




SQL Magazine 7 article – SQL Server: Turbinera dina frågor med indexerade vyer
Ta din fråga Markera som avslutad Kommentera
Syftet med den här artikeln är att introducera konceptet med indexerade vyer i SQL Server och visa hur man implementerar och använder den här typen av vyer för att optimera frågor.
Konceptet med vyer
Vyer kallas också ”virtuella tabeller”, eftersom de är ett alternativ till att använda tabeller för att komma åt data. En vy är inget annat än ett SELECT-meddelande inkapslat i ett objekt. Syntaxen för att skapa en vy visas i listning 1.
CREATE VIEW nome_da_visão ...) ] AS subconsulta;Se ett exempel på skapande och användning av vyer i listning 1.
Use NorthWind go create view vi_vendas_mes As Select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity) from Orders o inner join od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate), datepart(mm,o.OrderDate) go select * from vi_vendas_mês go ano mes qtde_total contador ----------- ----------- ----------- -------------------- 1996 7 1462 59 1996 8 1322 69 1996 9 1124 57 1996 10 1738 73 1996 11 1735 66En av fördelarna med att använda vyer är följande:
- Förenkling av koden: Du kan skriva komplexa SELECTs en gång, kapsla in dem i vyn och trigga dem från den, som om det vore vilken tabell som helst;
- Säkerhetsfrågor: Anta att du har konfidentiell information i vissa tabeller och att du vill att endast vissa användare ska ha tillgång till dem. Vissa kolumner i dessa tabeller måste dock vara tillgängliga för alla användare. Ett effektivt sätt att lösa problemet är att skapa en vy och dölja de känsliga kolumnerna. På så sätt kan man undertrycka åtkomsträttigheterna till den ursprungliga tabellen och frigöra åtkomst till vyn;
- Möjlighet till optimering av frågor genom att implementera indexerade vyer.
Indexerade vyer i praktiken
Vyer kapslar in SELECT-utsagor, vilket innebär att SELECT-utsagorna som är associerade med dem exekveras närhelst de utlöses. Vyer skapar inte arkiv för de data de returnerar (vilket tabellen gör). Det skulle vara bra om vi kunde ”materialisera” resultatet av SELECT-kommandot som finns i vyn i en tabell och skapa index för att underlätta åtkomsten till det. De indexerade vyerna gör just det. Att utföra ett SELECT i en indexerad vy har samma effekt som att utföra ett select i en konventionell tabell.
Det huvudsakliga syftet med indexerade vyer är att öka prestandan, och fördelen med SQL Server är att låta exekveringsplaner ta hänsyn till den indexerade vyn som ett sätt att få tillgång till data, även om vyns namn inte var explicit i frågan. Detta är möjligt i Enterprise Edition av SQL Server 2000, där kommandoptimeraren kan välja data direkt i den indexerade vyn (i stället för att välja de rådata som finns i tabellen), vilket vi kommer att se härnäst.
Skapa en indexerad vy steg för steg
- Det första steget i konfigureringen av miljön är att ställa in tillståndet för vissa parametrar i sessionen där du vill skapa och använda vyn, eftersom den indexerade vyn ”materialiseras” i en tabell och inget kan störa dess resultat. Tänk dig till exempel följande scenario:
- En viss inställning, som påverkar resultatet av en SELECT (t.ex. concat_null_yelds_null), ställs in innan den indexerade vyn skapas;
- Den indexerade vyn skapas; observera att resultatet av vyn kommer att ”materialiseras” på disken i enlighet med inställningen som ställdes in i det föregående steget;
- Därefter inaktiveras inställningen och den indexerade vyn körs av användaren. Eftersom vyn har materialiserats kommer vi att få ett resultat som inte överensstämmer med den aktuella konfigurationen.
I listning 2 visas till exempel skillnaden i resultatet av ett kommando när egenskapen concat_null_yields_null ändras.
set concat_null_yields_null ON print null + 'abc' -------------------------------------- Set concat_null_yields_null OFF print null + 'abc' -------------------------------------- abcFöreställ dig vad som skulle hända om den indexerade vyn skapades med egenskapen concat_null_yields_null aktiverad, men den aktuella sessionen var med den egenskapen inaktiverad – samma SELECT skulle leda till olika resultat!
Detta problem löstes på ett enkelt sätt – för att skapa och använda indexerade vyer är det obligatoriskt att konfigurera miljön enligt en lista med standardvärden. På så sätt är det omöjligt att få olika resultat, eftersom vyn helt enkelt inte fungerar om någon av inställningarna är inställd på ett avvikande värde.
Tabell 1 visar dessa inställningar och deras respektive standardvärden.
| Inställning | Id (*) | Krävt tillstånd för indexerade vyer | Standard för SQL Server 2000 | Standard för OLE DB- (=ADO) eller ODBC-anslutningar | Standard för anslutningar som använder DB-biblioteket | ||
|---|---|---|---|---|---|---|---|
| ANSI_NULLS | 32 | ON | OFF | ON | OFF | ||
| ANSI_PADDING | 16 | ON | ON | ON | OFF | ||
| ANSI_WARNING | 8 | ON | ON | OFF | ON | OFF | |
| ARITHABORT | 64 | ON | OFF | OFF | OFF | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | 4096 | ON | OFF | ON | OFF | OFF | |
| QUOTED_IDENTIFIER | 256 | ON | OFF | ON | OFF | ||
| NUMERIC_ROUNDABORT | 8192 | OFF | OFF | OFF | OFF | OFF |
(*) Id används i kommandot sp_configure. Läs avsnittet ”Krävande inställningar för indexerade vyer” för att kontrollera vad varje inställning gör. Det finns två sätt att ändra värdet på en konfiguration:
- Direkt i sessionen: kör kommandot set ON | OFF
- Ändra det befintliga standardvärdet för servern: kör sp_Configure ’user options’, . Id-numret för varje konfiguration framgår av tabell 1.
Notera: AritHabort har id 64 och Quoted_Identifier har id 256. För att länka till exempel Quoted_Identifier + AritHabort skulle vi utföra sp_cofigure och som parameter skicka resultatet av 64+256 (=320): sp_configure ’user options’, 320. En fullständig lista över de id som tilldelats varje konfiguration finns på http://msdn.microsoft.com/library/default.asp?url=/library/en-us/adminsql/ad_config_9b1q.asp.
För att bekräfta tillståndet för var och en av parametrarna i tabell 1 använder du funktionen SessionProperty(’parameter name’) eller kommandot DBCC UserOptions.
Sätt alla parametrar enligt kolumnen ”required state for indexed views” i tabell 1 – om du inte gör detta kommer SQL Server inte att tillåta dig att skapa/utföra den indexerade vyn.
Skapa den indexerade vyn
Vi kommer att skapa en vy för att summera det dagliga beloppet som sålts i tabellen Order Details, som finns i NorthWind-databasen. Se Listing 3.
use NorthWind go create view vi_vendas_mes with SchemaBinding as select ano = datepart(yyyy,OrderDate), mes = datepart(mm,OrderDate), qtde_total = sum(Quantity), contador = count_big(*) from dbo.Orders o inner join dbo. od on o.OrderId = od.OrderId group by datepart(yyyy,o.OrderDate),datepart(mm,o.OrderDate) goVi måste observera vissa särdrag när vi skapar indexerade vyer:
- Vyn måste vara deterministisk. En vy är deterministisk om vi endast använder deterministiska funktioner i dess kod. Samma SELECT-kommando som utförs upprepade gånger på en indexerad vy (med en statisk bas) kan inte ge olika resultat. Deterministiska funktioner garanterar att resultatet av en funktion förblir oförändrat oavsett hur många gånger den utförs. Funktionen DatePart är till exempel deterministisk, eftersom den alltid ger samma resultat för ett visst datum. Funktionen getdate() returnerar ett annat värde varje gång den utförs. En fullständig lista över SQL Server 2000-deterministiska funktioner finns på http://msdn.microsoft.com/library/default.asp?url=/library/en-us/createdb/cm_8_des_08_95v7.asp
- Kontrollera att det inte finns några syntaxbegränsningar. De klausuler, funktioner och frågetyper som anges nedan kan inte integrera schemat för en indexerad vy:
- MIN, MAX,TOP
- VARIANCE,STDEV,AVG
- COUNT(*)
- SUMMA på kolumner som tillåter nollvärden
- DISTINCT
- ROWSET-funktionen
- Avledda tabeller, self joins, subqueries, outer joins
- DISTINCT
- UNION
- Float, text, ntext och image
- COMPUTE och COMPUTE BY
- HAVING, CUBE och ROLLUP
Det är nödvändigt att skapa de indexerade vyerna med SchemaBinding. För att innehållet i vyn ska vara konsekvent kan du inte ändra strukturen på de tabeller som ligger till grund för vyn. För att undvika den här typen av problem är det obligatoriskt att använda SchemaBinding när du skapar indexerade vyer, eftersom du med det här alternativet inte kan ändra tabellstrukturen utan att först ta bort vyn.
För att använda GROUP BY-klausulen är det obligatoriskt att inkludera funktionen COUNT_BIG(*). Funktionen count_big(*) gör samma sak som count(*), men returnerar ett värde av typen bigint (8 bytes).
Informera alltid ägaren av de objekt som refereras i den indexerade vyn. Använd select * from dbo.Orders istället för select * from Orders, eftersom det är möjligt att ha tabeller med samma namn men med olika ägare. Eftersom schemabindningsalternativet är obligatoriskt behöver SQL Server den exakta objektspecifikationen för att förhindra ändringar i schemat.
Skapa ett klusterindex i vyn (materialisering)
Vyn som skapades i punkt 2 fungerar ännu inte som en indexerad vy, eftersom resultatet av select-kommandot inte har materialiserats till en tabell. Du kan bekräfta detta genom att köra kommandot sp_spaceused i Query Analyzer, som returnerar antalet rader och det utrymme som används av tabellerna (Listing 4).
sp_SpaceUsed vi_vendas_mes -------------------------------------------------------------------------------------- Server: Msg 15235, Level 16, State 1, Procedure sp_spaceused, Line 91 Views do not have space allocated.Observera i Listing 5 att bearbetningen av vyn är rent logisk, så att värdet för Physical Reads (fysisk läsning) är noll. Notera värdena för logiska läsningar och fysiska läsningar (1672+0+4+0=1676) – vi kommer att använda dessa värden i våra framtida jämförelser.
Set statistics io ON Select * from vi_vendas_mesgo---------------------------------------------------------ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 591996 8 1322 691996 9 1124 57.....(23 row(s) affected)Table 'Order Details'. Scan count 830, logical reads 1672, physical reads 0, read-ahead reads 0.Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.För att kontrollera om vyn kan indexeras (materialiserad), det vill säga om den skapades enligt de standarder och inställningar som krävs för indexerade vyer, bör resultatet av följande SELECT vara lika med 1.
select ObjectProperty(object_id('vi_vendas_mes'),'IsIndexable')Vid bekräftelse av förutsättningarna kan vi nu skapa indexet. Syntaxen har samma format som när du skapar index i konventionella tabeller:
create unique clustered index pk_ano_mes on vi_vendas_mes (ano,mes)Notera att klusterindexet krävs eftersom det genererar sidor med data. Du kan skapa andra index än klusterindex i indexerade vyer först efter att du har skapat klusterindexet.
Nu har SELECT som finns i vyn materialiserats, vilket kan bevisas med kommandot sp_spaceused i Query Analyzer (Listing 6).
sp_SpaceUsed vi_vendas_mêsgo-----------------------------------------------------Name Rows Reserved data index_size Unusedvi_vendas_mes 23 24 KB 8 KB 16 KB 0 KBAnvända indexerade vyer
Ett sätt att komma åt en indexerad vy (liksom en konventionell vy) är att hänvisa till dess namn i kommandot SELECT:
select * from vi_vendas_mesGjämför volymen förflyttade sidor i lista 5 (1672+4=1676) med den i lista 7 (2+0=2). Skillnaden är betydande – genom att skapa den indexerade vyn minskade den totala I/O som krävdes med 1674 sidor.
Set statistics io ON select * from vi_vendas_mes go --------------------------------------------------------- ano mes qtde_total contador ----------- ----------- ------------- -------------------- 1996 7 1462 59 1996 9 1124 57 ..... (23 row(s) affected) Table 'vi_vendas_mes'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.Vi kan titta på ett annat exempel. I figur 1 visas en plan för utförandet av en sökning. Bekräfta att vyn valdes trots att den inte fanns med i raden SELECT.
Under konstruktionen av exekveringsplanen för sökningen upptäckte optimeraren att det redan fanns för-summerade data för sökningen i vi_sales_mes och valde att välja data direkt i den indexerade vyn.
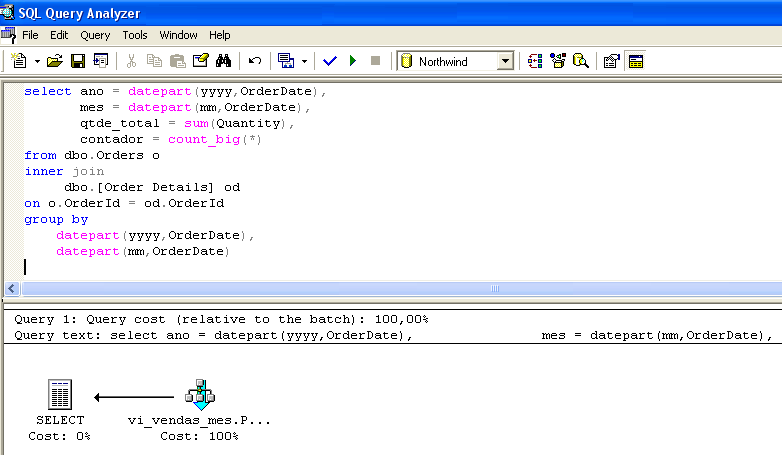
Notera att den sökning som utförs i figur 1 är identisk med den som finns i vyn vi_sales_mes. Optimerarens tillgång till vyn är dock oberoende av likheten mellan den utförda sökfrågan och sökfrågan för vyn. Vid sökprocessorns val av indexerad vy tas endast hänsyn till kostnadseffektiviteten. På så sätt behöver de frågor som utförs inte vara identiska med vyn (se figur 3).
Det är dock nödvändigt att följa vissa regler för att den indexerade vyn ska beaktas av sökoptimeraren:
- Förbindelsen som finns i vyn måste ”finnas med” i frågan: om frågan utför en sammanfogning mellan tabellerna A och B och vyn utför en sammanfogning mellan A och C kommer vyn inte att utlösas i exekveringsplanen. Men om frågan utför en sammanfogning mellan A, B och C kan vyn utlösas.
- De villkor som anges i frågan måste stämma överens med villkoren i vyn: i SELECT i figur 2 kommer den indexerade vyn vi_sales_mes inte att beaktas eftersom where-klausulen inte fanns med i koden för vyn, vilket ledde till att rader med kvantitet <= 5 beräknades i sammanfogningen.
Om frågan däremot har villkoret where where sum(Quantity) > 5, kommer vyn vi_sales_mes att beaktas i exekveringsplanen, eftersom frågevillkoret är en delmängd av SELECT som finns i vyn.
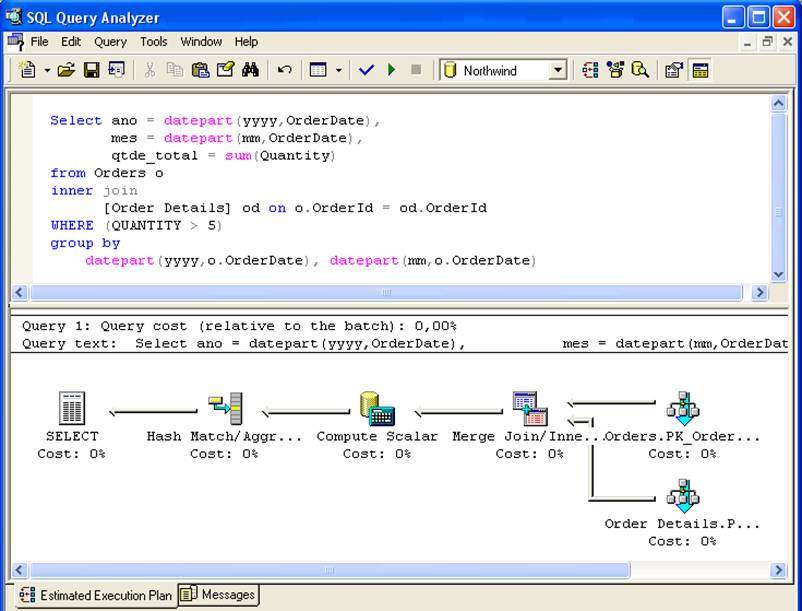
Kolumner med aggregeringsfunktioner i frågan måste ”finnas med” i definitionen av vyn: om vyn returnerar kolumnen qtde=sum(Kvantitet) och frågan har kolumnen vlr_unit=sum(Enhetspris), kommer vyn inte att beaktas.
Figur 3 visar ett SELECT-kommando som gör det möjligt att bevisa intelligensen hos kommandoptimeraren – AVG(Quantity)-beräkningen har ersatts av divisionen mellan SUM(Quantity) / Count_Big(*), som representeras av ikonen Compute Scalar. Predikatet where sum(Quantity) > 1500 (representerat av ikonen Filter) beaktas också.
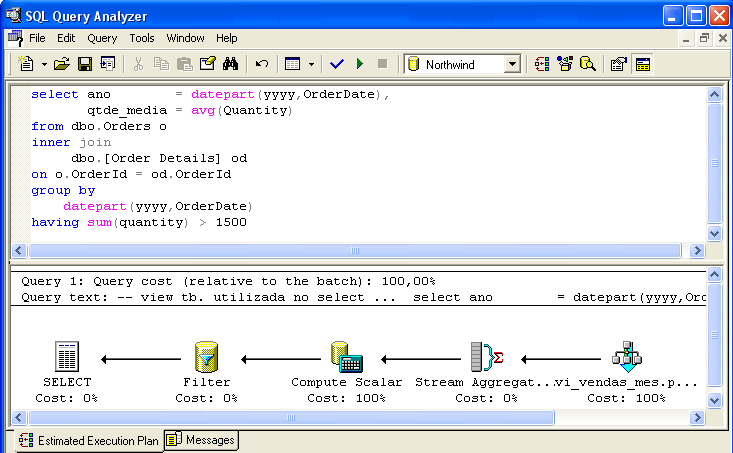
Generella överväganden om användning av indexerade vyer:
- Indexerade vyer kan skapas i alla versioner av SQL Server 2000. Det är dock bara i Enterprise Edition-versionen som de väljs automatiskt av frågeoptimeraren.
- I andra versioner än Enterprise måste du använda NoExpand-hänvisningen för att få tillgång till den indexerade vyn som en konventionell tabell. Om NoExpand inte används kommer den indexerade vyn att betraktas som en ”normal” vy.
Observera: Expand-hänvisningen gör det omvända av NoExpand: den behandlar den indexerade vyn som en ”normal” vy och tvingar SQL Server att utföra SELECT-anvisningen under körningsfasen.
- Underhållet av en indexerad vy sker automatiskt (precis som i index); det kräver ingen ytterligare synkronisering. På grund av sin egen egenskap (den lagrar vanligen för-summerade data) tenderar uppdateringen att vara lite långsammare än för konventionella index.
- Användningen av indexerade vyer i OLTP-baser kräver försiktighet, för även om de ger bra prestanda i sökningar, orsakar de overhead i de processer som ändrar de tabeller som är relaterade i vyn. I situationer där hög skrivprestanda krävs, med frekventa uppdateringar, rekommenderas inte skapandet av indexerade vyer.
- Som den gör med index kommer optimeraren att analysera vykoden i Enterprise-versioner som en del av processen för att välja den bästa exekveringsplanen för en fråga. Om det finns många indexerade vyer som kan exekveras för samma fråga kan det dock bli en avsevärd ökning av denna valtid eftersom alla vyer kommer att analyseras. Använd därför sunt förnuft när du implementerar vyerna.
Krävda inställningar för indexerade vyer
ANSI_NULLS
Definierar hur jämförelser med nollvärden utförs (Listing 8).
set ANSI_NULLS ON declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' ------------------------------------- FALSO set ANSI_NULLS OFF declare @var char(10) set @var = null if @var = null print 'VERDADEIRO' else print 'FALSO' -------------------------------------- VERDADEIROANSI_PADDING
Destinerar hur kolumnerna char, varchar, binary och varbinary ska lagras när deras innehåll är mindre än den storlek som definieras i tabellstrukturen. Standardinställningen för SQL Server 2000 är att ansi_padding är aktiverad (=ON); i det här läget gäller följande regler:
- När du uppdaterar kolumner med tecken, läggs vitrymder till i slutet av strängen om den är mindre än den storlek som definieras i kolumnstrukturen. Samma regel gäller för binära kolumner (i det fallet fylls utrymmet med en sekvens av nollor)
- Varkar- eller varbinärkolumner följer inte ovanstående regel: de behåller alltid sin ursprungliga storlek.
ARITHABORT
När den är aktiverad avslutas körningen av en fråga när en division med noll eller någon form av överflöde inträffar.
QUOTED_IDENTIFIER
När den är aktiverad tillåts användning av dubbla citationstecken för att specificera namn på tabeller, kolumner osv. – På så sätt kan dessa namn innehålla mellanslag och specialtecken.
CONCAT_NULL_YELDS_NULL
Kontrollerar resultatet av att sammanfoga strängar med nollvärden. När den är aktiverad bestämmer du att den här sammanfogningen måste returnera ett nollvärde, annars returneras strängen.
ANSI_WARNINGS
När den är aktiverad bestämmer du genereringen av felmeddelanden när:
- du använder sammanfattningsfunktioner och nollvärden hittas i frågeintervallet;
- divisioner med noll eller aritmetiskt överflöde hittas.
NUMERIC_ROUNDABORT
Kontrollerar hur SQL Server ska gå vidare när numerisk precision går förlorad i aritmetiska operationer. Om parametern är aktiverad och en variabel med en precision på två decimaler får ett värde med tre decimaler, avbryts operationen. Om parametern är inaktiverad kommer värdet att trunkeras till två decimaler.
Slutsats
När det gäller optimering av frågor är indexerade vyer ett bra val för att utnyttja prestanda. Utvärdera därför noggrant de frågor som handlar om sammanfattningar och som utförs med viss frekvens och skapa indexerade vyer. Resultatet är värt det!