




Statistisk analys: Signifikans och konfidensintervall
Du behöver därför ett sätt att mäta hur säker du är på att ditt resultat är korrekt och inte bara har uppstått av en slump. Statistiker använder två sammanlänkade begrepp för detta: konfidens och signifikans.
Denna sida förklarar dessa begrepp.
Statistisk signifikans
Begreppet signifikans har en mycket speciell innebörd inom statistiken. Det talar om hur sannolikt det är att ditt resultat inte har uppstått av en slump.

I diagrammet representerar den blå cirkeln hela populationen. När du tar ett urval kan ditt urval vara från hela populationen. Det är dock mer sannolikt att det är mindre. Om allt kommer från den gula cirkeln skulle du ha täckt en ganska stor del av populationen. Men du kan också ha otur (eller ha utformat ditt provtagningsförfarande på ett dåligt sätt) och bara ta ett prov från den lilla röda cirkeln. Detta skulle få allvarliga konsekvenser för huruvida ditt urval är representativt för hela populationen.
Ett av de bästa sätten att se till att du täcker en större del av populationen är att använda ett större urval. Din urvalsstorlek påverkar starkt noggrannheten hos dina resultat (och det finns mer om detta på vår sida om provtagning och urvalsplanering).
En annan faktor påverkar dock också noggrannheten: variationen inom själva populationen. Du kan bedöma detta genom att titta på mått på spridningen av dina data (och för mer information om detta se vår sida om Enkel statistisk analys). Där det finns mer variation är det större chans att du väljer ett urval som inte är typiskt.
Begreppet signifikans sammanför helt enkelt urvalsstorlek och populationsvariation och gör en numerisk bedömning av chanserna att du har gjort ett urvalsfel: det vill säga att ditt urval inte representerar populationen.
Signifikans uttrycks som en sannolikhet för att dina resultat har uppstått av en slump, allmänt känt som ett p-värde. I allmänhet vill du att det ska vara mindre än ett visst värde, vanligtvis antingen 0,05 (5 %) eller 0,01 (1 %), även om vissa resultat även rapporterar 0,10 (10 %).
Nollhypotes och alternativhypotes
När du utför ett experiment eller en marknadsundersökning vill du i allmänhet veta om det du gör har en effekt. Du kan därför uttrycka det som en hypotes:
-x kommer att ha en effekt på y.
Detta kallas inom statistiken för den alternativa hypotesen, ofta kallad H1.
Nollhypotesen, eller H0, är att x inte har någon effekt på y.
Statistiskt sett är syftet med signifikanstestning att se om dina resultat tyder på att du måste förkasta nollhypotesen – i så fall är det troligare att den alternativa hypotesen är sann.
Om dina resultat inte är signifikanta kan du inte förkasta nollhypotesen och du måste dra slutsatsen att det inte finns någon effekt.
P-värdet är sannolikheten för att du skulle ha fått de resultat du har fått om din nollhypotes är sann.
Beräkning av signifikans
Ett sätt att beräkna signifikans är att använda en z-score. Detta beskriver avståndet från en datapunkt till medelvärdet, i form av antalet standardavvikelser (för mer information om medelvärde och standardavvikelse, se vår sida om enkel statistisk analys).
För en enkel jämförelse beräknas z-score med hjälp av formeln:
$$z=\frac{x – \mu}{\sigma}$$$
där \(x\) är datapunkten, \(\mu\) är medelvärdet för populationen eller fördelningen och \(\sigma\) är standardavvikelsen.
Föreställ dig till exempel att vi vill testa om en spelapp är mer populär än andra spel. Låt oss säga att den genomsnittliga spelappen laddas ner 1000 gånger, med en standardavvikelse på 110. Vårt spel har laddats ner 1200 gånger. Dess z-poäng är:
$$z=\frac{1200-1000}{110}=1,81$$$
En högre z-poäng signalerar att det är mindre troligt att resultatet har uppstått av en slump.
Du kan använda en vanlig statistisk z-tabell för att omvandla din z-poäng till ett p-värde. Om ditt p-värde är lägre än din önskade signifikansnivå är dina resultat signifikanta.
Med hjälp av z-tabellen omvandlas z-värdet för vår spelapp (1,81) till ett p-värde på 0,9649. Detta är bättre än vår önskade nivå på 5 % (0,05) (eftersom 1-0,9649 = 0,0351 eller 3,5 %), så vi kan säga att resultatet är signifikant.
Notera att det finns en liten skillnad för ett urval från en population, där z-värdet beräknas med hjälp av formeln:
$$z=\frac{(x-\mu)}{(\sigma/\sqrt n)}$$$
där x är datapunkten (vanligen ditt urvalsmedelvärde), µ är medelvärdet för populationen eller fördelningen, σ är standardavvikelsen och √n är kvadratroten av urvalets storlek.
Ett exempel kommer att göra detta tydligare.
Antag att du kontrollerar om biologistudenter tenderar att få bättre betyg än sina kamrater som studerar andra ämnen. Du kanske upptäcker att det genomsnittliga provbetyget för ett urval av 40 biologer är 80, med en standardavvikelse på 5, jämfört med 78 för alla studenter vid det universitetet eller den skolan.
$$z=\frac{(80-78)}{(5/\sqrt 40)}=2,53$$$
Med hjälp av z-tabellen motsvarar 2,53 ett p-värde på 0,9943. Du kan subtrahera detta från 1 för att få 0,0054. Detta är lägre än 1 %, så vi kan säga att resultatet är signifikant på 1 %-nivån och att biologer får bättre resultat på prov än den genomsnittliga studenten vid detta universitet.
Bemärk att detta inte nödvändigtvis betyder att biologer är smartare eller bättre på att klara prov än de som studerar andra ämnen. Det kan faktiskt betyda att proven i biologi är lättare än proven i andra ämnen. Att hitta ett signifikant resultat är INTE ett bevis på orsakssamband, men det talar om för dig att det kan finnas en fråga som du vill undersöka.
Det finns mer om testning av signifikans för provmedelvärden och testning av skillnader mellan grupper på vår sida om hypotesutveckling och testning.
Konfidensintervall
Ett konfidensintervall (eller konfidensnivå) är ett värdeintervall som har en given sannolikhet för att det sanna värdet ligger inom det.
Effektivt sett mäter det hur säker du är på att medelvärdet i ditt urval (urvalsmedelvärdet) är detsamma som medelvärdet i den totala populationen från vilken urvalet togs (populationsmedelvärdet).
Till exempel, om ditt medelvärde är 12,4 och ditt 95-procentiga konfidensintervall är 10,3-15,6 betyder det att du är 95 procent säker på att det sanna värdet av ditt populationsmedelvärde ligger mellan 10,3 och 15,6. Med andra ord är det kanske inte 12,4, men du är ganska säker på att det inte är mycket annorlunda.
Diagrammet nedan visar detta i praktiken för en variabel som följer en normalfördelning (för mer information om detta, se vår sida om statistiska fördelningar).

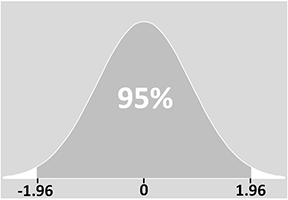
Den exakta innebörden av ett konfidensintervall är att om du skulle göra ditt experiment många, många gånger, så skulle 95 % av de intervall som du konstruerade från dessa experiment innehålla det sanna värdet. Med andra ord, i 5 % av dina experiment skulle ditt intervall INTE innehålla det sanna värdet.
Du kan se i diagrammet att det finns 5 % chans att konfidensintervallet inte innehåller populationsmedelvärdet (de två ”svansarna” på 2,5 % på vardera sidan). Med andra ord kommer det värde som vi får fram för konfidensintervallet i ett av 20 prov eller experiment inte att inkludera det sanna medelvärdet: populationens medelvärde kommer faktiskt att falla utanför konfidensintervallet.
Beräkning av konfidensintervallet
För att beräkna ett konfidensintervall använder du dig av dina provvärden och några standardmått (medelvärde och standardavvikelse) (och för mer information om hur man beräknar dessa, se vår sida om Enkel statistisk analys).
Det är lättast att förstå med ett exempel.
Antag att vi tog stickprov på längden hos en grupp på 40 personer och fann att medelvärdet var 159,1 cm och standardavvikelsen var 25,4.
Standardavvikelse för konfidensintervall
Det är egentligen så att du skulle använda populationens standardavvikelse för att beräkna konfidensintervallet. Det är dock mycket osannolikt att du skulle veta vad detta var.
Turligtvis kan du använda urvalets standardavvikelse, förutsatt att du har ett tillräckligt stort urval. Man är allmänt överens om att gränsen är ett urval på 30 eller mer, men ju större, desto bättre.
Vi måste ta reda på om vårt medelvärde är en rimlig uppskattning av alla människors längd, eller om vi har valt ett särskilt högt (eller kort) urval.
Vi använder en formel för att beräkna ett konfidensintervall. Denna är:
$$mean \pm z \frac{(SD)}{\sqrt n}}$$$
Varvid SD = standardavvikelse och n är antalet observationer eller urvalets storlek.
Z-värdet hämtas från statistiska tabeller för den referensfördelning vi valt. Dessa tabeller ger z-värdet för ett visst konfidensintervall (till exempel 95 % eller 99 %).
I det här fallet mäter vi människors längd och vi vet att befolkningslängder följer en (i stort sett) normalfördelning (för mer information om detta, se vår sida om statistiska fördelningar).
Vi kan därför använda värdena för en normalfördelning.
Z-värdet för ett 95-procentigt konfidensintervall är 1,96 för normalfördelningen (hämtat från statistiska standardtabeller).
Med hjälp av formeln ovan är det 95-procentiga konfidensintervallet därför:
$$$159,1 \pm 1,96 \frac{(25,4)}{\sqrt 40}}$$$
När vi utför den här beräkningen får vi fram att konfidensintervallet är 151,23-166,97 cm. Det är därför rimligt att säga att vi därför är 95 % säkra på att populationens medelvärde ligger inom detta intervall.
Förståelse av z-poäng eller z-värde
Z-poängen är ett mått på standardavvikelser från medelvärdet. I vårt exempel vet vi därför att 95 % av värdena kommer att ligga inom ± 1,96 standardavvikelser från medelvärdet.
Bedömning av ditt konfidensintervall
En allmän tumregel är att ett litet konfidensintervall är bättre. Konfidensintervallet blir smalare när din urvalsstorlek ökar, vilket är anledningen till att ett större urval alltid är att föredra. Som vår sida om urval och urvalsplanering förklarar skulle ditt ideala experiment omfatta hela populationen, men detta är vanligtvis inte möjligt.
Slutsats
Konfidensintervall och signifikans är standardmetoder för att visa kvaliteten på dina statistiska resultat. Du förväntas rapportera dem rutinmässigt när du utför en statistisk analys, och du bör i allmänhet rapportera exakta siffror. Detta garanterar att din forskning är giltig och tillförlitlig.