




Enterprise Data Warehouse: Concepts, Architecture, and Components
Reading time: 12 minutes
Throughout the day we make many decisions relying on previous experience. Agyunk trilliónyi bitnyi adatot tárol a múltbeli eseményekről, és ezeket az emlékeket minden alkalommal felhasználja, amikor azzal szembesülünk, hogy döntést kell hoznunk. Az emberekhez hasonlóan a vállalatok is rengeteg adatot generálnak és gyűjtenek a múltról. És ezek az adatok felhasználhatók a jobb döntések meghozatalához.
Míg az agyunk a feldolgozásra és a tárolásra egyaránt szolgál, a vállalatoknak többféle eszközre van szükségük az adatok feldolgozásához. Az egyik legfontosabb ezek közül pedig az adattárház.
Ebben a cikkben arról lesz szó, hogy mi is az a vállalati adattárház, milyen típusai és funkciói vannak, és hogyan használják az adatfeldolgozásban. Meghatározzuk, hogy miben különböznek a vállalati adattárházak a megszokottaktól, milyen típusú adattárházak léteznek, és hogyan működnek. A hangsúlyt arra helyezzük, hogy tájékoztatást adjunk a raktárépítés egyes architekturális és koncepcionális megközelítéseinek üzleti értékéről.
Mi az a vállalati adattárház?
Ha tudja, mennyi a terabájt, akkor valószínűleg lenyűgözi az a tény, hogy a Netflix 2016-ban mintegy 44 terabájtnyi adatot tárolt a raktárában. Már a méret is utal arra, hogy miért nevezzük raktárnak, és nem csak adatbázisnak. Kezdjük tehát az alapokkal.
A vállalati adattárház (Enterprise Data Warehouse, EDW) egyfajta vállalati adattárház, amely egy vállalat összes korábbi üzleti adatát tárolja és kezeli. Az információk általában különböző rendszerekből származnak, például ERP-ekből, CRM-ekből, fizikai nyilvántartásokból és egyéb sima fájlokból. Az adatok további elemzésre való előkészítése érdekében azokat egyetlen tárolóhelyen kell elhelyezni. Így a különböző üzleti egységek lekérdezhetik és több szempontból elemezhetik az információkat.
Az adattárházzal egy vállalkozás hatalmas adathalmazokat kezelhet, anélkül, hogy több adatbázist kellene adminisztrálnia. Az ilyen gyakorlat az adatok tárolásának egy jövőbiztos módja az üzleti intelligencia (BI) számára, amely a nyers adatok cselekvőképes meglátásokká történő átalakításának módszereinek/technológiáinak összessége. Mivel az EDW fontos része, a rendszer az információt tároló emberi agyhoz hasonlít, de szteroidokon.
Enterprise data warehouse vs. szokásos adattárház: mi a különbség?
Minden adattárház olyan adatbázis, amely az egyik oldalon adatintegrációs eszközökön, a másik oldalon pedig analitikai interfészeken keresztül mindig kapcsolatban áll a nyers adatforrásokkal. Ha ez így van, akkor miért különítjük el a vitára a vállalati formát?
Minden raktár olyan tárolást biztosít, amely mechanizmusokkal rendelkezik az adatok átalakítására, mozgatására és a végfelhasználó számára történő bemutatására. A különbség a szokásos adattárház és a vállalati adattárház között a sokkal szélesebb architekturális sokféleségben és funkcionalitásban rejlik. Az összetett struktúra és méret miatt az EDW-ket gyakran kisebb adatbázisokra bontják, így a végfelhasználók kényelmesebben lekérdezhetik ezeket a kisebb adatbázisokat. Ezt figyelembe véve egy vállalati raktárra összpontosítunk, hogy a funkcionalitás teljes spektrumát lefedjük.
A raktár mérete azonban nem határozza meg annak technikai komplexitását, az analitikai és jelentési képességekkel, az adatmodellek számával és magával az adatokkal szemben támasztott követelményeket. Ahhoz tehát, hogy megértsük, mitől lesz egy raktár raktár, merüljünk el az alapvető fogalmakban és funkciókban.
Enterprise Data Warehouse fogalmak és funkciók
Minden csengőszóval és sípszóval együtt minden raktár szívében alapvető fogalmak és funkciók rejlenek. Ezek a pillérek határozzák meg a raktárat mint technológiai jelenséget:
A végső tárolóként szolgál. A vállalati adattárház a szervezetben valaha is előforduló összes vállalati üzleti adat egységes tárolója.
Tükrözi a forrásadatokat. Az EDW az adatokat az eredeti tárolóhelyeiről, például a Google Analytics, a CRM-ek, az IoT-eszközök stb. forrásaiból nyeri. Ha az adatok több rendszerben szétszóródnak, az kezelhetetlen. Az EDW célja tehát az, hogy az eredeti forrásadatok hasonlóságát egyetlen tárolóhelyen biztosítsa. Mivel a vállalaton belül és kívül is mindig keletkeznek új, releváns adatok, az adatáramlásnak külön infrastruktúrára van szüksége az adatok kezelésére, mielőtt azok egy raktárba kerülnének.
Szerkesztett adatok tárolása. Az EDW-ben tárolt adatok mindig szabványosított és strukturáltak. Ez lehetővé teszi a végfelhasználók számára, hogy BI-felületeken keresztül lekérdezzék azokat, és jelentéseket készítsenek. És ez az, ami megkülönbözteti az adattárházat az adattótól. Az adattavakat elemzési célú strukturálatlan adatok tárolására használják. De a raktárakkal ellentétben az adattavakat inkább az adatmérnökök/tudósok használják a nagy mennyiségű nyers adatokkal való munkára.
Tárgyorientált adatok. A raktár fő fókusza az üzleti adatok, amelyek különböző területekre vonatkozhatnak. Annak megértéséhez, hogy az adatok mire vonatkoznak, mindig egy adott téma köré strukturálódnak, amelyet adatmodellnek neveznek. Egy téma lehet például egy értékesítési régió vagy egy adott cikk teljes értékesítése. Emellett metaadatokkal is kiegészítik, hogy részletesen megmagyarázzák, honnan származik minden egyes információ.
Az időfüggő. Az összegyűjtött adatok általában történeti adatok, mert múltbeli eseményeket írnak le. Annak megértéséhez, hogy mikor és mennyi ideig zajlott egy bizonyos tendencia, a legtöbb tárolt adatot általában időszakokra osztják.
Nem illékony. Miután egy raktárba kerültek, az adatok soha nem törlődnek onnan. Az adatok manipulálhatók, módosíthatók vagy frissíthetők a forrásváltozások miatt, de soha nem arra szolgálnak, hogy töröljék őket, legalábbis a végfelhasználók. Mivel historikus adatokról beszélünk, a törlések elemzési célokra kontraproduktívak. Mégis néhány évente egyszer előfordulhatnak általános revíziók, hogy megszabaduljunk a nem releváns adatoktól.
Az alapelveket figyelembe véve megvizsgáljuk a DW-k megvalósítási típusait.
Adattárház típusok
Az EDW funkcióit figyelembe véve mindig van helye a vitának, hogy technikailag hogyan tervezzük meg. Az adattárolás és -feldolgozás esetében ezek specifikusak és megkülönböztethetők a különböző típusú vállalkozások számára. Az adatmennyiségtől, az analitikai összetettségtől, a biztonsági kérdésektől és a költségvetéstől függően természetesen mindig van lehetőség arra, hogy hogyan alakítsuk ki a rendszert.
Klasszikus adattárház
Az EDW klasszikus változatának tekinthető az egyesített tárolás, amely dedikált hardverrel és szoftverrel rendelkezik. A fizikai tárolás esetén nem kell adatintegrációs eszközöket beállítani több adatbázis között. Ehelyett az EDW API-kon keresztül csatlakoztatható az adatforrásokhoz, hogy folyamatosan forrásinformációkat szerezzen és a folyamat során átalakítsa azokat. Tehát minden munka vagy a staging area-ban (az a hely, ahol az adatokat a DW-be való betöltés előtt átalakítják), vagy magában a raktárban történik.
A klasszikus adattárház szuperlatívusznak tekinthető a virtuálishoz képest (amelyet alább tárgyalunk), mivel nincs további absztrakciós réteg. Ez leegyszerűsíti az adatmérnökök munkáját, és megkönnyíti az adatáramlás kezelését az előfeldolgozási oldalon, valamint a tényleges jelentéskészítést. A klasszikus raktár hátrányai a tényleges megvalósítástól függnek, de a legtöbb vállalkozás számára ezek a következők:
- Drága technológiai infrastruktúra, mind hardver, mind szoftver tekintetében;
- Adatmérnökökből és DevOps-szakemberekből álló csapat felállítása és karbantartása a teljes adatplatform felállításához és karbantartásához.
Mikor érdemes használni: Minden méretű szervezet számára megfelelő, amely feldolgozni és hasznosítani szeretné az adatait. A klasszikus adattárházak lehetővé teszik az adatplatform különböző architekturális stílusokba való morfondírozását, valamint a célzott skálázást.
Virtuális adattárház
A virtuális adattárház a klasszikus adattárház alternatívájaként használt EDW egyik típusa. Lényegében ezek több, virtuálisan összekapcsolt adatbázisok, így egyetlen rendszerként lekérdezhetők.
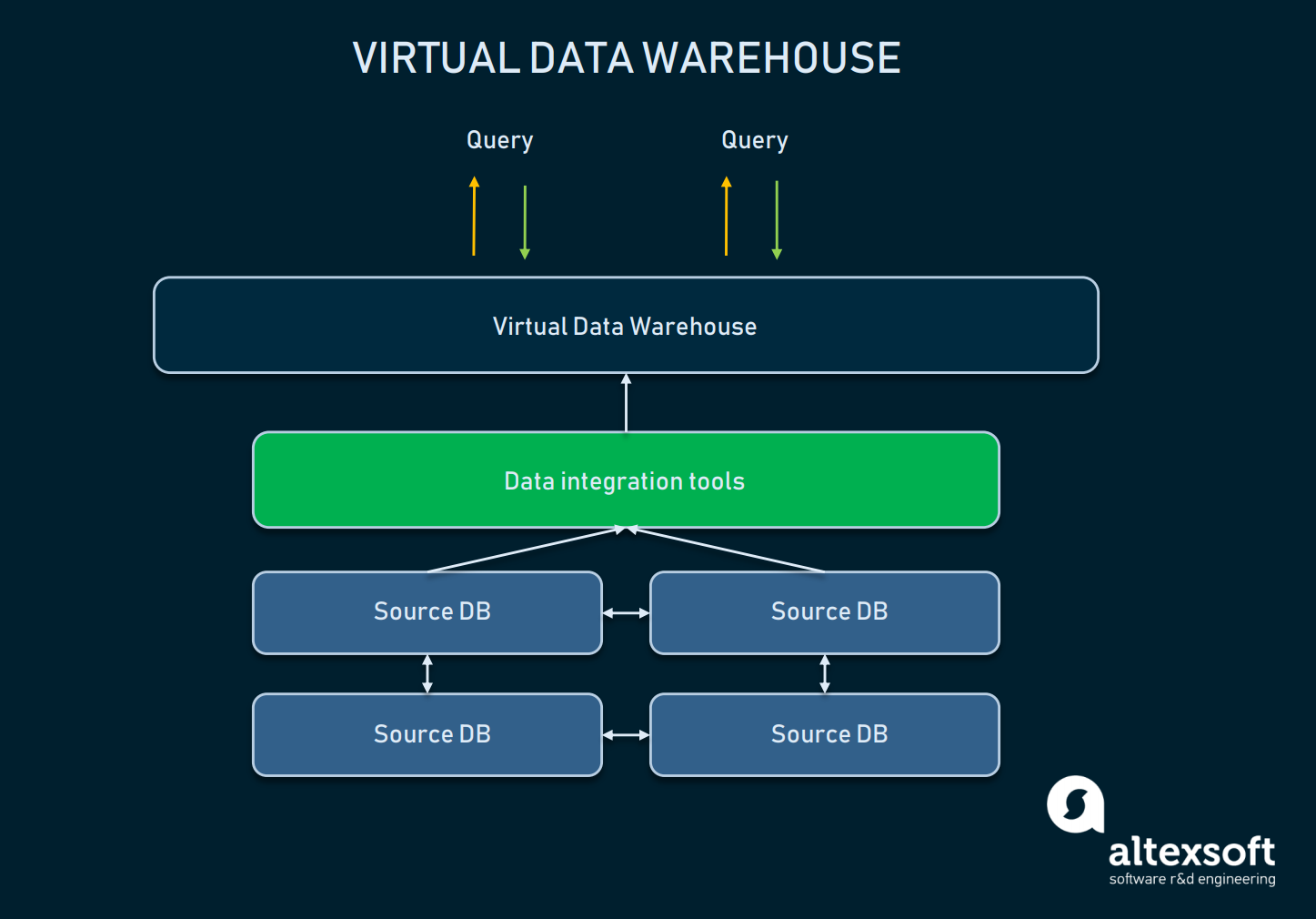
A virtuális DW és a forrásadatbázisok absztrakciója közötti kapcsolatrendszer
Egy ilyen megközelítés lehetővé teszi a szervezetek számára az egyszerűséget: Az adatok a forrásokban maradhatnak, de az analitikai eszközök segítségével mégis előhívhatók. A virtuális raktárak akkor használhatók, ha nem akarunk az összes mögöttes infrastruktúrával bajlódni, vagy az adatok úgy, ahogy vannak, könnyen kezelhetők. Az ilyen megközelítésnek azonban számos hátránya van:
- A több adatbázis folyamatos szoftver- és hardverkarbantartást és költségeket igényel.
- A virtuális DW-ben tárolt adatokhoz továbbra is szükség van egy transzformációs szoftverre, hogy a végfelhasználók és a jelentési eszközök számára emészthetővé váljanak.
- A bonyolult adatlekérdezések túl sok időt vehetnek igénybe, mivel a szükséges adatokat két külön adatbázisban helyezhetik el.
Mikor érdemes használni: Olyan vállalkozások számára alkalmas, amelyek szabványosított formában rendelkeznek nyers adatokkal, amelyek nem igényelnek összetett elemzést. Azoknak a szervezeteknek is megfelel, amelyek nem használják szisztematikusan a BI-t, vagy csak el akarnak kezdeni vele.
Cloud Data Warehouse
Egy évtizede a felhő/felhőtlen technológiák egyre inkább a szervezeti szintű technológiák felállításának szabványává váltak. A piacon számtalan olyan szolgáltatót talál, amelyek raktározást kínálnak szolgáltatásként. Hogy csak néhányat említsünk:
- Amazon Redshift/ Árak oldal
- IBM Db2/ Árak oldal
- Google BigQuery/ Árak oldal
- Snowflake/ Árak oldal
- Microsoft SQL Data Warehouse/ Árak oldal
A felsorolt szolgáltatók mindegyike teljesen menedzselt szolgáltatást kínál, skálázható raktározást BI-eszközeik részeként, vagy önálló szolgáltatásként az EDW-re összpontosítanak, mint a Snowflake. Ebben az esetben a felhőalapú raktárarchitektúra ugyanazokkal az előnyökkel rendelkezik, mint bármely más felhőalapú szolgáltatás. Az infrastruktúráját Ön helyett tartják fenn, ami azt jelenti, hogy nem kell saját szervereket, adatbázisokat és eszközöket létrehoznia a kezeléséhez. Egy ilyen szolgáltatás ára a szükséges memória mennyiségétől és a lekérdezéshez szükséges számítási képességek mennyiségétől függ.
Az egyetlen szempont, ami miatt aggódhat a felhőalapú raktárplatformmal kapcsolatban, az az adatbiztonság. Az Ön üzleti adatai érzékeny dolgok. Ezért szeretné ellenőrizni, hogy az Ön által kiválasztott szállítóban megbízhat-e a jogsértések elkerülése érdekében. Ez nem feltétlenül jelenti azt, hogy egy helyszíni raktár biztonságosabb, de ebben az esetben az adatok biztonsága az Ön kezében van.
Mikor használja: A felhőplatformok kiváló választás bármilyen méretű szervezet számára. Ha Önnek mindenre szüksége van, beleértve a menedzselt adatintegrációt, a DW karbantartását és a BI-támogatást.
Enterprise Data Warehouse Architecture
Míg számos olyan architektúrális megközelítés létezik, amely így vagy úgy bővíti a raktár képességeit, mi a leglényegesebbekre fogunk koncentrálni. Anélkül, hogy túl sok technikai részletbe merülnénk, az egész adatvezetés három rétegre osztható:
- A nyers adatok rétege (adatforrások)
- A raktár és ökoszisztémája
- A felhasználói felület (analitikai eszközök)
Az adatok kinyerésével, átalakításával és raktárba töltésével kapcsolatos eszközrendszer az ETL néven ismert eszközök külön kategóriája. Szintén az ETL fogalomkörébe tartoznak az adatintegrációs eszközök, amelyek manipulációkat végeznek az adatokkal, mielőtt azok a raktárba kerülnének. Ezek az eszközök a nyers adatréteg és a raktár között működnek.
Az adatok raktárba való betöltése után az adatok átalakíthatók is. Tehát a raktárnak szüksége lesz bizonyos funkciókra a tisztításhoz/szabványosításhoz/dimenzionáláshoz. Ezek és más tényezők határozzák meg az architektúra összetettségét. Az EDW architektúrát a növekvő szervezeti igények szempontjából fogjuk megvizsgálni.
Egyszintű architektúra
Mivel az adatintegráció jól konfigurált, kiválaszthatjuk az adattárházunkat. A legtöbb esetben az adattárház egy relációs adatbázis modulokkal, amelyek lehetővé teszik a többdimenziós adatokat, vagy olyan, amely a könnyebb hozzáférés érdekében képes elkülöníteni bizonyos tartományspecifikus információkat. A legprimitívebb formájában az adattárház csak egyszintű architektúrával rendelkezhet.
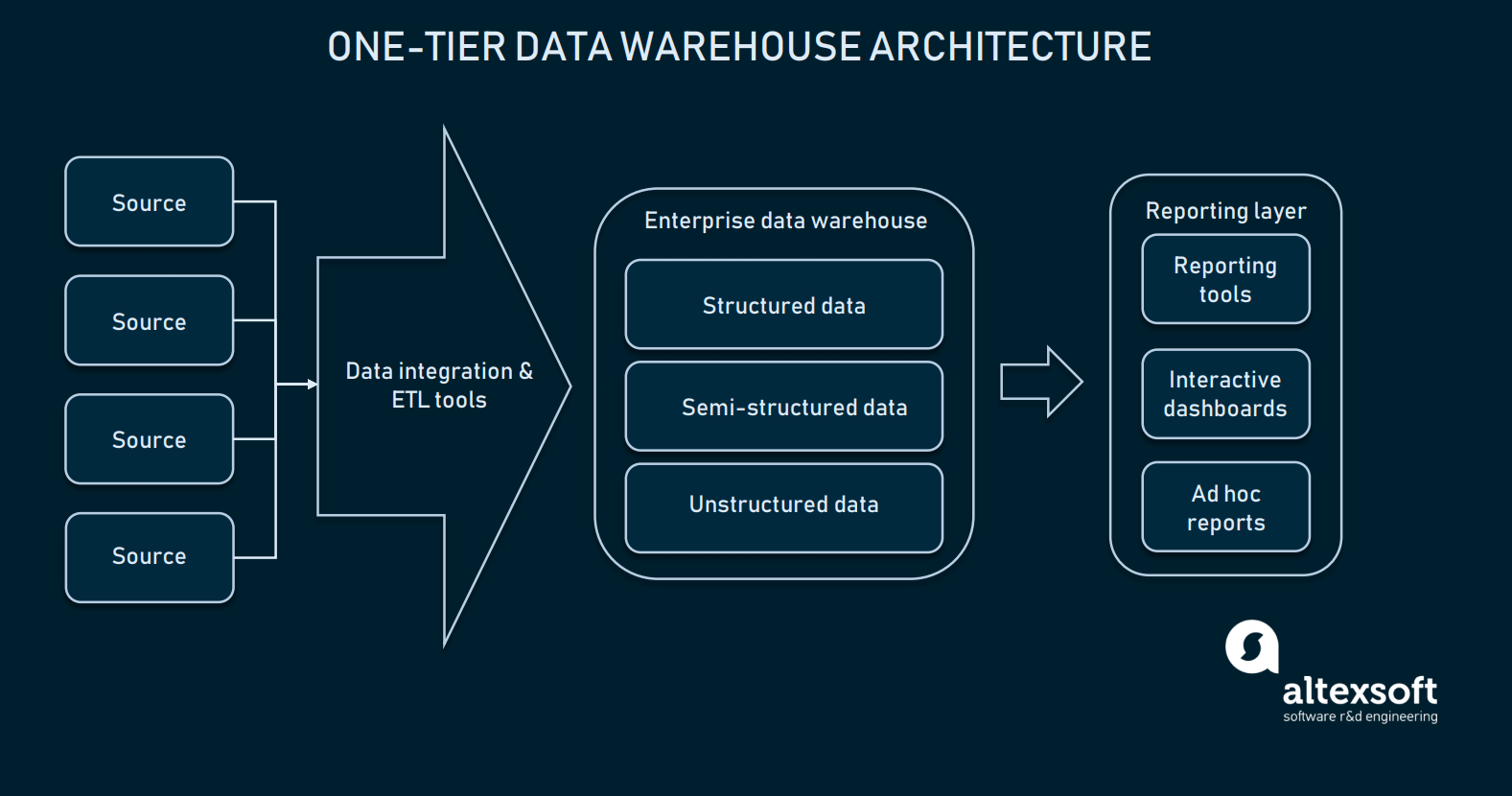
A jelentési réteg közvetlenül kapcsolódik az EDW teljes adatbázisához
Az EDW egyszintű architektúrája azt jelenti, hogy az adatbázis közvetlenül kapcsolódik az analitikai felületekkel, ahol a végfelhasználó lekérdezéseket végezhet. Az EDW és az analitikai eszközök közötti közvetlen kapcsolat beállítása számos kihívással jár:
- Hagyományosan 100 GB adatmennyiségtől kezdve raktárnak tekinthetjük a tárolót. A közvetlen munka vele rendezetlen lekérdezési eredményeket, valamint alacsony feldolgozási sebességet eredményezhet.
- Az adatok lekérdezése közvetlenül a DW-ből pontos bevitelt igényelhet, hogy a rendszer képes legyen kiszűrni a nem szükséges adatokat. Ami kissé megnehezíti a prezentációs eszközökkel való bánásmódot.
- Korlátozott rugalmasság/analitikai képességek léteznek.
Az egyszintű architektúra emellett bizonyos korlátokat szab a jelentések összetettségének. Az ilyen megközelítést a lassúsága és kiszámíthatatlansága miatt ritkán alkalmazzák nagyméretű adatplatformok esetében. A fejlett adatlekérdezések elvégzéséhez a raktár kibővíthető alacsony szintű példányokkal, amelyek megkönnyítik az adatokhoz való hozzáférést.
Kétszintű architektúra (data mart réteg)
A kétszintű architektúrában a felhasználói felület és az EDW közé egy data mart szint kerül. Az adattároló egy olyan alacsony szintű tároló, amely tartományspecifikus információkat tartalmaz. Egyszerűen fogalmazva, ez egy másik, kisebb méretű adatbázis, amely az EDW-t az értékesítési/üzemeltetési részlegek, a marketing stb. számára dedikált információkkal bővíti ki.
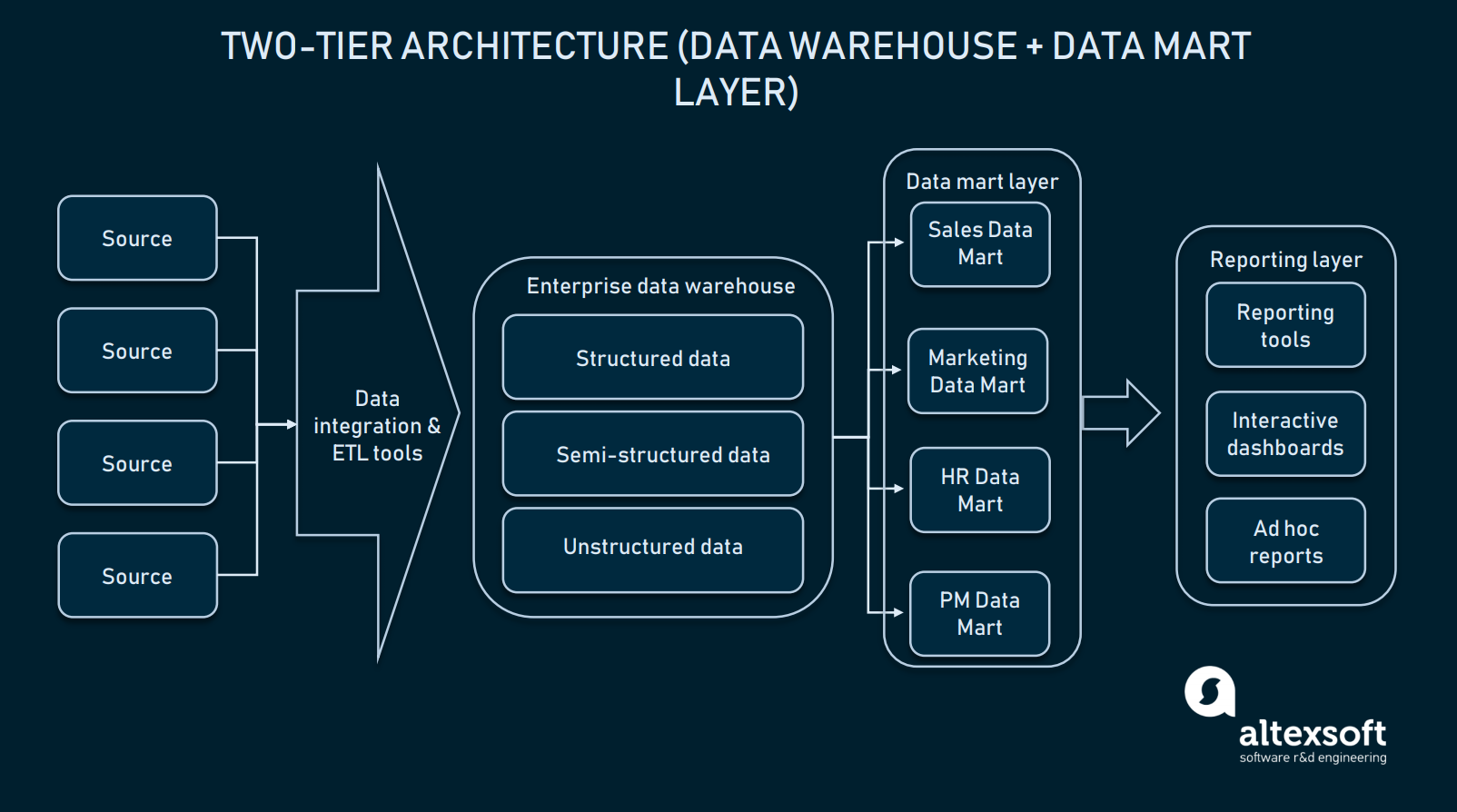
A kétszintű architektúrában az EDW-t adatmárkákkal bővítik ki, hogy tartományspecifikus adatokat szolgáltasson
A data mart réteg létrehozása további erőforrásokat igényel a hardver létrehozásához és ezen adatbázisok integrálásához az adatplatform többi részével. De egy ilyen megközelítés megoldja a lekérdezéssel kapcsolatos problémát: Minden részleg könnyebben hozzáfér a szükséges adatokhoz, mivel egy adott mart csak a terület-specifikus információkat tartalmazza. Ezenkívül az adatmárkák korlátozzák a végfelhasználók hozzáférését az adatokhoz, így az EDW biztonságosabbá válik.
Háromszintű architektúra (Online analitikus feldolgozás)
Az adatmárka réteg tetején a vállalatok online analitikus feldolgozási (OLAP) kockákat is használnak. Az OLAP-kocka az adatbázisok egy speciális típusa, amely több dimenzióból származó adatokat reprezentál. Míg a relációs adatbázisok csak két dimenzióban reprezentálják az adatokat (gondoljunk csak az Excelre vagy a Google Sheetsre), az OLAP lehetővé teszi az adatok több dimenzióban történő összeállítását és a dimenziók közötti mozgást.
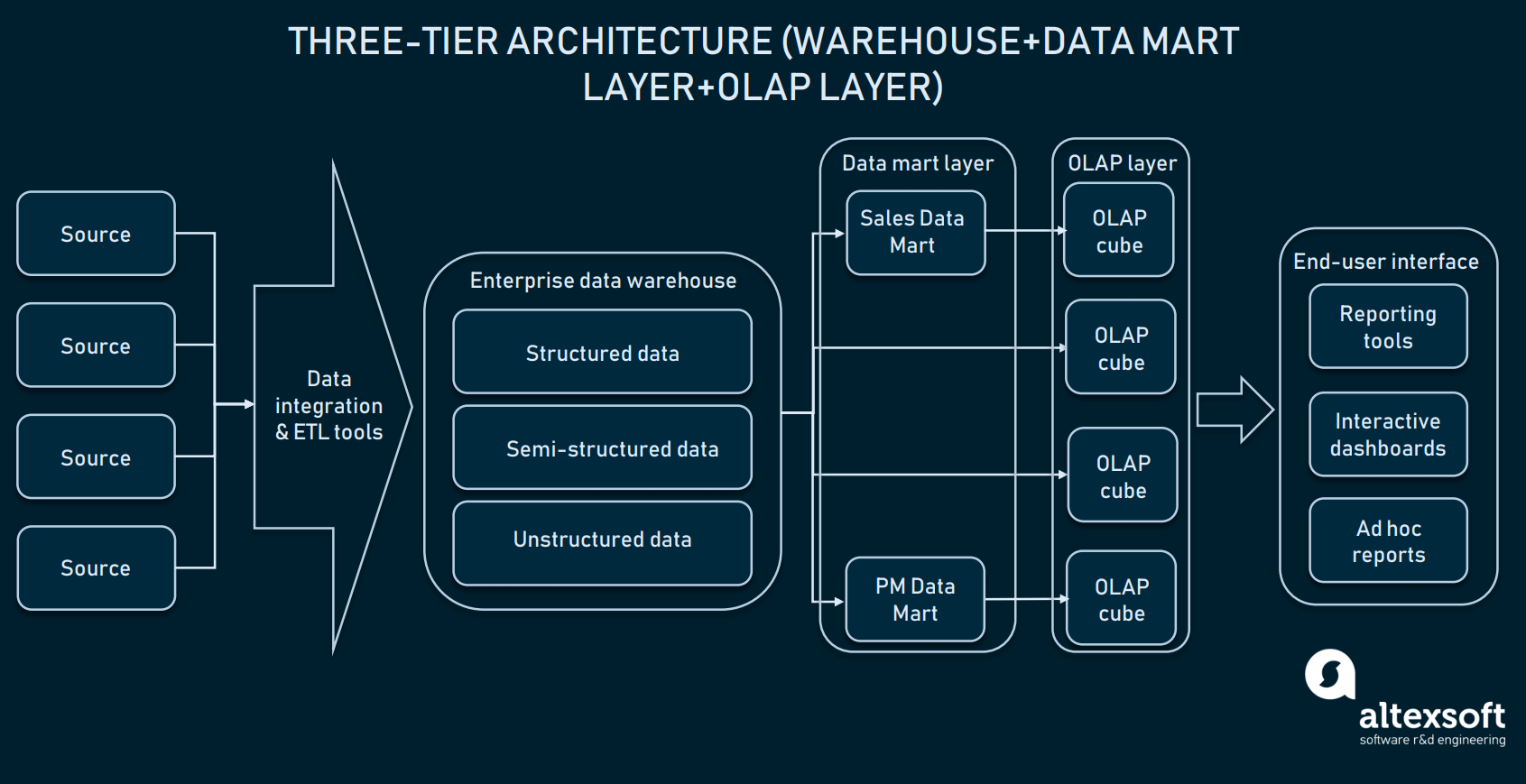
Az OLAP kockák rétege az információkat elosztott adatmárkákból vagy közvetlenül az EDW-ből
Ezt elég nehéz szavakkal elmagyarázni, ezért nézzük meg ezt a praktikus példát, hogyan nézhet ki egy kocka.
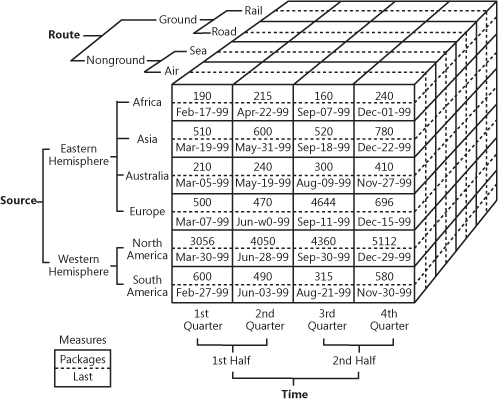
OLAP kocka, amely többdimenziós értékesítési adatokat mutat be
Forrás: oreilly.com
Amint látható, a kocka dimenziókat ad az adatokhoz. Úgy gondolhat rá, mint több, egymással kombinált Excel-táblára. A kocka eleje a szokásos kétdimenziós táblázat, ahol a régió (Afrika, Ázsia stb.) függőlegesen van megadva, míg vízszintesen az eladási számok és a dátumok vannak felírva. A varázslat akkor kezdődik, amikor megnézzük a kocka felső oldalát, ahol az eladások útvonalak szerint vannak szegmentálva, az alsó pedig az időszakot adja meg. Ezt nevezzük többdimenziós adatnak.
Az OLAP üzleti értéke az, hogy lehetővé teszi a felhasználók számára az adatok felszeletelését és feldarabolását részletes jelentések összeállításához. Mindaddig, amíg a kockák a raktárakkal való együttműködésre optimalizáltak, mind közvetlenül egy EDW-vel együtt használhatóak, hogy hozzáférést biztosítsanak az összes vállalati adathoz, vagy külön-külön az egyes adatmartokkal. Ami a megvalósítást illeti, szinte minden raktárszolgáltató kínál OLAP-ot szolgáltatásként. Példaként nézze meg a Microsoft dokumentációját az OLAP-ajánlatukról.
Ezzel a ponttal egy EDW magas szintű, a szervezeti igényekre alkalmazott kialakítását tárgyaltuk. Most le fogunk fúródni a technikai összetevőkre, amelyeket egy raktár tartalmazhat.
Adattárház vs. Adattó vs. Data Lake vs. Data Mart
Az adattárolási architektúráról szólva meg kell említenünk olyan lehetőségeket, mint a raktár helyett egy data mart vagy egy data lake használata. Gyakran összemossák őket, ezért részletezzük a definíciókat.
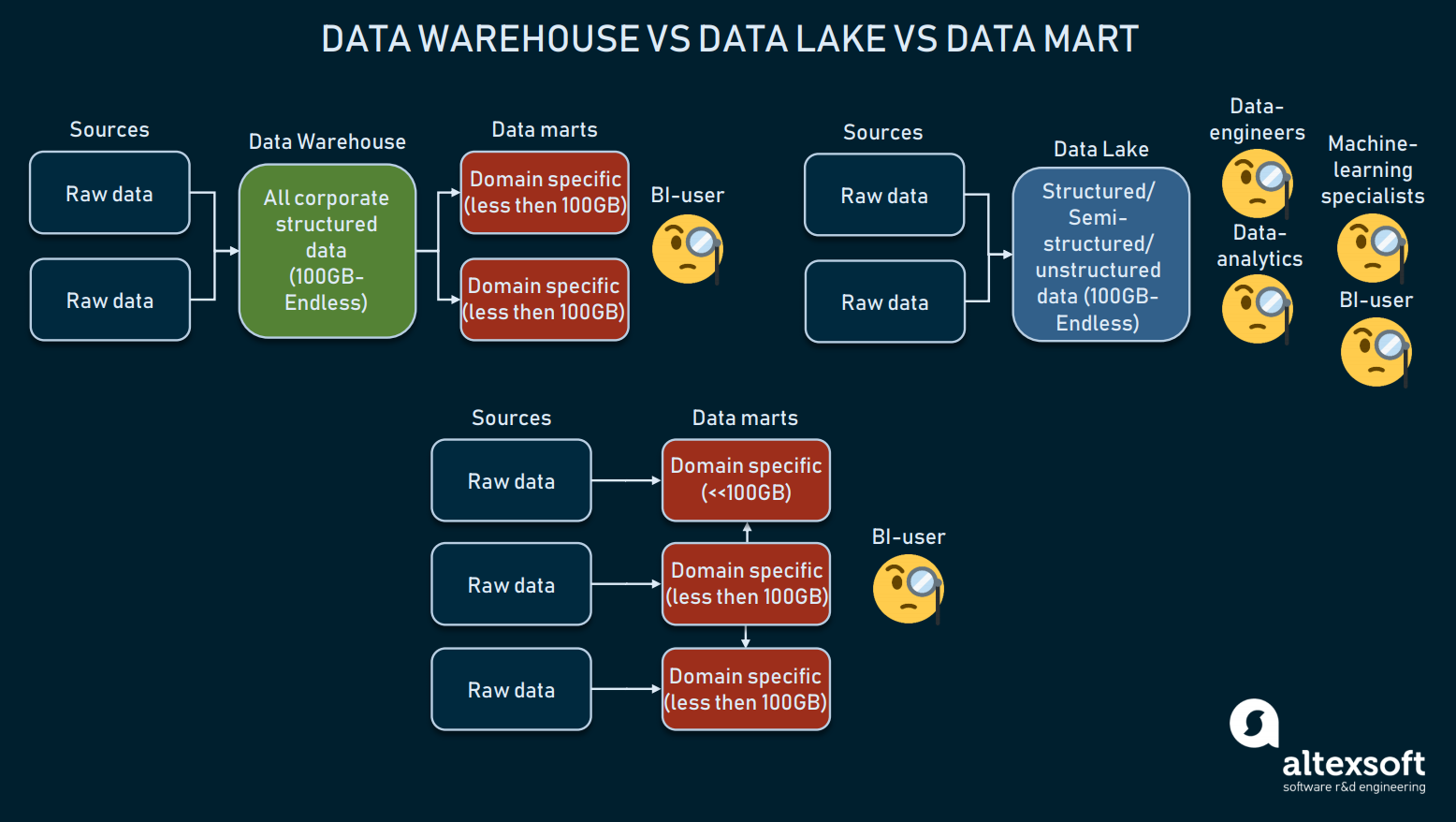
Három adattárolási forma összehasonlítása
Az adattárházak célja a strukturált adatok tárolása, hogy a lekérdező eszközök és a végfelhasználók átfogó eredményeket kapjanak. A többnyire BI-hez használt raktárak mérete általában 100 GB és a végtelen között változik.
Az adattavak viszont többnyire nyers vagy vegyes adatok tárolására szolgálnak. Ezeket gyakran gépi tanulás, big data vagy adatbányászat céljára használják ki. Az elmúlt néhány évben az adattavakat BI-re használták: a nyers adatokat egy tóba töltik és átalakítják, ami az ETL-folyamat alternatívája. Bár ennek a megközelítésnek megvannak az előnyei és hátrányai, az adattavak túl rendetlenek lehetnek a strukturált adatok eléréséhez.
Aztán ott vannak az adatmárkák, amelyek szintén a DW alternatívájaként használhatók. Az ilyen modellek (mint Kimball modellje) több adatmárta használatát feltételezik az információk tartományok szerinti elosztására és egymással való összekapcsolására. A kis méretük (általában 100 GB-nál kisebb) miatt azonban az adatmárkákat a vállalatok aligha tudják használni. Az adatmárkákat gyakrabban arra használják, hogy egy nagy DW-t több működőképesre szegmentáljanak.
Enterprise Data Warehouse Components
Egy adattárházi platform felállításához számos eszközt használnak. Legtöbbjüket már említettük, beleértve magát a raktárat is. Lássuk tehát madártávlatból az egyes komponensek célját és funkcióit.
Források. Ez egyszerű, az adatbázisok, ahol a nyers adatokat tárolják.
Extract, Transform, Load (ETL) vagy Extract, Load, Transform (ELT) réteg. Ezek azok az eszközök, amelyek a forrásadatokkal való tényleges kapcsolatot, azok kinyerését és betöltését végzik arra a helyre, ahol az adatok átalakításra kerülnek. A transzformáció egységesíti az adatformátumot. Az ETL és az ELT megközelítések abban különböznek, hogy az ETL esetében az átalakítás az EDW előtt, egy előkészítő területen történik. Az ELT egy modernebb megközelítés, amely az összes átalakítást egy raktárban végzi.
Staging area. Az ETL esetében a staging area az a hely, ahová az adatokat az EDW előtt betöltik. Itt kerülnek megtisztításra és átalakításra egy adott adatmodellre. A staging area tartalmazhat az adatminőség-kezeléshez szükséges eszközöket is.
DW adatbázis. Az adatok végül betöltődnek a tárolóhelyre. Az ELT-ben itt még szükség lehet némi átalakításra. De ebben a szakaszban minden általános változtatást alkalmaznak, így az adatok betöltődnek a végleges modell(ek)be. Mint említettük, az adattárházak leggyakrabban relációs adatbázisok. A DW magában foglalja az adatbázis-kezelő rendszert és a metaadatok további tárolását is.
Meta-adat modul. Leegyszerűsítve, a metaadatok adatok az adatokról szóló adatok. Ezek azok a magyarázatok, amelyek a felhasználók/adminisztrátorok számára utalást adnak arra, hogy ez az információ milyen témára/tartományra vonatkozik. Ezek az adatok lehetnek technikai metaadatok (pl. eredeti forrás) vagy üzleti metaadatok (pl. értékesítési régió). Az összes meta az EDW egy külön moduljában tárolódik, és egy metaadat-kezelő kezeli.
Beszámoló réteg. Ezek olyan eszközök, amelyek a végfelhasználók számára hozzáférést biztosítanak az adatokhoz. BI-felületnek is nevezik, ez a réteg műszerfalként szolgál az adatok megjelenítésére, jelentések készítésére és különálló információk lehívására.
Végső gondolat
Az adatokat továbbító eszközök láncolatának megismerése segíthet kitalálni, hogy valójában mi felel meg az adatplatform követelményeinek. Egy adattárház felállításának megtervezése évekig tartó tervezést és tesztelést igényelhet, mivel az a legalapvetőbb formában is kiterjedt.
Vállalkozóként összezavarodhat a lehetőségek és az alkalmazott technológiák sokasága miatt, ezért elengedhetetlen, hogy konzultáljon a raktározás, az ETL és a BI területén dolgozó szakértőkkel. Míg a szakértők segíthetnek a technikai aspektusban, az üzleti cél meghatározásához beszéljen azokkal, akik a tényleges adatokat a munkájuk során használni fogják.