




Enterprise Data Warehouse: Concepts, Architecture, and Components
読了時間:12分
一日中、私たちは過去の経験に頼って多くの決断をしている。 私たちの脳は、過去の出来事に関する何兆ビットものデータを記憶し、意思決定の必要性に直面するたびにその記憶を活用するのです。 人と同じように、企業も過去に関する膨大なデータを生成し、収集している。
私たちの脳が処理と保存の両方に役立つ一方で、企業はデータを扱うために複数のツールを必要とします。
この記事では、エンタープライズ データウェアハウスとは何か、その種類と機能、およびデータ処理にどのように使用されるかについて説明します。 エンタープライズデータウェアハウスは通常のものとどう違うのか、どのような種類のデータウェアハウスが存在し、どのように機能するのかを定義します。 ウェアハウスを構築するための各アーキテクチャや概念的アプローチのビジネス価値に関する情報を提供することに重点を置いています。
エンタープライズ データ ウェアハウスとは
テラバイトがどれくらいかを知っている人は、Netflixが2016年に約44テラバイトのデータをウェアハウスに保有していたという事実に感銘を受けることでしょう。 このサイズだけで、なぜ単なるデータベースではなく、ウェアハウスと呼ぶのかがうかがえます。
エンタープライズ データウェアハウス (EDW) は、企業の過去のすべてのビジネス データを保存および管理する企業リポジトリの一形態です。 情報は通常、ERP、CRM、物理的な記録、およびその他のフラット ファイルなど、さまざまなシステムから取得されます。 データをさらに分析するために準備するためには、単一の保管施設に置かなければならない。 このように、異なるビジネス部門が問い合わせを行い、多角的に情報を分析することができます。
データウェアハウスを使用すると、企業は複数のデータベースを管理することなく、巨大なデータセットを管理することができます。 このような実践は、ビジネス インテリジェンス (BI) 用のデータを保存するための将来性のある方法であり、生データを実用的な洞察に変換する一連の方法/技術である。
Enterprise Data Warehouse vs. 通常のデータウェアハウス:その違いは?
どのデータウェアハウスも、一方はデータ統合ツール、他方は分析インターフェースを通じて生のデータソースと常に接続されているデータベースです。
どのようなウェアハウスも、データを変換し、移動し、エンド ユーザーに提示するメカニズムを持つストレージを提供します。 通常のデータウェアハウスとエンタープライズウェアの違いは、アーキテクチャの多様性と機能性がより広い範囲にあることです。 EDWは複雑な構造と規模を持つため、より小さなデータベースに分割されることが多く、エンドユーザーはこれらの小さなデータベースへの問い合わせをより快適に行うことができる。 これを考慮して、私たちは機能の全範囲をカバーするためにエンタープライズ ウェアハウスに焦点を当てています。
しかし、ウェアハウスのサイズは、その技術的複雑さ、分析およびレポート機能の要件、データモデルの数、およびデータそのものを定義するものではありません。 そこで、ウェアハウスをウェアハウスたらしめるものを理解するために、その中核となる概念と機能に飛び込んでみましょう。
Enterprise Data Warehouse concepts and functions
あらゆる装飾が施されたウェアハウスでも、その中心には基本概念と機能が横たわっています。 これらの柱は、技術的現象としてのウェアハウスを定義しています:
究極のストレージとして機能する。 エンタープライズデータウェアハウスは、組織内で発生するすべての企業ビジネスデータのための統一リポジトリです。 EDWは、Google Analytics、CRM、IoTデバイスなど、そのオリジナルのストレージ空間からデータをソースとする。 データが複数のシステムに散在していると、その管理は不可能です。 そこで、EDWの目的は、単一のリポジトリで元のソースデータと同様のものを提供することである。 社内外で常に新しい関連データが生成されるため、データの流れには、ウェアハウスに入る前にそれを管理する専用のインフラストラクチャが必要である。 EDWに格納されるデータは、常に標準化され、構造化されている。 このため、エンドユーザーはBIインタフェースやフォームレポートを通じて、データを照会することが可能である。 そして、これがデータウェアハウスとデータレイクが異なる点である。 データレイクは、分析目的のために非構造化データを保存するために使用されます。 しかし、ウェアハウスとは異なり、データレイクはデータエンジニア/サイエンティストが大量の生データを扱うために使用されます。 ウェアハウスの主な対象は、さまざまなドメインに関連する可能性のあるビジネスデータである。 データが何に関連しているかを理解するために、データは常にデータモデルと呼ばれる特定の主題を中心に構造化されている。 サブジェクトの例としては、販売地域やある品目の総売上高などがある。 さらに、すべての情報がどこから来たのかを詳細に説明するために、メタデータが追加される。 収集されるデータは、過去の出来事を記述しているため、通常は履歴データである。 ある傾向がいつ、どのくらいの期間行われたかを理解するために、ほとんどの保存データは通常、期間に分けられています。
Nonvolatile. 一度倉庫に入れたら、そこからデータが削除されることはない。 データは操作されたり、修正されたり、ソースの変更により更新されたりすることはあっても、少なくともエンドユーザーによって消去されることはない。 履歴データについて言えば、削除は分析目的には逆効果である。
基本原則を踏まえて、DWの実装タイプを見ていきましょう。
データウェアハウスのタイプ
EDWの機能を考えると、技術的にどう設計するかは常に議論の余地がある。 データの保存と処理の場合、それらはさまざまな種類のビジネスに固有であり、区別される。
クラシック・データウェアハウス
専用のハードウェアとソフトウェアを持つユニファイド・ストレージは、EDWのクラシックなバリエーションと考えられている。 物理ストレージでは、複数のデータベース間でデータ統合ツールをセットアップする必要がありません。 その代わり、EDWはAPIでデータソースと接続することで、常に情報を調達し、その過程で情報を変換することができます。 つまり、すべての作業はステージング領域(DWにロードする前にデータを変換する場所)か、ウェアハウス自体で行われます。
古典的なデータウェアハウスは、追加の抽象化レイヤーがないため、(以下で説明する)仮想ウェアハウスよりも上位にあると考えられています。 データ エンジニアの作業を単純化し、実際のレポート作成だけでなく、前処理側でのデータ フローの管理も容易になります。
- ハードウェアとソフトウェアの両方を含む高価な技術インフラストラクチャ、
- データプラットフォーム全体のセットアップと保守のためにデータエンジニアとDevOpsスペシャリストのチームを雇用すること、
使用時期:データを処理してそれを活用したいあらゆる規模の組織に適しています。 クラシックウェアハウスは、データプラットフォームの異なるアーキテクチャスタイルに変形することができ、また、目的に応じてスケールアップやスケールダウンが可能です。
バーチャルデータウェアハウス
バーチャルデータウェアハウスは、クラシックウェアハウスに代わるものとして使われるEDWの一種です。 基本的に、これらは仮想的に接続された複数のデータベースであり、単一のシステムとしてクエリできます。
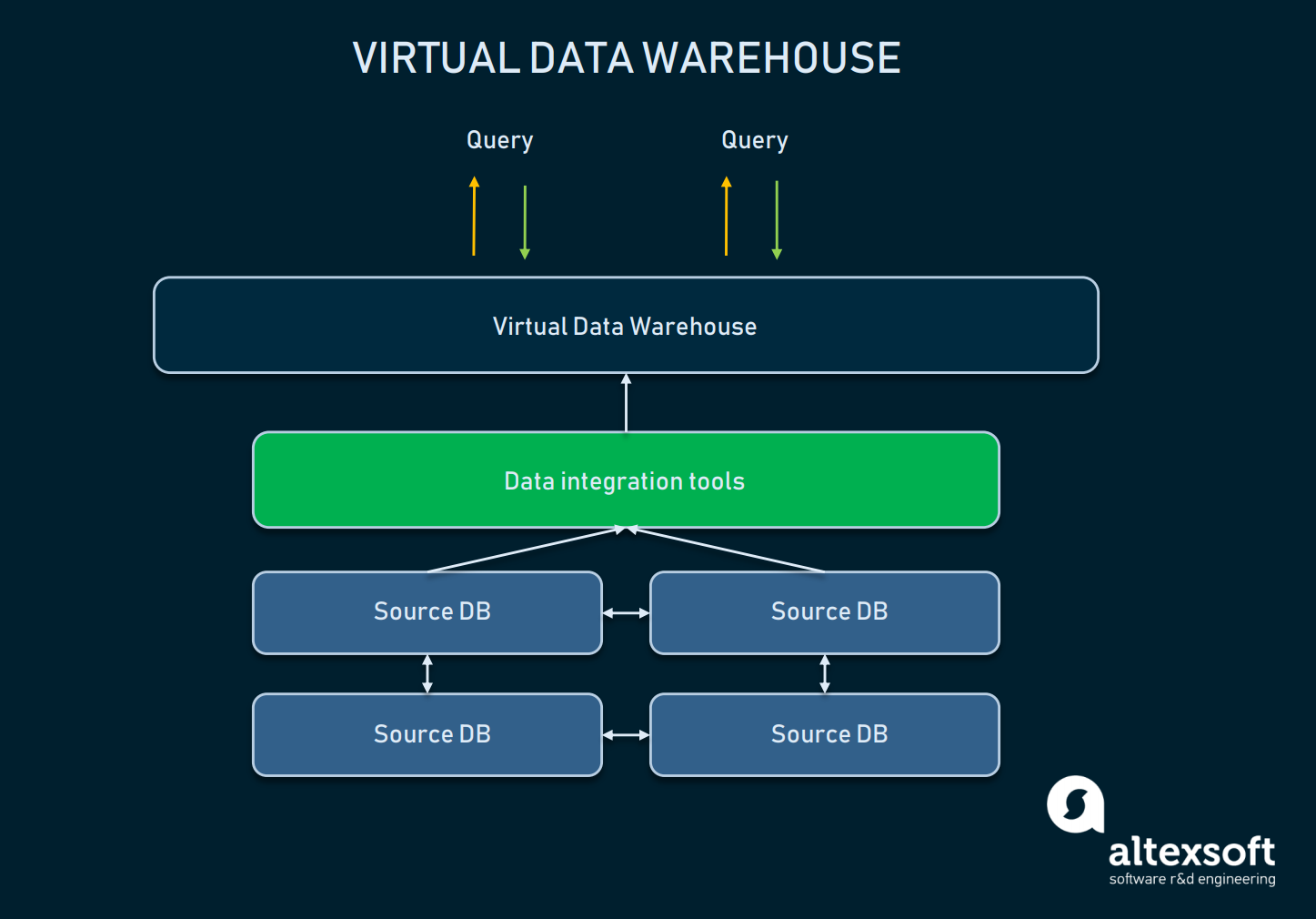
仮想 DW の抽象化とソース データベース間の関係のスキーム
このようなアプローチによって、組織はそれをシンプルに維持することができます。 データはそのソースにとどまることができますが、分析ツールの助けを借りて引き出すことができます。 仮想ウェアハウスは、基盤となるすべてのインフラストラクチャに干渉したくない場合、または、持っているデータがそのまま簡単に管理できる場合に使用することができます。 しかし、このようなアプローチには多くの欠点があります。
- 複数のデータベースを使用すると、常にソフトウェアとハードウェアのメンテナンスとコストがかかります。
- 仮想 DW に格納されたデータは、エンド ユーザーやレポート作成ツールが消化できるように変換ソフトウェアが必要なままです。
- 複雑なデータクエリは、必要なデータの断片が2つの別々のデータベースに配置される可能性があるため、時間がかかりすぎるかもしれません。
使用する場合:複雑な分析を必要としない標準的な形式の生データがあるビジネスに適しています。
Cloud Data Warehouse
この10年間、クラウド/クラウドレス技術は、組織レベルの技術を設定するための標準となってきました。 ウェアハウス アズ ア サービスを提供するプロバイダーは、市場に数え切れないほど存在します。 そのいくつかを挙げると
- Amazon Redshift/ 価格ページ
- IBM Db2/ 価格ページ
- Google BigQuery/ 価格ページ
- Snowflake/ 価格ページ
- Microsoft SQL Data Warehouse/ 価格ページ
上記すべての提供者は完全管理型サービスを提供しています。 BIツールの一部としてスケーラブルなウェアハウスを提供したり、SnowflakeのようにスタンドアローンサービスとしてEDWにフォーカスしています。 この場合、クラウド・ウェアハウス・アーキテクチャには、他のクラウドサービスと同様の利点があります。 つまり、自社でサーバーやデータベース、ツールを用意しなくても、インフラを管理できるのだ。 このようなサービスの価格は、必要なメモリの量と、クエリのための計算能力の量に依存します。
クラウド ウェアハウス プラットフォームの面で唯一懸念されるのは、データのセキュリティです。 ビジネス データは機密性の高いものです。 そのため、選択したベンダーが侵害を回避するために信頼できるかどうかを確認したいものです。 必ずしもオンプレミスの倉庫の方が安全というわけではありませんが、この場合、データの安全性はあなたの手に委ねられています。
いつ使うか。 クラウド プラットフォームは、どのような規模の組織にも最適な選択肢です。 マネージド データ統合、DW のメンテナンス、BI サポートなど、すべてをセットアップする必要がある場合です。
Enterprise Data Warehouse Architecture
ウェアハウス機能を何らかの方法で拡張するアーキテクチャーのアプローチは数多くありますが、ここでは最も本質的なものに焦点を当てます。 あまり技術的な詳細には触れませんが、データ パイプライン全体は 3 つの層に分けることができます。
- ロー データ層 (データ ソース)
- ウェアハウスとそのエコシステム
- ユーザー インターフェイス (分析ツール)
ウェアハウスへのデータ抽出、変換、ロードに関するツールは、ETL という別のカテゴリーのツールとして知られています。 また、ETL の傘下にあるデータ統合ツールは、ウェアハウスに配置される前にデータの操作を実行します。 これらのツールは、生データ層と倉庫の間で動作します。
データが倉庫にロードされるとき、それはまた変換されることがあります。 そのため、ウェアハウスでは、クリーニング/標準化/次元化のための一定の機能が必要になります。 これらと他の要因によって、アーキテクチャの複雑さが決まります。 ここでは、組織のニーズの高まりという観点からEDWのアーキテクチャを見ていきます。
One-tier architecture
データ統合がうまく構成されていれば、データウェアハウスを選択することができます。 ほとんどの場合、データウェアハウスは、多次元データを可能にするモジュールを備えたリレーショナル データベースであり、または、より簡単にアクセスできるようにいくつかのドメイン固有の情報を分離することができるものです。 最も原始的な形では、ウェアハウスは単なる1層アーキテクチャを持つことができます。
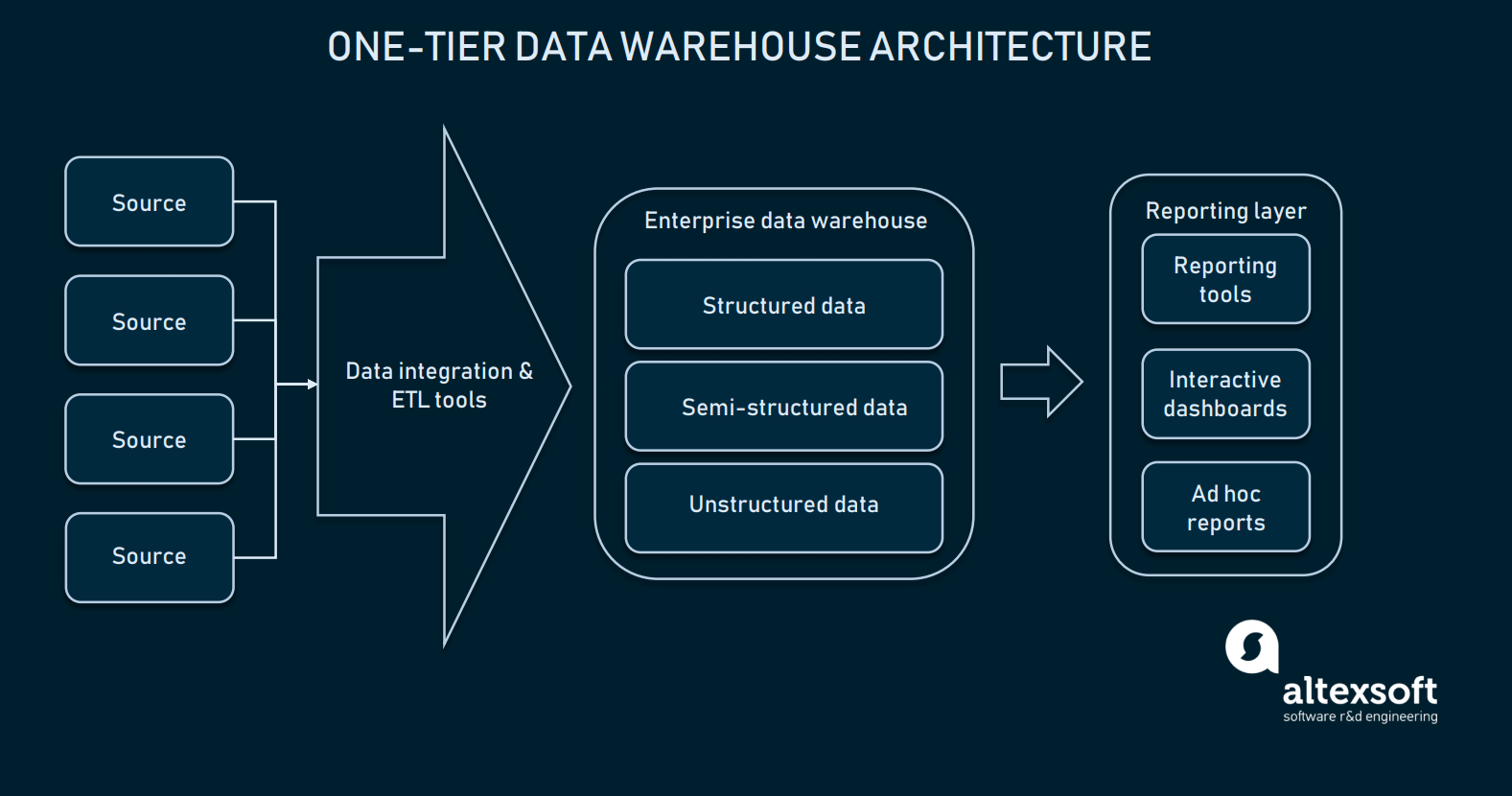
レポート層はEDWのデータベース全体と直接接続されている
EDWの1層アーキテクチャとは、エンドユーザーがクエリーを作成できる分析インターフェイスと直接接続したデータベースを持っていることを指します。 EDWと分析ツールを直接接続することは、いくつかの課題をもたらします。
- 従来は、100GBのデータからストレージをウェアハウスと考えることができました。 DW から直接データを照会する場合、システムが必要でないデータを除外できるように、正確な入力が必要になることがあります。
- 限られた柔軟性/分析機能が存在する。
さらに、1 層のアーキテクチャは、レポートの複雑さにいくつかの制限を設定します。 このようなアプローチは、速度の遅さと予測不可能性から、大規模なデータ プラットフォームにはほとんど使用されません。
2層アーキテクチャ(データマート層)
2層アーキテクチャでは、ユーザーインターフェイスとEDWの間にデータマートレベルが追加される。 データマートは、ドメイン固有の情報を格納する低レベルのリポジトリです。 簡単に言えば、販売/運用部門、マーケティングなどの専用情報で EDW を拡張する、もう 1 つの小さいサイズのデータベースです。
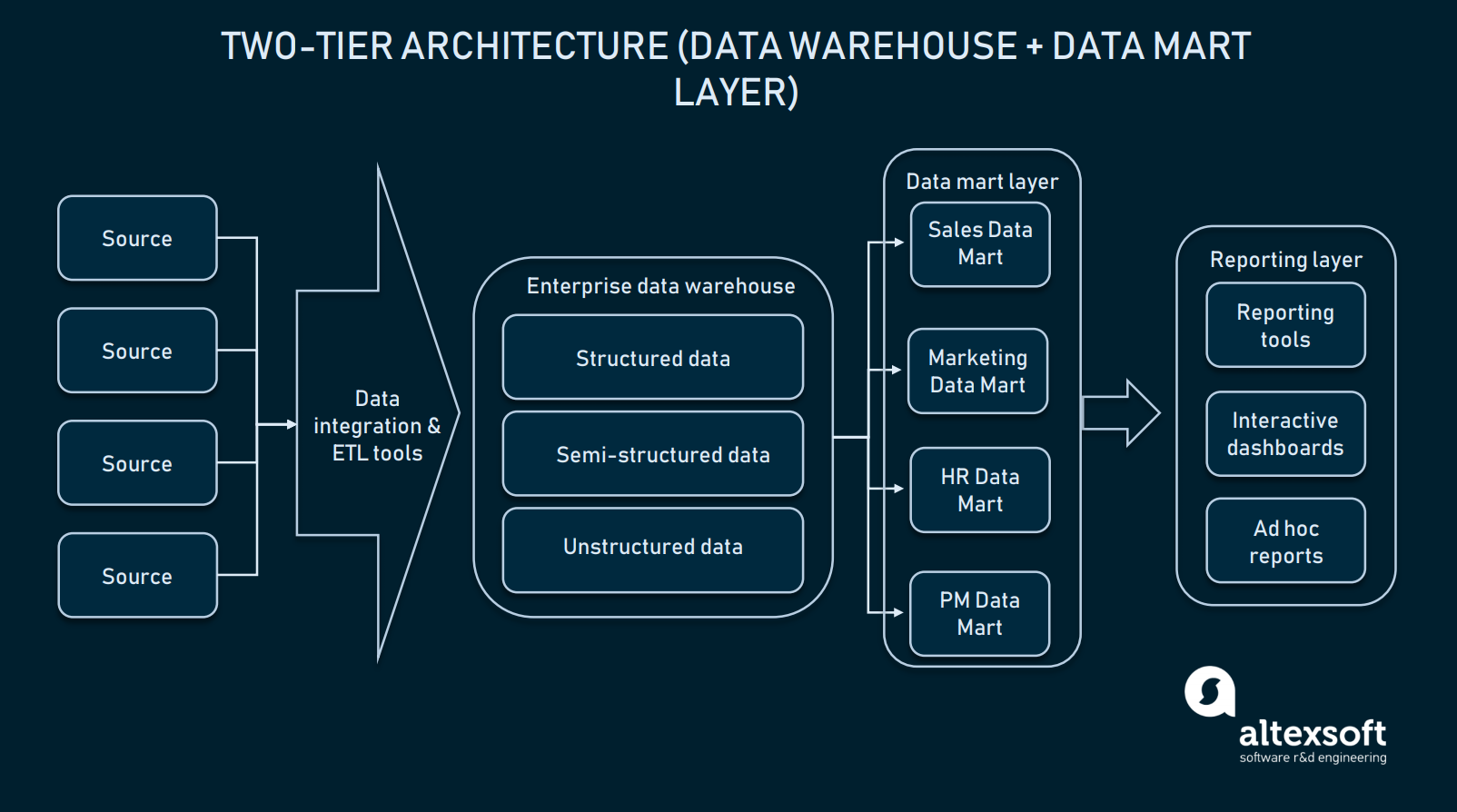
2層アーキテクチャでは、ドメイン固有のデータを提供するデータマートによって EDW が拡張されます
データマート層を作成するには、ハードウェアを確立してこれらのデータベースとデータプラットフォームの残りの部分を統合するための追加リソースが必要とされます。 しかし、このようなアプローチは、クエリに関する問題を解決する。 特定のマートにはドメイン固有の情報しか含まれないため、各部門が必要なデータに簡単にアクセスできるようになります。 さらに、データマートはエンドユーザーのデータへのアクセスを制限し、EDWをより安全にします。
3層アーキテクチャ(オンライン分析処理)
データマート層の上に、企業はオンライン分析処理(OLAP)キューブを使用することもあります。 OLAP キューブは、複数の次元からデータを表現する特定のタイプのデータベースです。 リレーショナル データベースがデータを 2 次元で表すのに対し (Excel や Google シートを思い浮かべてください)、OLAP では、複数の次元でデータをまとめ、次元間を移動できます。
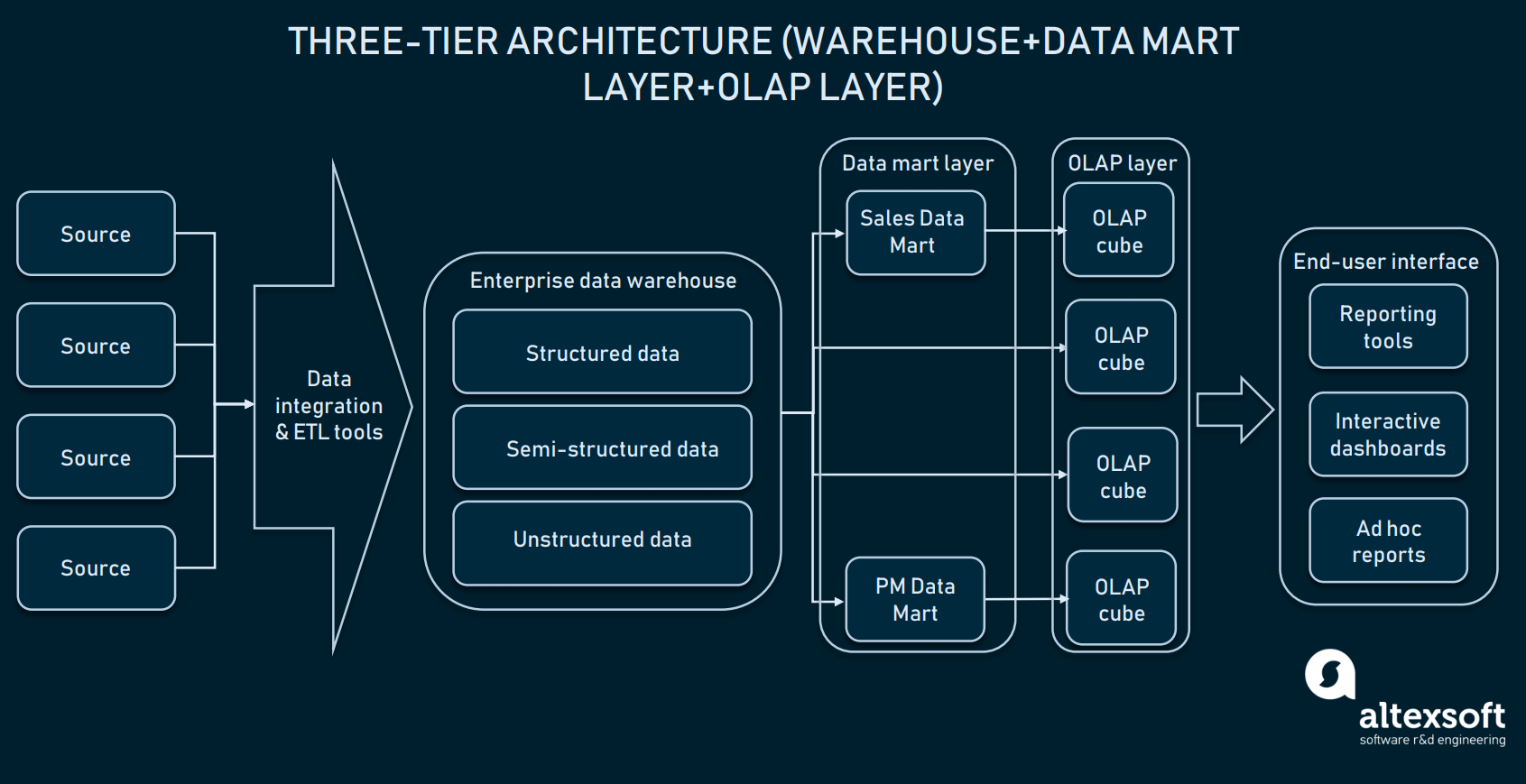
OLAP キューブの層では分散マートから情報を取得することも、EDW
言葉ではかなり難しいので、キューブがどのように見えるかのこの便利な例を見てみましょう。
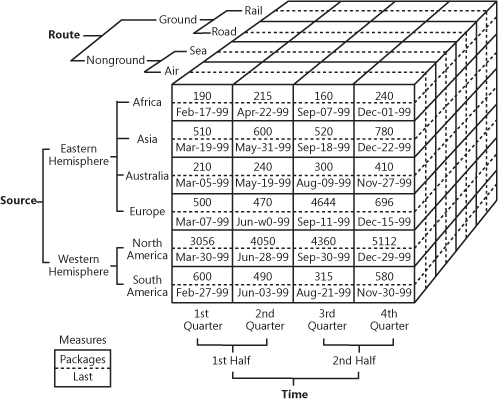
OLAP キューブによる多次元販売データのデモ
Source: oreilly.com
このように、キューブはデータに次元を追加するものです。 これは、複数の Excel テーブルを組み合わせたものと考えてもよいでしょう。 キューブの前面は通常の 2 次元テーブルで、地域 (アフリカ、アジアなど) が縦に指定され、売上番号と日付が横に記述されています。 しかし、キューブの上部にあるルート別の売上高と、下部にある期間別の売上高を見るとき、マジックが始まる。 これは多次元データとして知られています。
OLAPのビジネス価値は、ユーザーがデータを切り刻んで詳細なレポートを作成できるようにすることです。 キューブがウェアハウスで動作するように最適化されている限り、企業の全データにアクセスするためのEDWと直接併用することも、各データマートに特化して使用することも可能です。 実装に関しては、ほぼすべてのウェアハウスプロバイダーがOLAPをサービスとして提供しています。 例として、マイクロソフトのOLAP提供に関するドキュメントを確認してください。
以上、組織のニーズに適用するEDWのハイレベルな設計について述べてきました。
Data Warehouse vs Data Lake vs Data Mart
データ格納アーキテクチャについて言えば、ウェアハウスの代わりにデータマートやデータレイクを使用するというオプションについて言及しなければなりません。 5737>
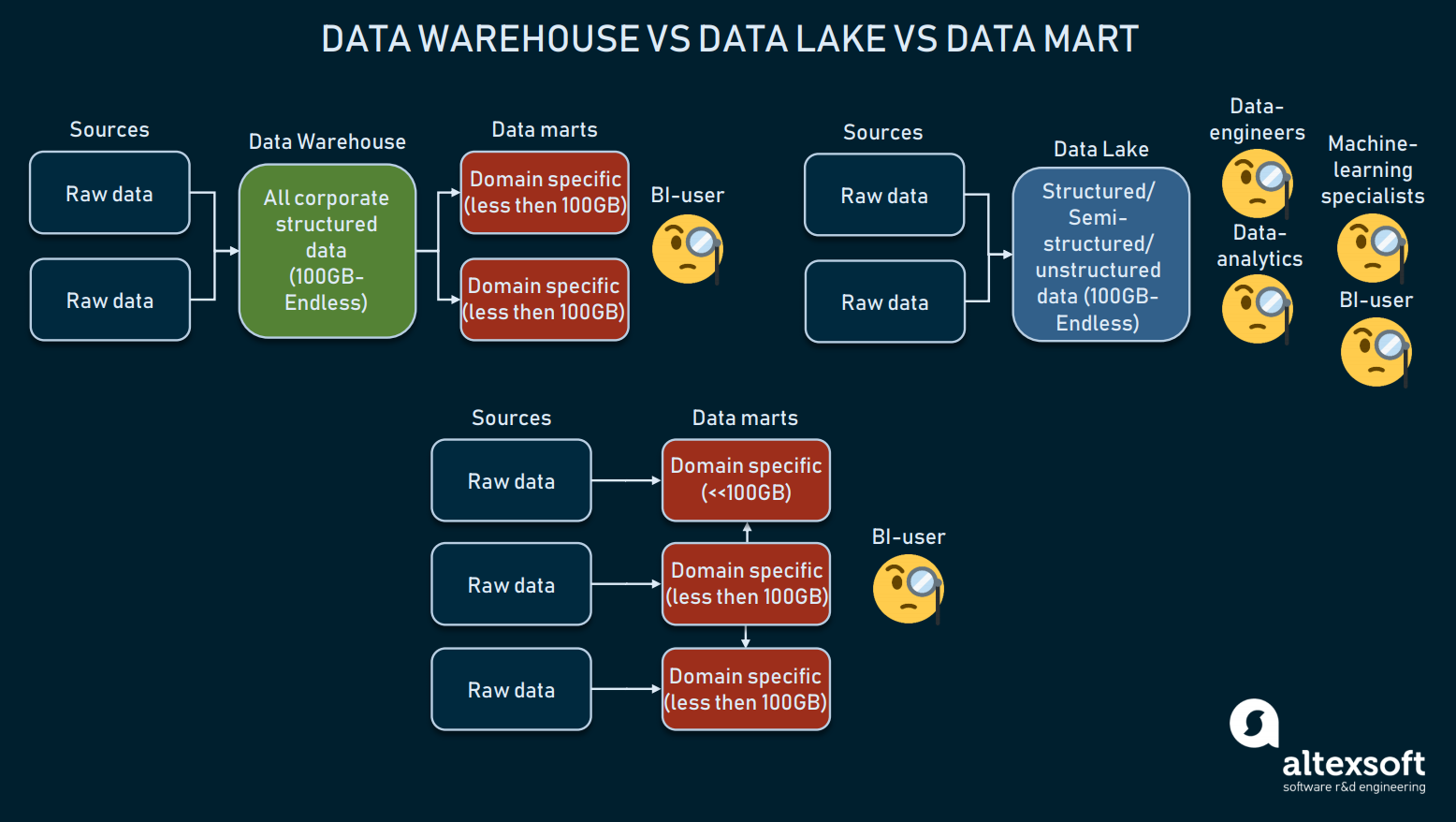
3つのデータ ストレージ形式の比較
データウェアハウスは、クエリー ツールやエンド ユーザーが包括的に結果を得られるように、構造化データを格納することを目的としています。 ウェアハウスは、主にBIに使用され、通常、100GBから無限大の間でサイズが異なります。
一方、データレイクは、主に生データまたは混合データを保存するために使用されます。 これらは、機械学習、ビッグデータ、またはデータマイニングの目的で利用されることが多い。 ここ数年、データレイクは BI に使用されています。生データをレイクにロードして変換することで、ETL プロセスの代わりとなります。 このアプローチには長所と短所がありますが、データレイクは構造化されたデータに到達するには厄介すぎる場合があります。 このようなモデル(Kimballのモデルのような)は、複数のデータマートを使用してドメインごとに情報を分散させ、互いに接続することを想定しています。 しかし、データマートはサイズが小さいため(通常100GB以下)、企業ではほとんど使用できない。 多くの場合、データマートは大規模な DW をより運用しやすいものに分割するために使用されます。
Enterprise Data Warehouse Components
ウェアハウス プラットフォームをセットアップするために使用する機器はたくさんあります。 ウェアハウスそのものを含め、そのほとんどについてはすでに述べたとおりです。 そこで、各コンポーネントの目的とその機能を俯瞰してみましょう。 つまり、生のデータが保存されているデータベースです。
ETL (Extract, Transform, Load) または ELT (Extract, Load, Transform) 層。 これらは、ソースデータとの実際の接続、その抽出、および変換される場所へのロードを実行するツールです。 変換はデータ形式を統一する。 ETLとELTのアプローチは、ETLでは変換がEDWの前にステージング・エリアで行われる点で異なる。 ELTは、より現代的なアプローチで、すべての変換を倉庫で処理します。 ETLの場合、ステージング・エリアはEDWの前にデータがロードされる場所である。 ここで、クリーニングされ、所定のデータモデルに変換される。 ステージング・エリアには、データ品質管理のためのツールも含まれることがあります。
DW データベース。 データは最終的にストレージスペースにロードされる。 ELTでは、まだここで何らかの変換が必要かもしれない。 しかし、その段階で、すべての一般的な変更が適用されますので、データは、その最終的なモデル(複数可)にロードされます。 前述したように、データウェアハウスはリレーショナルデータベースであることがほとんどです。 DW には、データベース管理システムとメタデータ用の追加ストレージも含まれます。
Meta-data module. 簡単に言えば、メタデータはデータに関するデータである。 この情報はどのような主題/領域に関係するのか、ユーザー/管理者にヒントを与える説明のことである。 このデータは、技術的なメタ(例:最初の出所)であったり、ビジネス的なメタ(例:販売地域)であったりする。 すべてのメタはEDWの別のモジュールに格納され、メタデータ・マネージャによって管理される。 これらは、エンドユーザーがデータにアクセスするためのツールである。 BI インターフェースとも呼ばれ、この層はデータを視覚化し、レポートを形成し、個別の情報を引き出すためのダッシュボードとして機能する。
最後に思うこと
データを渡すツールのチェーンを理解することは、何が実際にあなたのデータプラットフォーム要件に合うかを把握するのに役立つ。 ウェアハウスをセットアップする計画は、最も基本的な形でその規模が大きいため、計画とテストに何年もかかるかもしれません。
ビジネス所有者として、使用するオプションや技術の数に混乱するかもしれないので、ウェアハウス、ETL、および BI の分野の専門家に相談することが肝心です。 専門家は技術的な側面であなたを助けることができますが、ビジネス目的を定義するためには、実際のデータを業務で使用する人と話すことです。