




統計解析: 有意水準と信頼区間
どのような統計解析でも、母集団全体からのデータではなく、サンプルを使って行うことが多いはずです。
そのため、結果が正確で、単に偶然に発生したのではないことをどれだけ確信できるかを測定する方法が必要です。 統計学者はこのために信頼度と有意性という2つの関連した概念を使用します。
このページではこれらの概念について説明します。
統計的有意性
有意という用語は統計学において非常に特殊な意味を持っています。

図の中で、青い円は母集団全体を表しています。 サンプルを取るとき、サンプルは母集団全体から取られるかもしれません。 しかし、小さくなる可能性の方が高いです。 黄色い丸の範囲から全て採取すれば、かなり多くの母集団をカバーしたことになります。 しかし、運悪く(あるいはサンプリング手順の設計がまずかった)、小さな赤い円の中からしかサンプルが得られないかもしれません。
母集団の多くをカバーすることを確実にする最善の方法の1つは、より大きなサンプルを使用することです。 サンプルサイズは結果の精度に強く影響します(これについては「サンプリングとサンプルデザイン」のページで詳しく説明しています)。
しかし、別の要素も精度に影響します:集団自体での変動です。 データの広がりの指標を見ることで、これを評価することができます(これについては、「簡単な統計解析」のページを参照してください)。
有意性の概念は、単にサンプルサイズと母集団の変動を一緒に持ってきて、あなたがサンプリングエラーを行っている可能性の数値評価を行う:つまり、あなたのサンプルがあなたの人口を表していないことです。 通常、0.05 (5%) または 0.01 (1%) ですが、0.10 (10%) を示す結果もあります。
Null and Alternative Hypothesis
実験や市場調査を行うとき、一般に、行っていることが効果を持つかどうかを知りたいと思うでしょう。 したがって、それを仮説として表現することができます:
-x は y に影響を与えるだろう。
これは統計学では「対立仮説」として知られており、しばしば「H1」と呼ばれます。
「帰無仮説」、つまり H0 は、x は y に影響を与えないというものである。
統計的に言えば、有意性検定の目的は、結果が帰無仮説を棄却する必要があることを示唆しているかどうか、その場合、対立仮説はより真でありそうに見えるかを確認することである。
結果が有意でない場合、帰無仮説を棄却できず、効果がないと結論づけなければならない。
p値は、帰無仮説が真であれば、得られた結果を得たであろう確率である。 これはあるデータ点から平均までの距離を標準偏差の数で表したものです(平均と標準偏差については、「簡単な統計解析」のページを参照してください)。
単純に比較する場合、zスコアは次の式で計算します。
$$z=frac{x – \mu}{sigma}$
ここで、 \(x) はデータ点、 \(\mu) は集団または分布の平均、 \(\sigma) は標準偏差を示します。
例えば、あるゲームアプリが他のゲームよりも人気があるかどうかを検証したいとします。 平均的なゲームアプリのダウンロード回数は1000回、標準偏差は110とする。 我々のゲームは1200回ダウンロードされている。 その z スコアは次のとおりです。
$$z=comfrac{1200-1000}{110}=1.81$
高い z スコアは、結果が偶然に発生した可能性が低いことを示します。 p 値が希望の有意水準より低い場合、結果は有意である。
Z 表を使用すると、ゲーム アプリの Z スコア (1.81) は 0.9649 の p 値に変換される。 これは、5% (0.05) の望ましい水準よりも良いので (1-0.9649 = 0.0351, または 3.5% なので)、この結果は有意であると言えるでしょう。
なお、母集団からのサンプルの場合は少し違いがあり、zスコアは次の式で計算します。
$$z=frac{(x-mu)}{(\sigma/sqrt n)}$
ここでxはデータ点(通常はサンプル平均)、μは母集団または分布の平均、σは標準偏差、√nはサンプルサイズの平方根とします。
例えば、生物の学生が、他の科目を勉強している学生よりも良い点数を取る傾向があるかどうかを調べているとします。 40人の生物学者のサンプルの平均点数は80点で、標準偏差は5であり、その大学や学校の学生全体では78点であることがわかるかもしれません。
$$z=frac{(80-78)}{(5/sqrt 40)}=2.53$$
z表を用いて、2.53はp値0.9943に相当します。 これを1から引くと0.0054となります。 これは1%より低いので、この結果は1%水準で有意であり、生物学者はこの大学の平均的な学生よりもテストで良い結果を得ていると言うことができる。 実際、生物学のテストは他の科目のテストより簡単だということかもしれません。
サンプル平均の有意性の検定や、グループ間の差の検定については、仮説の展開と検定のページで詳しく説明しています。
信頼区間
信頼区間(または信頼水準)とは、真の値がその中にある確率を持つ値の範囲を指します。
事実上、サンプルの平均(サンプル平均)が、サンプルが採取された全母集団の平均(母集団平均)と同じであると、どれだけ自信があるかを測定します。
例えば、平均が 12.4 で、95% 信頼区間が 10.3-15.6 であれば、これは母集団平均の真の値が 10.3 から 15.6 までにあると 95%確実であることを意味します。 言い換えれば、12.4ではないかもしれないが、それほど違わないということは、それなりに確かだということです。
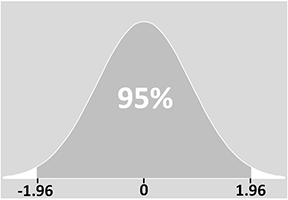
下の図は、正規分布(これについては、統計分布のページを参照してください)に従う変数についての実践を示しています。

信頼区間の正確な意味は、あなたが実験を何回も何回も行ったとして、これらの実験から構築した区間の95%は真の価値を含んでいるだろうというものです。 言い換えれば、あなたの実験の5%で、あなたの区間は真の値を含まないでしょう。
図から、信頼区間が母平均(左右の2.5%の「尾」)を含まない確率が5%であることがわかるでしょう。
信頼区間の計算
信頼区間の計算には、標本値、いくつかの標準指標(平均と標準偏差)を使います(これらの計算方法については、「簡単な統計解析」のページを参照してください)。
例で説明するとわかりやすいでしょう。
40人の身長をサンプリングして、平均が159.1cm、標準偏差が25.4だったとします。
信頼区間の標準偏差
理想的には母標準偏差を用いて、信頼区間を計算することになるでしょう。 しかし、これが何であるかを知っている可能性は極めて低いでしょう。
幸いなことに、十分大きなサンプルがあれば、標本標準偏差を使うことができます。
私たちは、平均値がすべての人の身長の妥当な推定値なのか、それとも特に高い(または低い)サンプルを選んだのか、調べる必要があります。
$$mean \pm z \frac{(SD)}{sqrt n}$
ここでSDは標準偏差、nは観察数またはサンプルサイズです。
z値は、選んだ基準分布の統計表から取得します。 これらの表は、特定の信頼区間(例えば、95%または99%)の z 値を提供します。
このケースでは、人々の身長を測定しており、人口の身長が(大まかに)正規分布に従うことを知っています(これについては、統計分布のページを参照してください)。
95%信頼区間のz値は、正規分布では1.96です(標準統計表より)。
上の式を用いると、95%信頼区間は次のようになります: $$159.1 \pm 1.96 \frac{(25.4)}{sqrt 40}$
これを計算すると、信頼区間が 151.23-166.97 cm となりました。 したがって、母平均がこの範囲に入ることは95%の確信があると言うのが妥当です。
zスコアまたはz値を理解する
zスコアは、平均からの標準偏差を表す尺度です。 したがって、私たちの例では、値の95%が平均の±1.96標準偏差内に収まることがわかります:
信頼区間の評価
経験則として、小さな信頼区間が優れています。 信頼区間はサンプルサイズが大きくなるにつれて狭くなっていきます。 サンプリングとサンプルデザインのページで説明しているように、理想的な実験は全人口を対象とすることですが、これは通常不可能です。
結論
信頼区間と有意性は統計結果の品質を示す標準的な方法です。 統計解析を行う際には、日常的にこれらを報告することが求められ、一般に正確な数値を報告すべきです。 これにより、あなたの研究が有効で信頼できるものであることが保証されます。