偏りの程度を減らすのに役立つことを示しています。 しかし、この関係は非線形性が強く、対数スケーリングの方がよりよいフィッティングが得られるだろう。 世論調査の件数のヒストグラムをプロットしてみると、負のべき乗則に従っていることがわかります。 投票数が非常に少ない、または非常に多い投票者をフィルタリングし、独自の散布図を作成することができます。 しかし、世論調査の数と予測プラスマイナススコアの間にはほとんど相関がないことが観察されます。 したがって、非常に多くのポールが必ずしも高いポールの品質と予測力につながるわけではありません
。