




SQL Magazine 7 article – SQL Server: Turbine your queries with indexed views
Take your question Mark as completed Annotate
この記事の目的は、SQL Serverインデックス付きビューの概念を紹介し、このタイプのビューを実装して使用してクエリを最適化する方法を紹介することです。 ビューは、オブジェクトに格納されたSELECT文に他なりません。 ビューを作成するための構文は、リスト1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;リスト1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66ビューを使用する利点の中で、次のことを挙げることができます。
- コードの簡素化: 一度だけ複雑な SELECT を書き、それらをビューでカプセル化して、任意のテーブルであるかのようにビューからそれらをトリガーできます。 しかし、これらのテーブルのいくつかのカラムは、すべてのユーザーがアクセスする必要があります。 この問題を解決する効果的な方法は、ビューを作成し、機密性の高い列を非表示にすることです。 この方法で、元のテーブルへのアクセス権を抑制し、ビューへのアクセスを解放することができます。
Indexed views in practice
Views encapsulate SELECT statements, which means when they are triggered, the SELECT statements associated with them are performed. ビューは、(テーブルがそうであるように)返すデータのリポジトリを作成しません。 さて、ビューで見つけたSELECTコマンドの結果をテーブルに “実体化 “して、インデックスを作成してアクセスしやすくできればいいのですが。 インデックス付きビューは、まさにそれを実現するものです。 インデックス付きビューで SELECT を実行すると、従来のテーブルで SELECT を実行したのと同じ効果があります。
インデックス付きビューの主な目的はパフォーマンスの向上で、SQL Server の利点は、ビュー名がクエリーで明示されていなくても、インデックス付きビューをデータ アクセスの手段として実行プランで考慮できるようにしたことです。 これは、SQL Server 2000のEnterprise Editionでは、次に見るように、コマンドオプティマイザが(テーブルに存在する生データを選択するのではなく)インデックス付きビューのデータを直接選択することができるためです。
Creating an indexed view step-by-step
- 環境を設定する、最初のステップは、ビューを作成し使用したいセッションでいくつかのパラメーターの状態を設定する、なぜならインデックス付きビューがテーブルで「実体化」されるので、何もその結果に干渉できないからです。 インデックス付きビューが作成される前に、SELECT の結果に影響する特定の設定 (concat_null_yelds_null など) が設定されます。
- インデックス付きビューが作成されます。 ビューが実体化されているため、現在の構成と矛盾する結果が得られます。
例えば、リスト 2 では、concat_null_yields_null プロパティが変更されたときのコマンドの結果の違いを示します。
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcインデックス付きビューが concat_null_yields_null プロパティを有効にして作成され、現在のセッションがそのプロパティを無効にしていたらどうなるか想像してみてください – 同じ SELECT で異なる結果になるはずです。
この問題は簡単な方法で解決されました。インデックス付きビューを作成および使用するには、デフォルト値のリストに従って環境を構成することが必須です。 この方法では、いずれかの設定が標準外の値に設定されている場合、ビューは単に動作しないため、異なる結果を得ることは不可能です。
表 1 に、これらの設定とそれぞれのデフォルト値を示します。
| 設定 | Id (*) | インデックス付きビューに必要な状態 | SQL Server 2000 デフォルト | DB Library 使用接続でのデフォルト | ||
|---|---|---|---|---|---|---|
| ansi_nulls | 32 | on | off | on | off | |
| ansi_padding16 | on | off | ||||
| ansi_warning | 8 | on | new! | off | on | off |
| arithabort | 64 | on | off | offoff | ||
| concat_null_yields_null | 4096 | on | off | on | off | off |
| quoted_identifier | 256 | on | off | on | off | 8192 | OFF | OFF |
(*) id は sp_configure コマンドで使用されます。 各設定が何をするのか確認するには、「インデックス付きビューに必要な設定」をお読みください。 設定の値を変更する方法は2つあります:
- セッションで直接:set ON | OFFコマンドを実行
- 既存のサーバーデフォルトを変更:sp_Configure ‘user options’, .を実行します。 各コンフィギュレーションのID番号は表1の通りです。
注:AritHabortのIDは64、Quoted_IdentifierのIDは256です。 例えばQuoted_IdentifierとAritHabortをリンクさせるには、64+256(=320)の結果をパラメータとしてsp_cofigureを実行します: sp_configure ‘user options’, 320. 各構成に割り当てられたidの完全なリストは、http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
表1の各パラメータの状態を確認するには、SessionProperty(‘パラメータ名’)関数またはDBCC UserOptionsコマンドを使用することである。
そのように、表1の「インデックス付きビューに必要な状態」列に従ってすべてのパラメータを設定します。このようにしないと、SQL Serverはインデックス付きビューの作成/実行を許可しません。
インデックス付きビューの作成
NorthWindデータベース内にある「注文詳細テーブル」で、日々の販売額を集計するビューを作成します。
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goインデックス付きビューを作成する際に、いくつかの特殊性を観察する必要があります:
- ビューは決定性でなければならない。 ビューのコードに決定論的な関数だけを使用すれば、ビューは決定論的となります。 インデックス付きビューで同じSELECTコマンドを繰り返し実行しても、(静的なベースを考慮すると)異なる結果を得ることはできません。 決定論的関数は、ある関数が何度実行されてもその結果が変わらないことを保証する。 例えば、DatePartという関数は、特定の日付に対して常に同じ結果を返すので、決定論的である。 getdate()関数は、実行するたびに異なる値を返します。 SQL Server 2000 の決定論的関数の完全なリストについては、http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- 構文の制限がないことを確認してください。 以下に挙げる節、関数、クエリタイプは、インデックス付きビューのスキーマを統合することはできません。
- MIN,MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUM on column that allow null values
- DISTINCT
- ROWSET関数
- 派生テーブル、自己結合、サブクエリ。 外部結合
- DISTINCT
- UNION
- Float, text, ntext and image
- COMPUTE and COMPUTE BY
- HAVING, CUBE and ROLLUP
SchemaBindingでインデックス付きビューを作る必要がある。 ビューの内容の一貫性を保つために、ビューの元となるテーブルの構造を変更することはできません。 この種の問題を回避するには、インデックス付きビューを作成するときに SchemaBinding を使用することが必須です。このオプションでは、最初にビューを削除しないとテーブル構造を変更できないからです。
GROUP BY 節を使用するには、COUNT_BIG(*) 関数を含めることが必須です。 count_big(*) 関数は count(*) と同じですが、bigint 型 (8 バイト) の値を返します。
常にインデックス付きビューで参照されているオブジェクトのオーナーに通知します。 同じ名前で異なる所有者のテーブルを持つことができるため、select * from Orders の代わりに select * from dbo.Orders を使用してください。 スキーマバインドオプションは必須であるため、SQL Server はスキーマの変更を抑制するために正確なオブジェクト仕様を必要とします。
Creating cluster index in view (materialization)
項目 2 で作成したビューは select コマンドの結果がテーブルに具体化されていないため、インデックス付きのビューとしてまだ動作していない。 Query Analyzer で sp_spaceused コマンドを実行すると、テーブルの行数と使用領域が返されます (リスト 4)。
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.リスト 4. ビューに対する sp_spaceused コマンドの使用リスト 5 では、物理読み込みの値がゼロになるほどにビューの処理が完全に論理であることが確認できました。 Logical Reads と Physical Reads に記録された値 (1672+0+4+0=1676) に注意してください。今後の比較でこれらの値を使用します。
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.Listing 5. クラスタ インデックスを作成する前のビューに関連する合計 I/Oビューがインデックス化(実体化)できるかどうか、つまり、インデックス化ビューに必要な基準や設定内で作成されているかどうかを確認するには、次の SELECT の結果が 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')前提条件を確認して、次にインデックスを作成することができるようにしました。 構文は、従来のテーブルにインデックスを作成するときに使用されるのと同じ形式です:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)データのページを生成するので、クラスタインデックスが必要なことに留意してください。 インデックス付きビューに非クラスター インデックスを作成できるのは、クラスター インデックスを作成した後です。
これで、ビューで見つかった SELECT は実体化されました。これは Query Analyzer の sp_spaceused コマンドで証明できます(リスト 6.)
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBリスト 6 . インデックス付きビューでの sp_spaceused コマンドの使用Using indexed views
インデックス付きビュー(従来のビューと同様)にアクセスする方法の1つは、SELECT コマンドでその名前を参照することです。
select * from vi_vendas_mesリスト5(1672+4=1676)とリスト7(2+0=2)の移動ページ量を比較する。 この違いは非常に重要で、インデックス付きビューを作成すると、必要な総 I/O が 1674 ページ減少します。
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Listing 7.Total I/O associated with view after creating index cluster別の例を見てみましょう。 図1は、クエリの実行計画である。 SELECT行に存在しないにもかかわらず、ビューが選択されたことを確認します。
クエリ実行プランの構築中に、オプティマイザは vi_sales_mes にクエリの要約済みデータが既にあることを発見し、インデックス付きビューで直接データを選択することを選択しました。 作成されたインデックス付きビューにアクセスするクエリ実行計画
図1で実行されたクエリは、ビューvi_sales_mesで見つかったものと同一であることに注意してください。 しかし、オプティマイザによるビューへのアクセスは、実行されたクエリとビュークエリの類似性とは無関係である。 クエリプロセッサーによるインデックス付きビューの選択は、コスト・ベネフィットのみを考慮したものである。
しかしながら、クエリオプティマイザがインデックス付きビューを考慮するためには、いくつかの規則に従うことが必要です:
- ビューに存在する結合は、クエリに「含まれる」必要があります。
- クエリで設定された条件は、ビューの条件と一致する必要があります。図2のSELECTでは、ビューコードにwhere句が存在しなかったため、インデックス付きビューvi_sales_mesは考慮されず、結合で数量<= 5の行が計算される原因となりました。
一方、クエリがwhere条件を持つ場合、where sum(Quantity) > 5、クエリ条件はビューに存在するSELECTのサブセットなので、ビュー vi_sales_mesが実行計画で考慮されることになります。
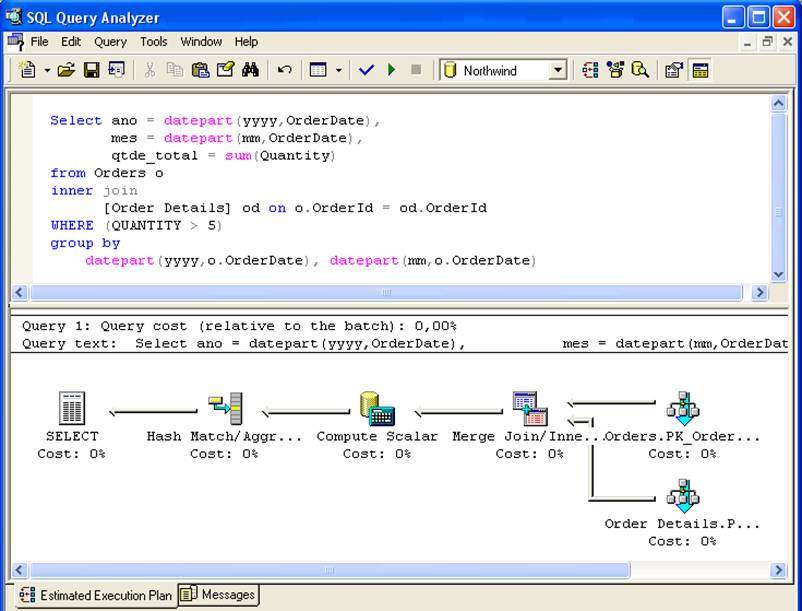
図2.作成されたインデックス付きビューにアクセスしないクエリの実行計画 クエリの集約関数の列は、ビュー定義に「含まれる」必要があります:ビューが列qtde=sum(数量)を返し、クエリが列vlr_unit=sum(単価)があれば、ビューは検討対象にならないことになります。
図 3 は、コマンド オプティマイザのインテリジェンスを証明できる SELECT コマンドです。AVG (Quantity) の計算が、SUM (Quantity) / Count_Big (*) の分割に置き換えられ、Compute Scalar のアイコンで表現されています。
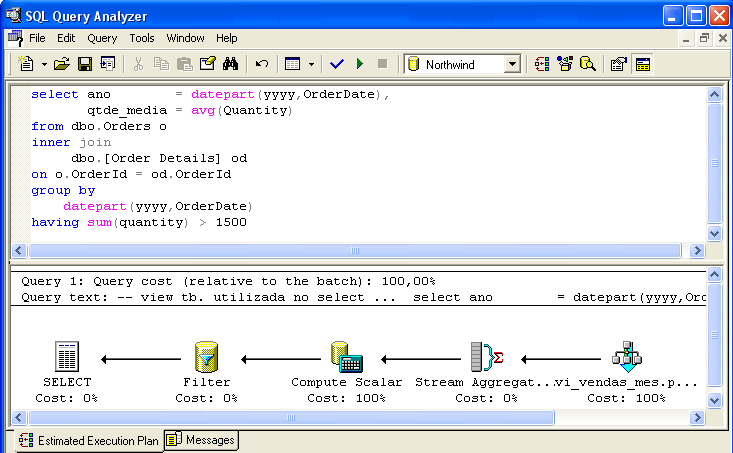
図3.インデックス付きビューを使用した「一般的な」選択 インデックス付きビューの使用に関する一般的な考慮事項:
- インデックス付きビューはSQL Server 2000の任意のバージョンで作成することができます。 しかし、Enterprise Edition バージョンでのみ、これらはクエリオプティマイザーによって自動的に選択されます。
- Enterprise 以外のバージョンでは、従来のテーブルとしてインデックス付きビューにアクセスするには、NoExpand ヒントを使用する必要があります。 NoExpandが採用されない場合、インデックス付きビューは「通常の」ビューとみなされます。
注意:Expand ヒントは NoExpand の逆を行います:インデックス付きビューを “通常の” ビューとして扱い、実行時フェーズで SQL Server に SELECT ステートメントを実行させます。
- OLTPベースにおけるインデックス付きビューの使用には注意が必要で、クエリでは優れた性能を発揮しますが、ビューに関連するテーブルを修正する処理でオーバーヘッドが発生します。 インデックスを使用する場合と同様に、オプティマイザは、クエリの最適な実行プランを選択するプロセスの一部として Enterprise バージョンのビューコードを分析します。 しかし、同じクエリに対して実行可能なインデックス付きビューが多数ある場合、すべてのビューを分析することになるため、この選択時間が大幅に増加する可能性があります。 したがって、ビューを実装する際には常識を働かせてください。
Required Settings for Indexed Views
ANSI_NULLS
NULL 値との比較がどのように行われるかを定義します (リスト 8)。
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROリスト 8。 ansi_nullANSI_PADDING
char, varchar, binary, varbinary columns の内容がテーブル構造で定義されたサイズより小さいとき、どのように格納されるべきか決定する。 SQL Server 2000 のデフォルトでは、ansi_padding をオン (=ON) にします。この条件では、次のルールが適用されます。
- char カラムを更新するとき、カラム構造で定義されたサイズより小さいと、ホワイトスペースがストリングの終わりに追加されます。 同じルールがバイナリ列にも適用される(その場合、スペースは一連のゼロで埋められる)
- Varchar または varbinary 列は上記のルールに従わない:彼らは常に元のサイズを維持する。
ARITHABORT
有効にすると、ゼロによる除算または何らかのオーバーフローが発生したときにクエリの実行を終了します。
QUOTED_IDENTIFIER
有効にすると、テーブル、列などの名前を指定するのにダブルクォートを使用することができます。 –
CONCAT_NULL_YELDS_NULL
ヌル値を持つ文字列を連結する結果を制御します。
ANSI_WARNINGS
有効にすると、次の場合にエラー メッセージを生成するように設定します:
- 要約機能を使用し、クエリー範囲にヌル値が見つかった場合、
- ゼロによる分割または算術オーバーフローが見つかった場合。
NUMERIC_ROUNDABORT
算術演算で数値精度の損失が発生した場合に SQL Server がどのように処理を行うかを制御します。 このパラメータが有効で、小数点以下2桁の精度の変数が小数点以下3桁の値を受け取った場合、操作は中断されます。 パラメータを無効にすると、値は小数点以下 2 桁に切り捨てられます。
Conclusion
クエリ最適化に関しては、インデックス付きビューはパフォーマンスを活用するための良い選択です。 そのため、要約を扱い、一定の頻度で実行されるクエリを十分に評価し、インデックス付きのビューを作成するようにします。 それだけの価値がある仕上がりです!
。